Muthén & Muthén, Los Angeles, California 90066, USA.
Psychol Methods. 2011 Mar;16(1):17-33. doi: 10.1037/a0022634.
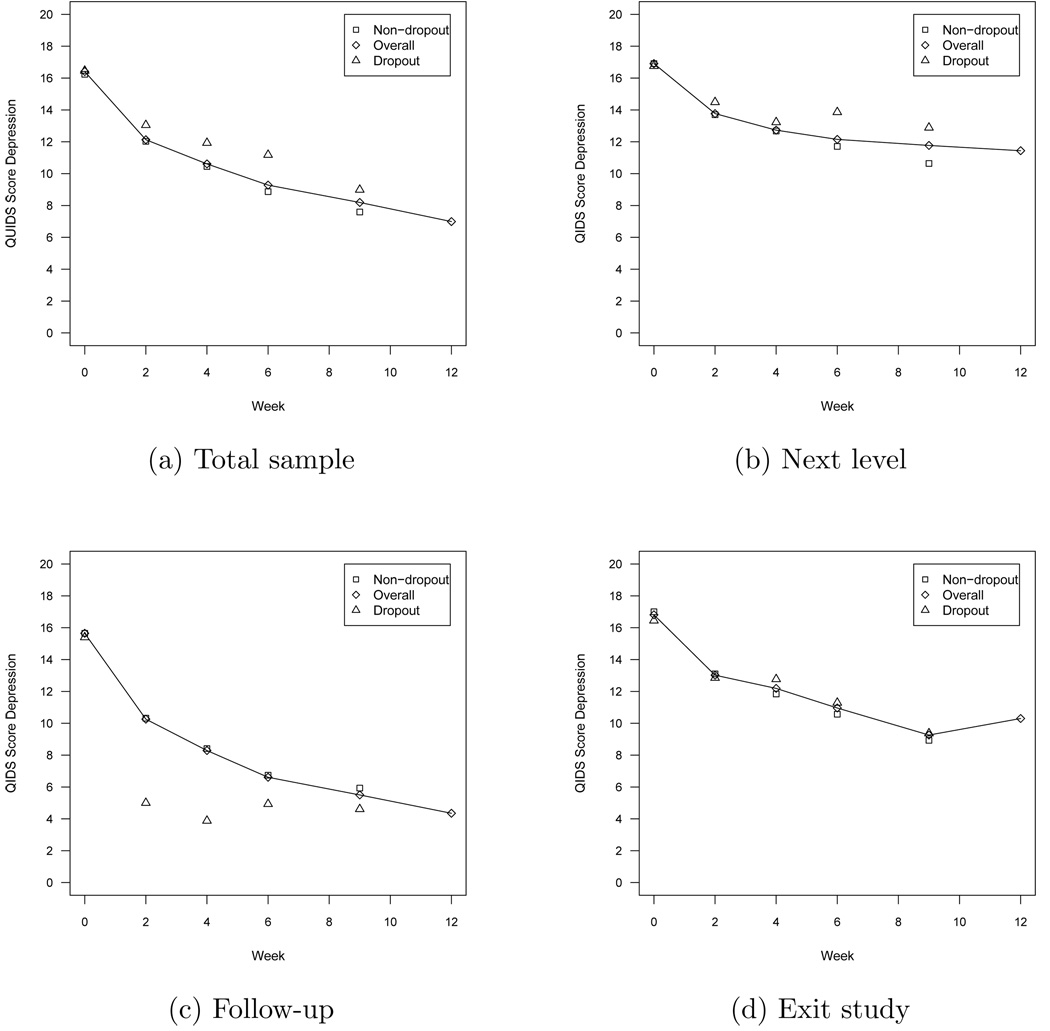
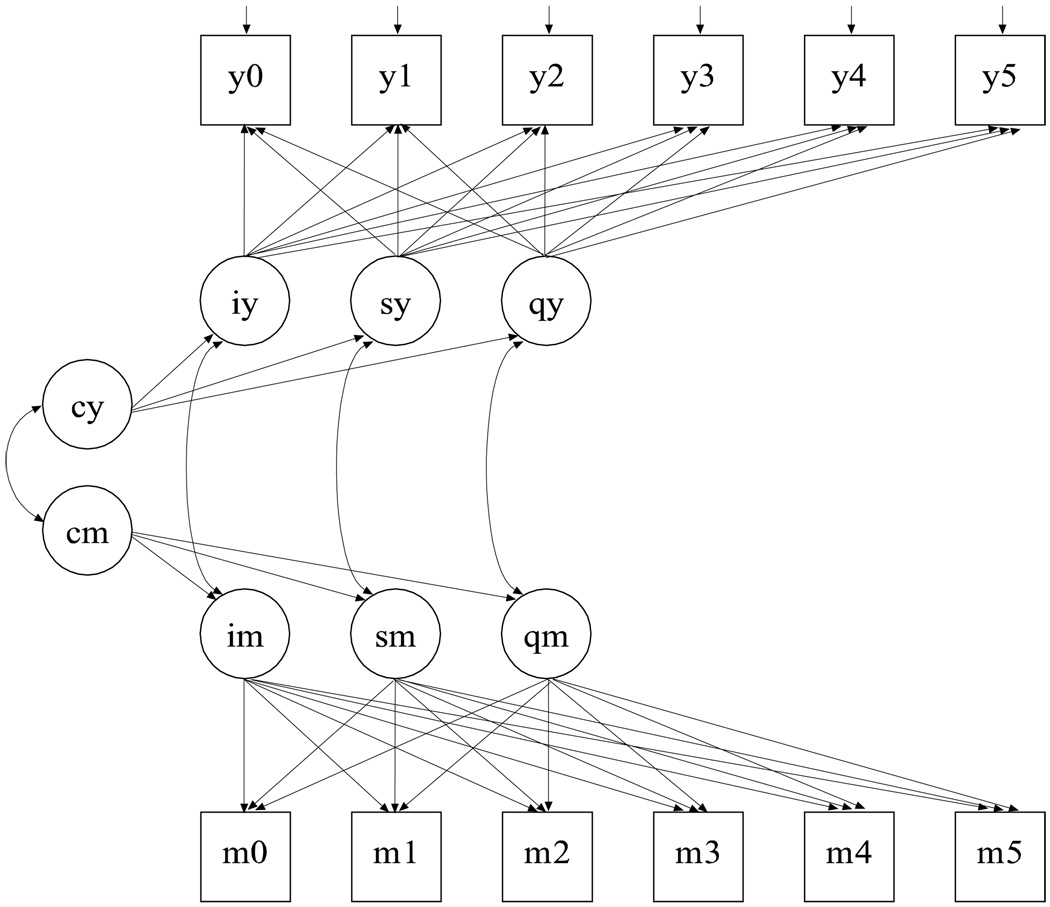
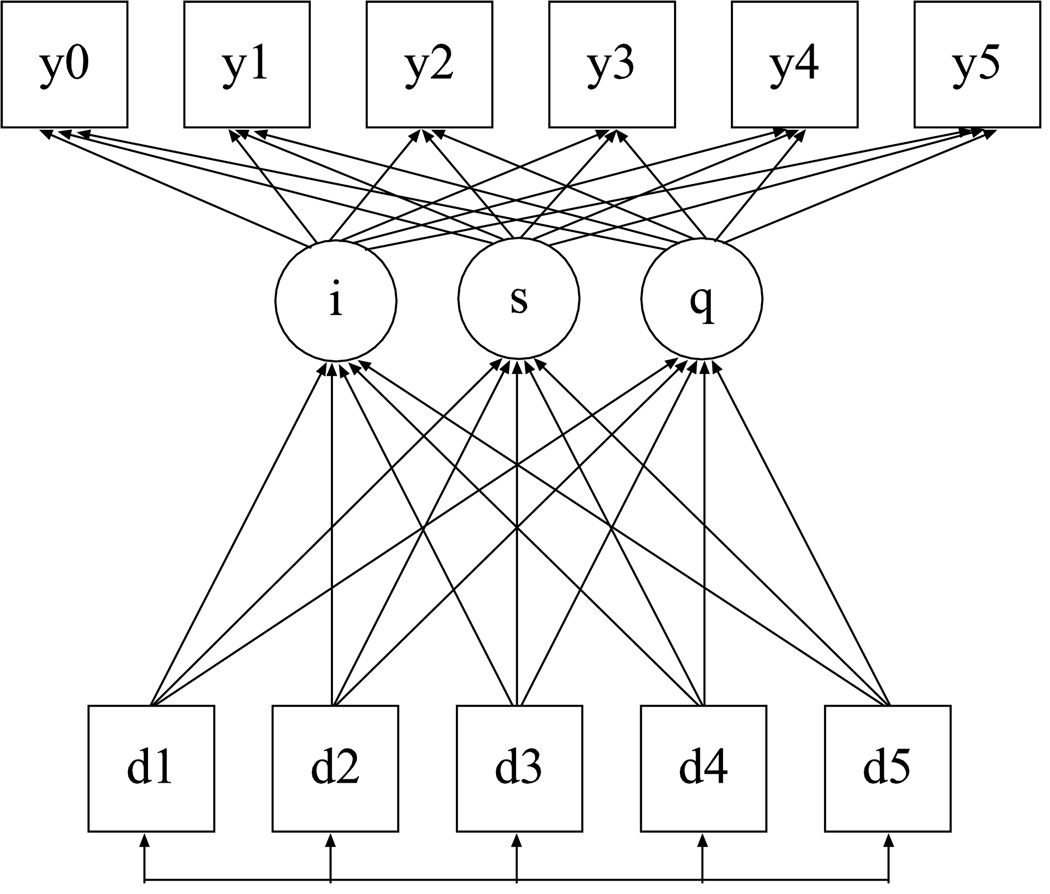
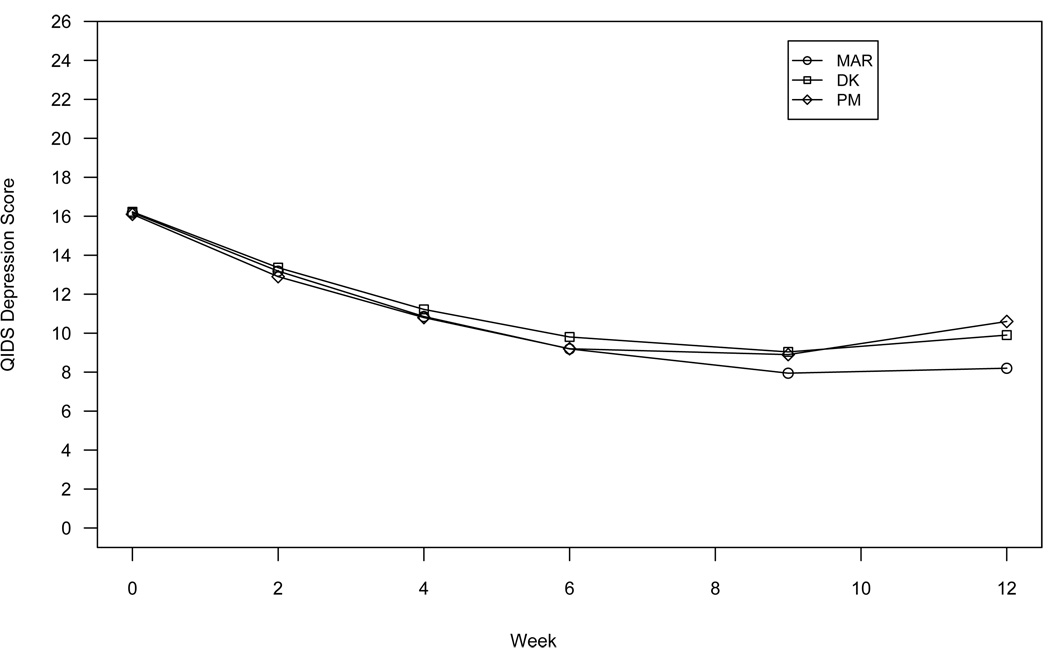
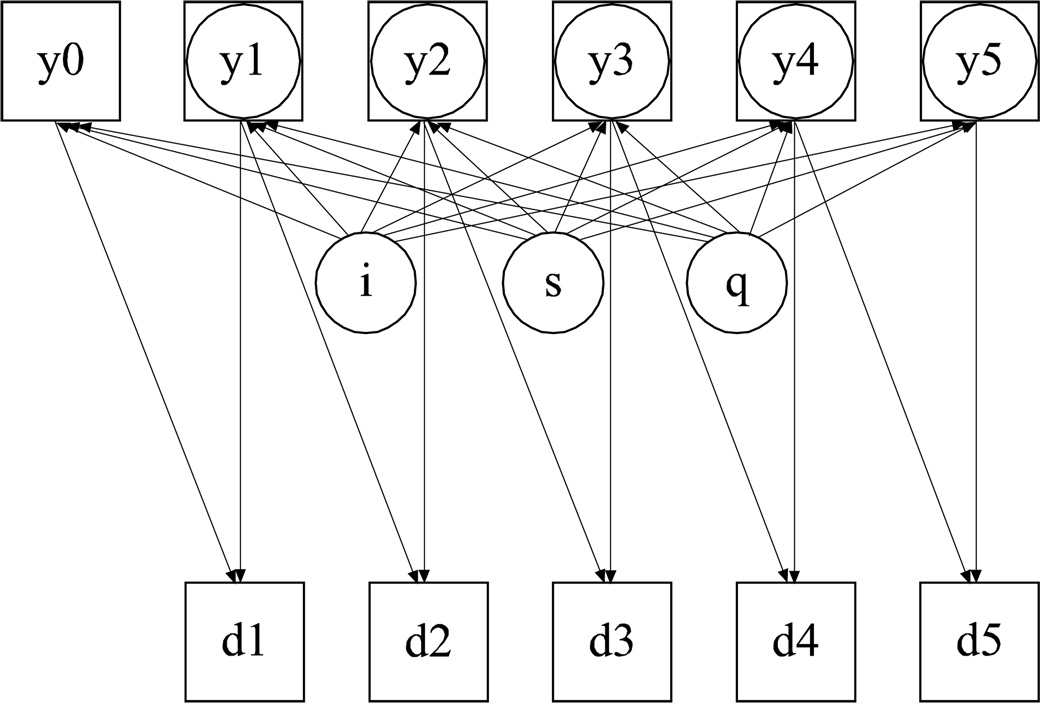
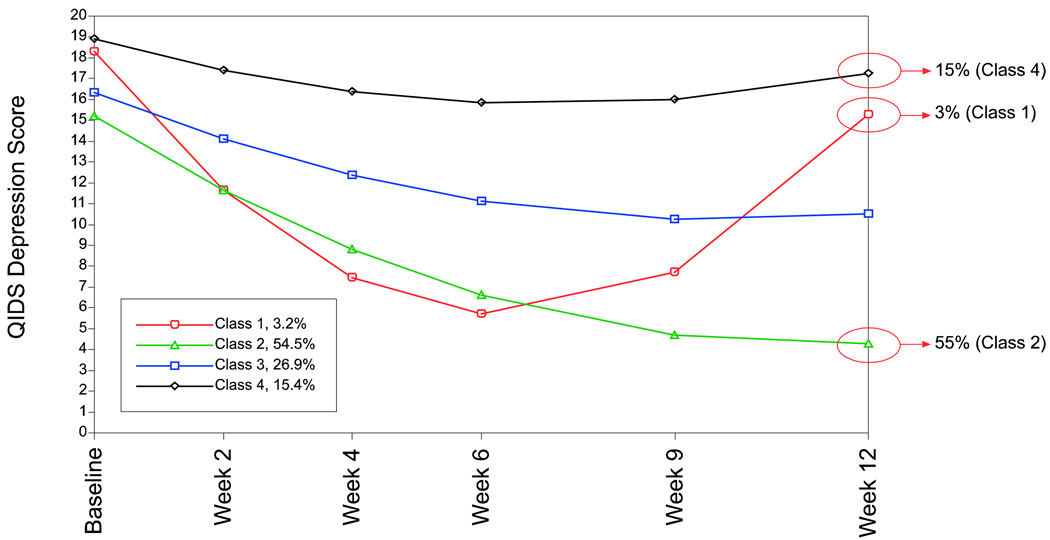
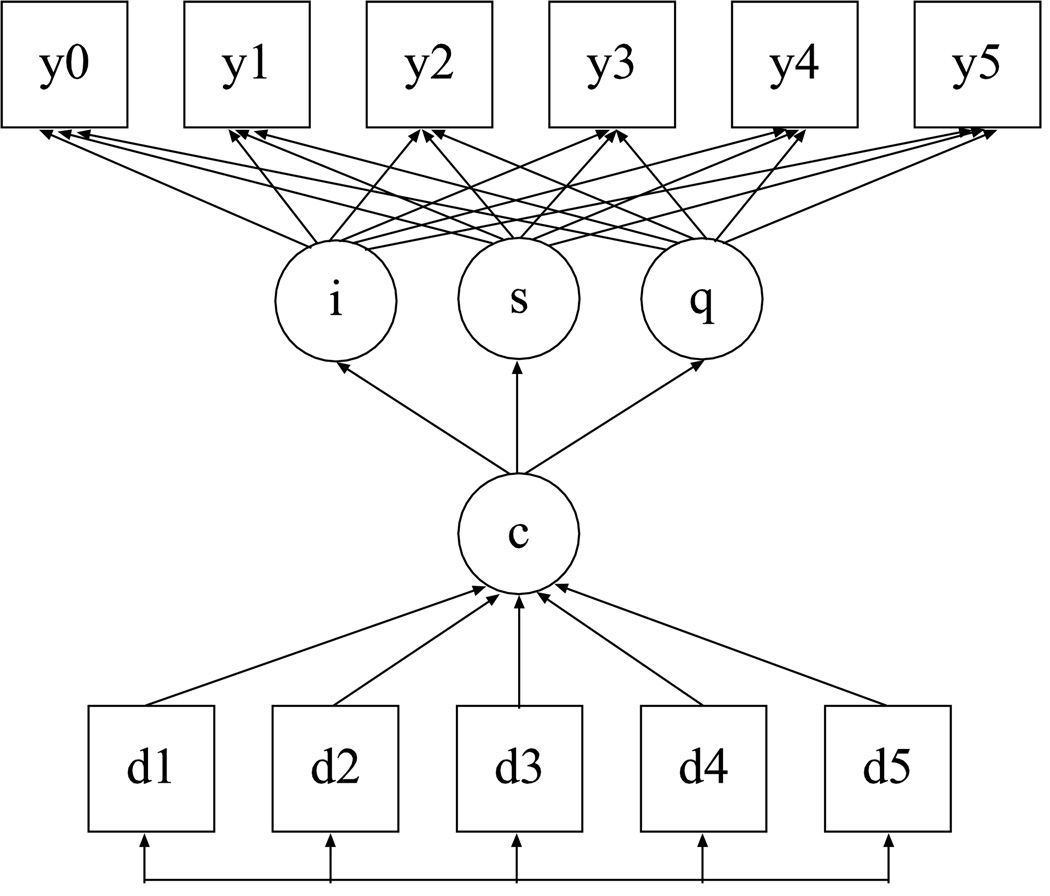
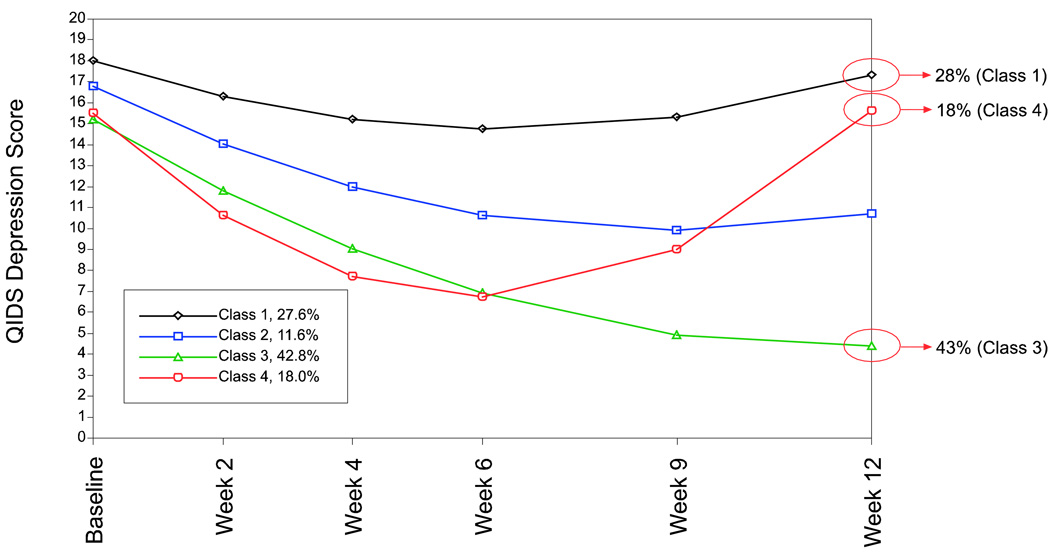
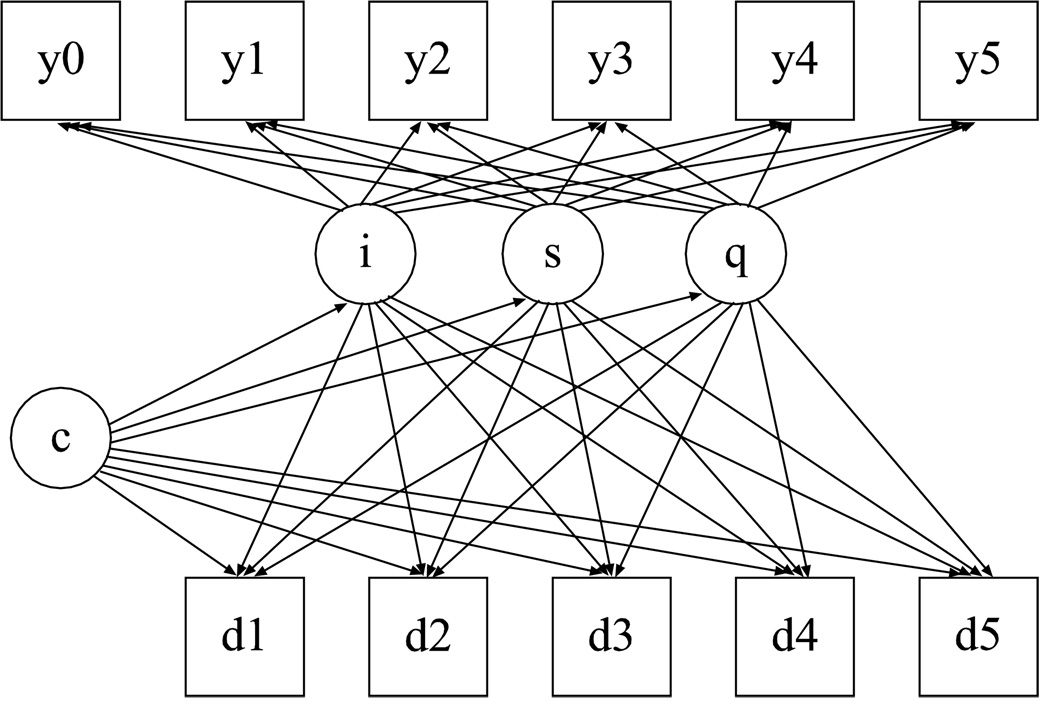
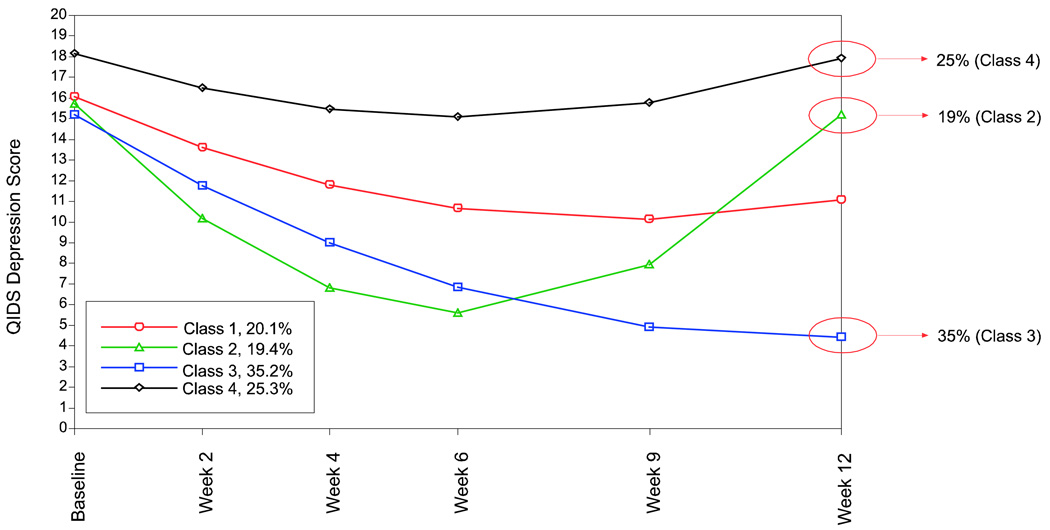
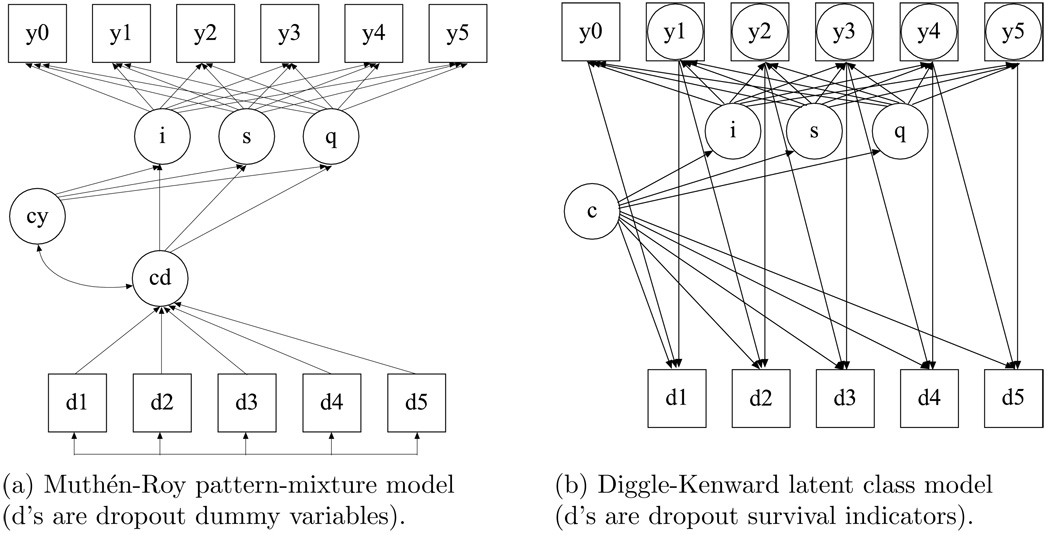
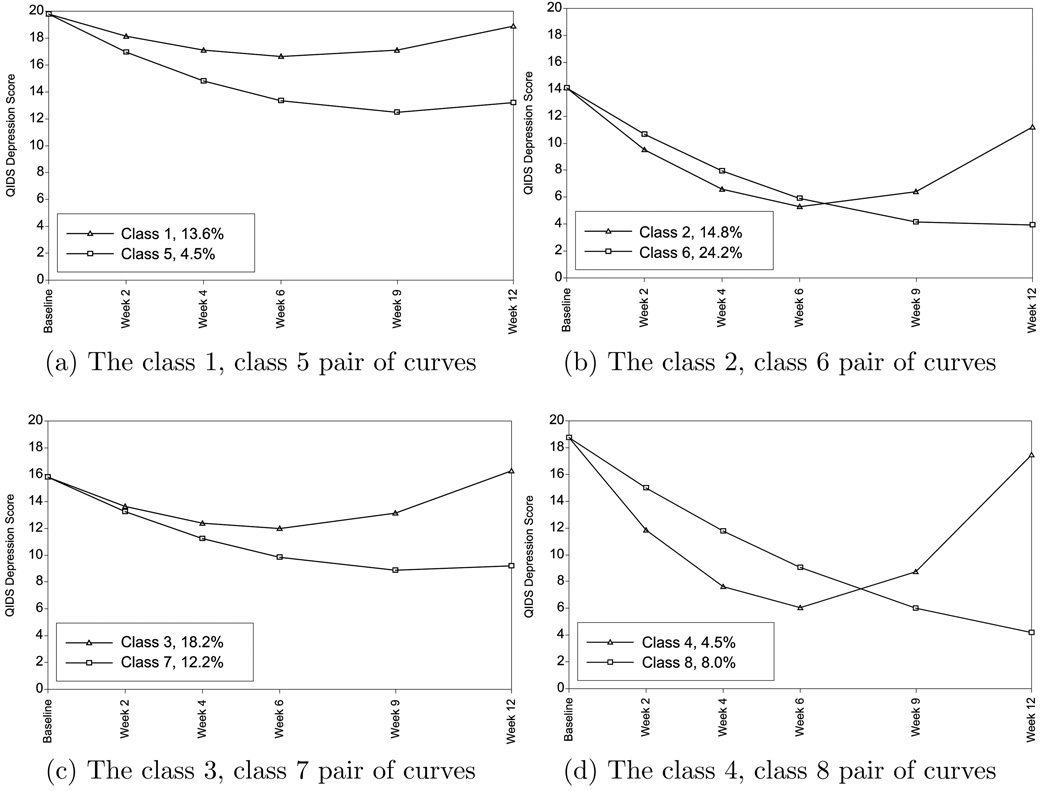
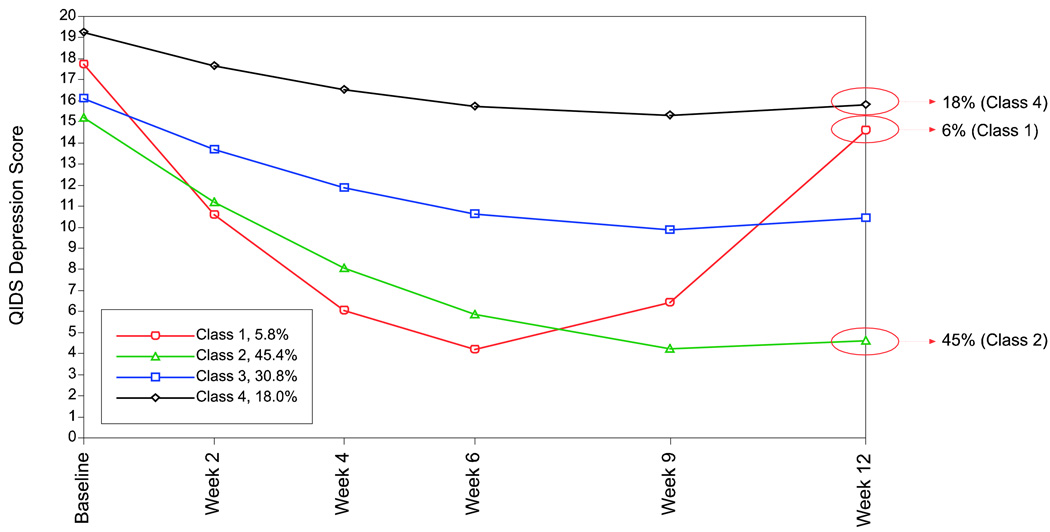
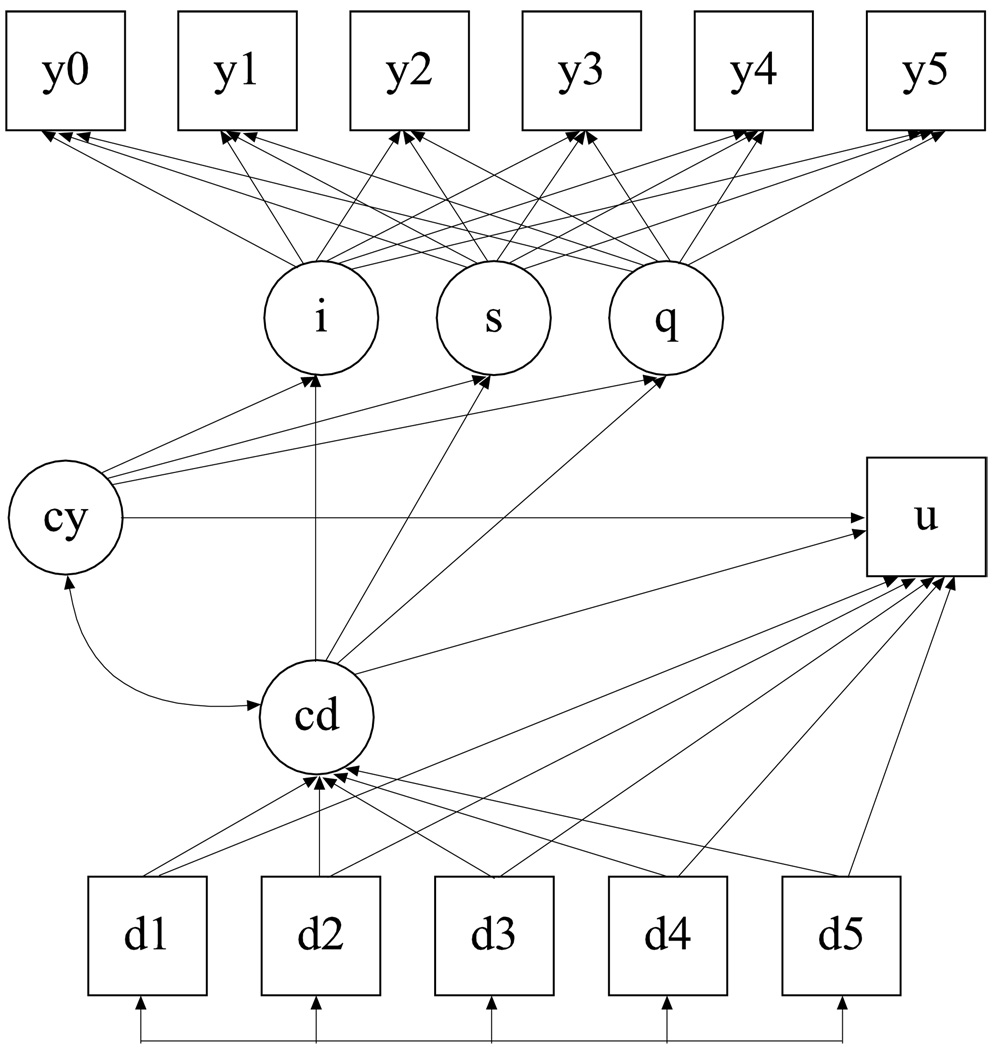
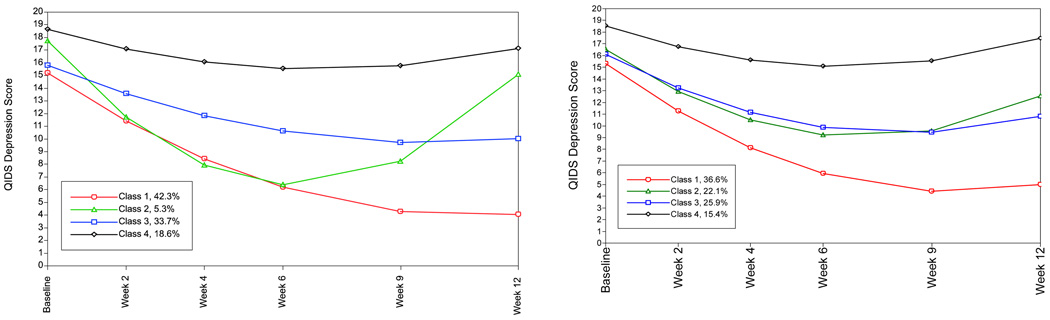
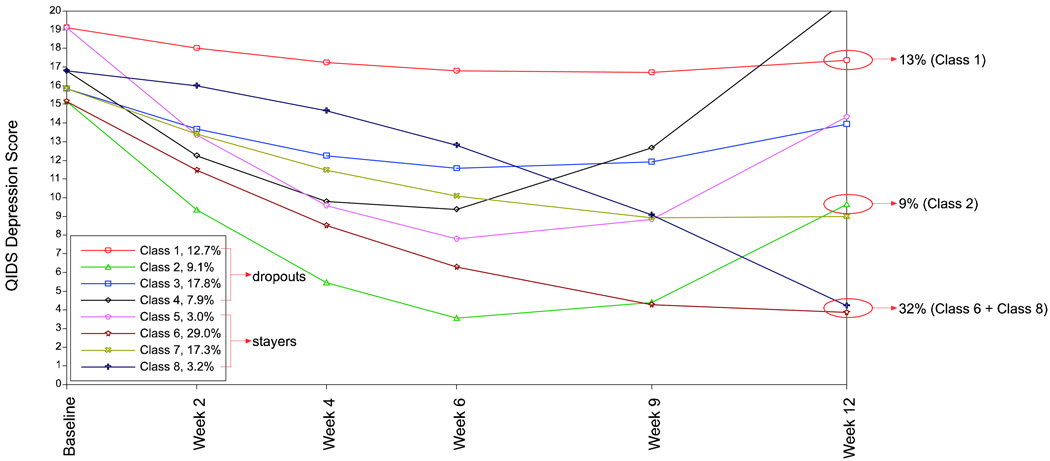
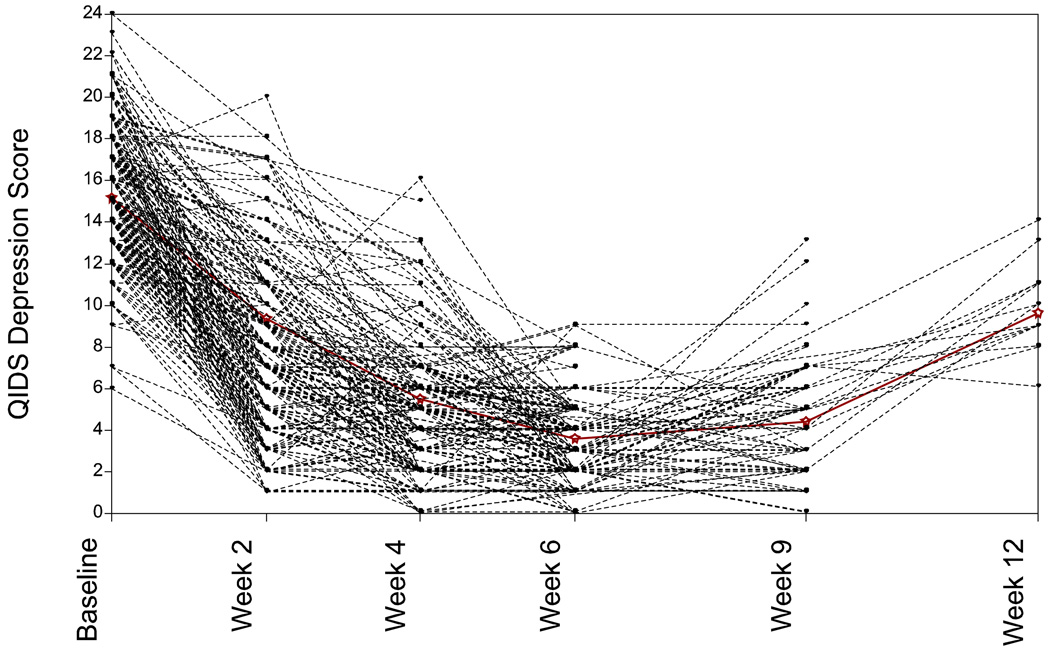
This article uses a general latent variable framework to study a series of models for nonignorable missingness due to dropout. Nonignorable missing data modeling acknowledges that missingness may depend not only on covariates and observed outcomes at previous time points as with the standard missing at random assumption, but also on latent variables such as values that would have been observed (missing outcomes), developmental trends (growth factors), and qualitatively different types of development (latent trajectory classes). These alternative predictors of missing data can be explored in a general latent variable framework with the Mplus program. A flexible new model uses an extended pattern-mixture approach where missingness is a function of latent dropout classes in combination with growth mixture modeling. A new selection model not only allows an influence of the outcomes on missingness but allows this influence to vary across classes. Model selection is discussed. The missing data models are applied to longitudinal data from the Sequenced Treatment Alternatives to Relieve Depression (STARD) study, the largest antidepressant clinical trial in the United States to date. Despite the importance of this trial, STARD growth model analyses using nonignorable missing data techniques have not been explored until now. The STAR*D data are shown to feature distinct trajectory classes, including a low class corresponding to substantial improvement in depression, a minority class with a U-shaped curve corresponding to transient improvement, and a high class corresponding to no improvement. The analyses provide a new way to assess drug efficiency in the presence of dropout.
本文使用通用潜在变量框架研究了一系列因辍学而导致不可忽略缺失的模型。不可忽略的缺失数据建模承认,缺失不仅可能取决于标准随机缺失假设中之前时间点的协变量和观测结果,还可能取决于潜在变量,如原本会观测到的值(缺失结果)、发展趋势(增长因素)和定性不同的发展类型(潜在轨迹类别)。可以使用 Mplus 程序在通用潜在变量框架中探索这些缺失数据的替代预测因子。一个灵活的新模型使用扩展的模式混合方法,其中缺失是潜在辍学类别的函数,与增长混合建模相结合。新的选择模型不仅允许结果对缺失的影响,而且允许这种影响在类之间变化。讨论了模型选择。将缺失数据模型应用于来自缓解抑郁的序贯治疗替代研究(STARD)的纵向数据,这是迄今为止美国最大的抗抑郁临床试验。尽管该试验很重要,但直到现在,才探索使用不可忽略缺失数据技术对 STARD 增长模型进行分析。STAR*D 数据显示出不同的轨迹类别,包括与抑郁明显改善相对应的低类别、与短暂改善相对应的 U 形曲线相对应的少数类别以及与无改善相对应的高类别。该分析提供了一种在存在辍学的情况下评估药物效率的新方法。