Flora David B, Labrish Cathy, Chalmers R Philip
Department of Psychology, York University Toronto, ON, Canada.
Front Psychol. 2012 Mar 1;3:55. doi: 10.3389/fpsyg.2012.00055. eCollection 2012.
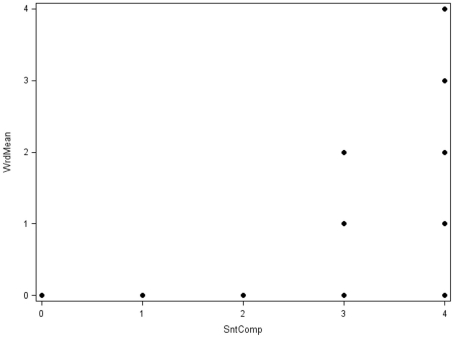
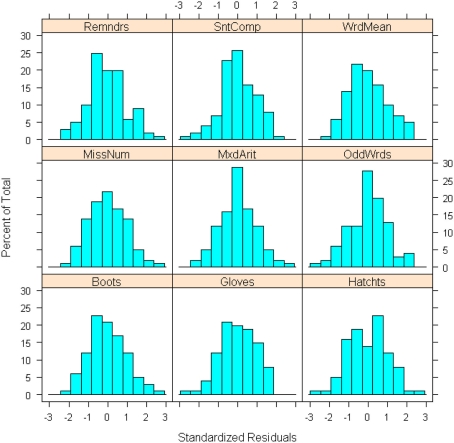
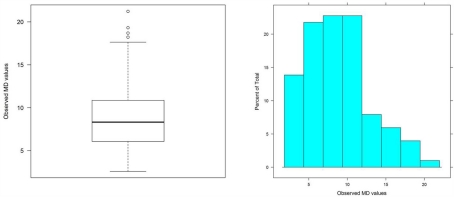
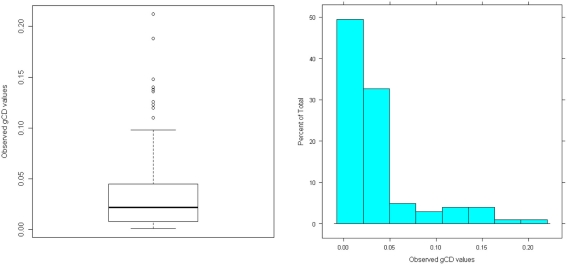
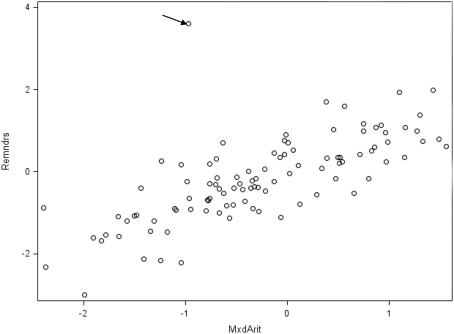
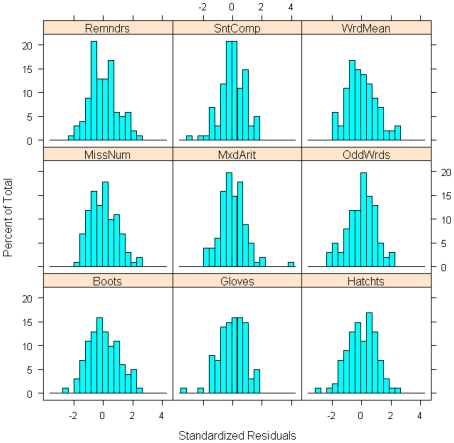
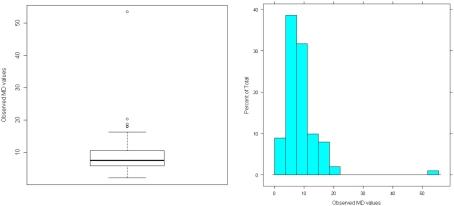
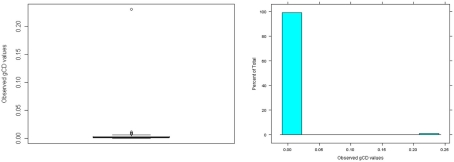
We provide a basic review of the data screening and assumption testing issues relevant to exploratory and confirmatory factor analysis along with practical advice for conducting analyses that are sensitive to these concerns. Historically, factor analysis was developed for explaining the relationships among many continuous test scores, which led to the expression of the common factor model as a multivariate linear regression model with observed, continuous variables serving as dependent variables, and unobserved factors as the independent, explanatory variables. Thus, we begin our paper with a review of the assumptions for the common factor model and data screening issues as they pertain to the factor analysis of continuous observed variables. In particular, we describe how principles from regression diagnostics also apply to factor analysis. Next, because modern applications of factor analysis frequently involve the analysis of the individual items from a single test or questionnaire, an important focus of this paper is the factor analysis of items. Although the traditional linear factor model is well-suited to the analysis of continuously distributed variables, commonly used item types, including Likert-type items, almost always produce dichotomous or ordered categorical variables. We describe how relationships among such items are often not well described by product-moment correlations, which has clear ramifications for the traditional linear factor analysis. An alternative, non-linear factor analysis using polychoric correlations has become more readily available to applied researchers and thus more popular. Consequently, we also review the assumptions and data-screening issues involved in this method. Throughout the paper, we demonstrate these procedures using an historic data set of nine cognitive ability variables.
我们对与探索性和验证性因素分析相关的数据筛选和假设检验问题进行了基本回顾,并提供了一些实用建议,以指导如何进行对这些问题敏感的分析。从历史上看,因素分析是为了解释许多连续测试分数之间的关系而发展起来的,这导致了共同因素模型被表达为一个多元线性回归模型,其中观察到的连续变量作为因变量,未观察到的因素作为独立的解释变量。因此,我们在本文开头回顾了共同因素模型的假设以及与连续观察变量的因素分析相关的数据筛选问题。特别是,我们描述了回归诊断的原理如何也适用于因素分析。接下来,由于因素分析的现代应用经常涉及对来自单一测试或问卷的各个项目进行分析,本文的一个重要重点是项目的因素分析。尽管传统的线性因素模型非常适合于分析连续分布的变量,但常用的项目类型,包括李克特式项目,几乎总是产生二分或有序分类变量。我们描述了此类项目之间的关系通常如何不能很好地用积差相关来描述,这对传统的线性因素分析有明显的影响。一种使用多相关系数的替代非线性因素分析方法已更容易为应用研究人员所使用,因此也更受欢迎。因此,我们还回顾了该方法所涉及的假设和数据筛选问题。在整篇论文中,我们使用一个包含九个认知能力变量的历史数据集来演示这些程序。