School of Computational Sciences, Korea Institute for Advanced Study, Seoul, Korea.
Sci Rep. 2013;3:2197. doi: 10.1038/srep02197.
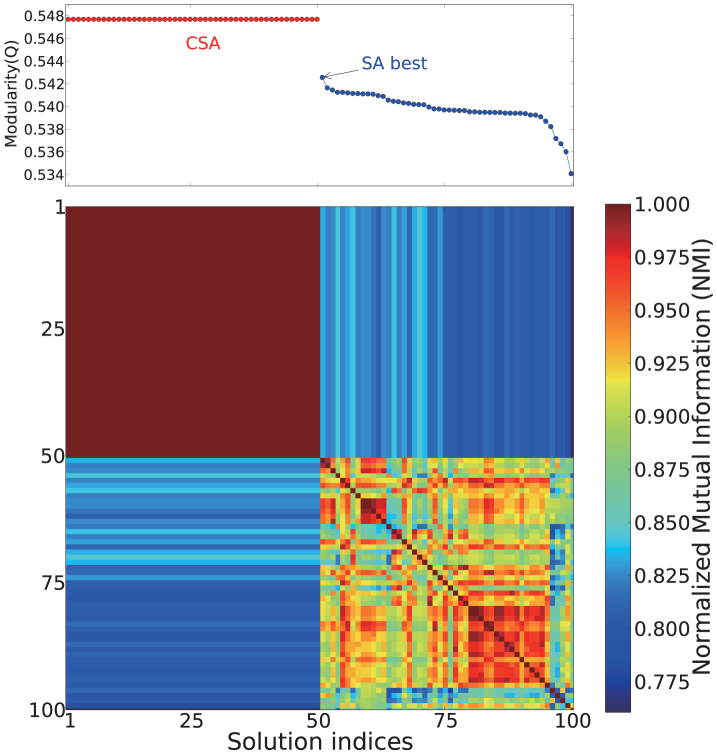
We are overwhelmed by experimental data, and need better ways to understand large interaction datasets. While clustering related nodes in such networks-known as community detection-appears a promising approach, detecting such communities is computationally difficult. Further, how to best use such community information has not been determined. Here, within the context of protein function prediction, we address both issues. First, we apply a novel method that generates improved modularity solutions than the current state of the art. Second, we develop a better method to use this community information to predict proteins' functions. We discuss when and why this community information is important. Our results should be useful for two distinct scientific communities: first, those using various cost functions to detect community structure, where our new optimization approach will improve solutions, and second, those working to extract novel functional information about individual nodes from large interaction datasets.
我们被实验数据淹没了,需要更好的方法来理解大型相互作用数据集。虽然在这样的网络中聚类相关节点(称为社区检测)似乎是一种很有前途的方法,但检测这样的社区在计算上是困难的。此外,如何最好地利用这种社区信息还没有确定。在这里,我们在蛋白质功能预测的背景下,同时解决了这两个问题。首先,我们应用了一种新颖的方法,该方法生成的模块性解决方案比当前的最先进方法有所改进。其次,我们开发了一种更好的方法来利用这种社区信息来预测蛋白质的功能。我们讨论了何时以及为何这种社区信息很重要。我们的结果应该对两个不同的科学社区有用:首先,那些使用各种代价函数来检测社区结构的社区,我们的新优化方法将改进这些社区的结构,其次,那些致力于从大型相互作用数据集中提取单个节点的新功能信息的社区。