Aachen Institute for Advanced Study in Computational Engineering Science (AICES), RWTH Aachen University, Aachen, Germany.
PLoS One. 2013 Jul 23;8(7):e70294. doi: 10.1371/journal.pone.0070294. Print 2013.
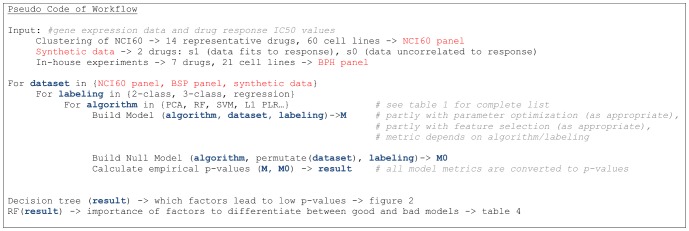
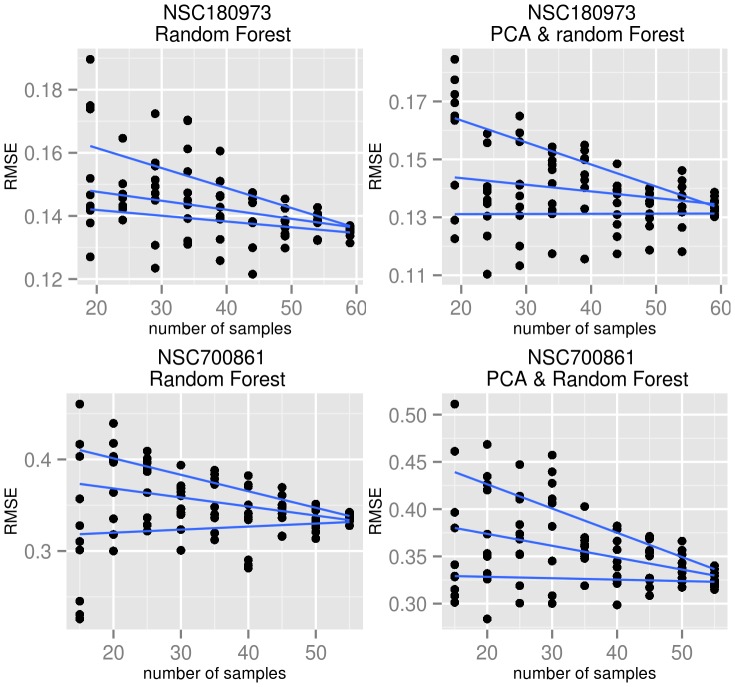
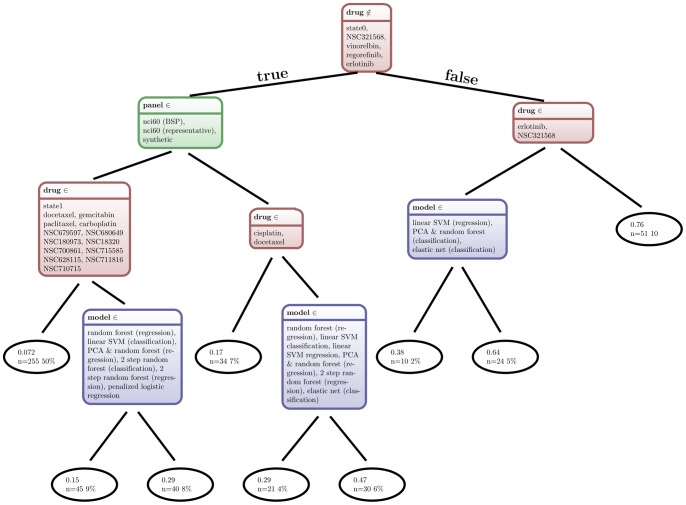
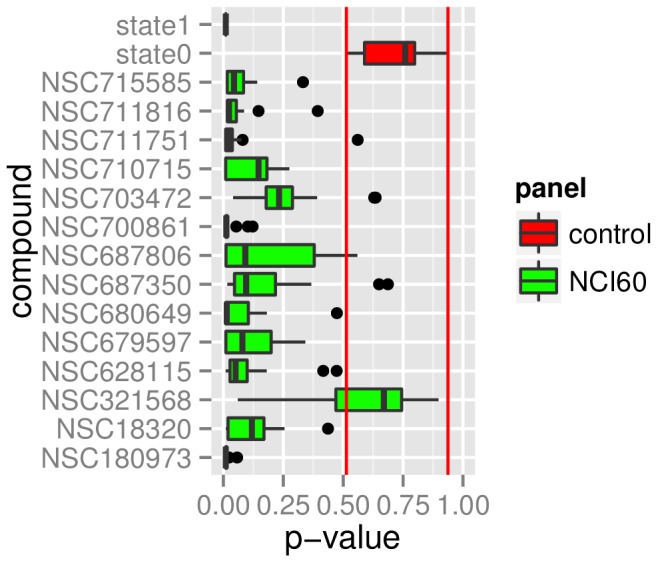
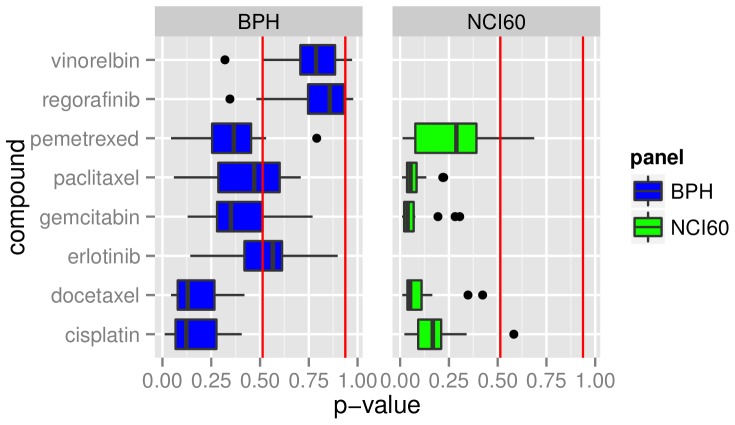
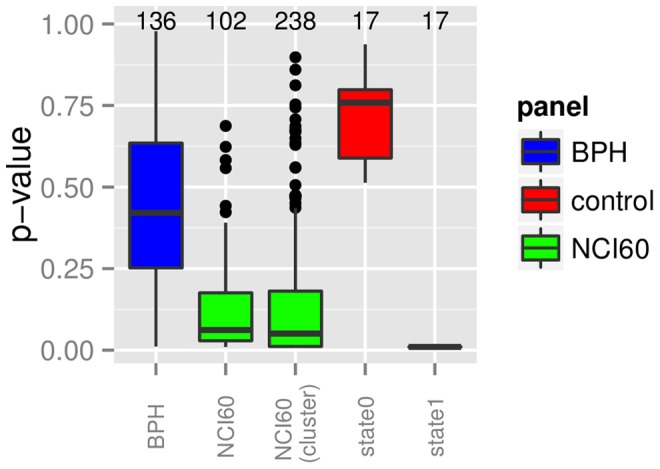
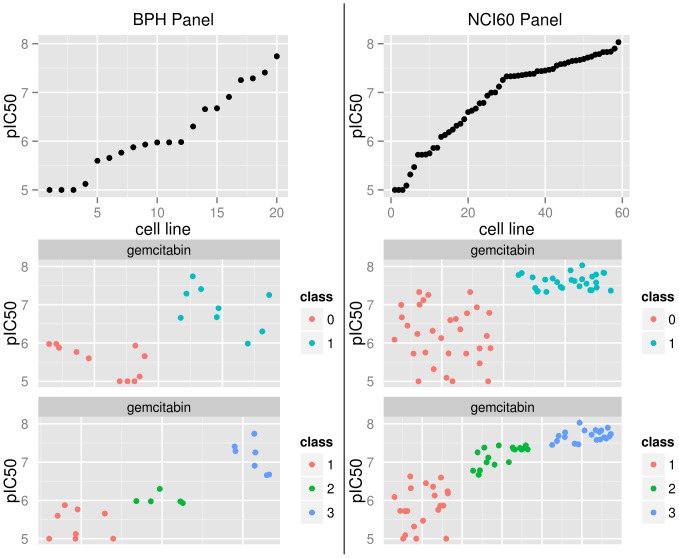
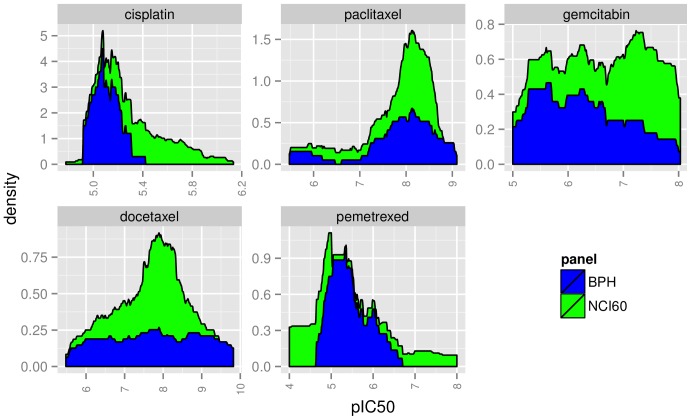
Model-based prediction is dependent on many choices ranging from the sample collection and prediction endpoint to the choice of algorithm and its parameters. Here we studied the effects of such choices, exemplified by predicting sensitivity (as IC50) of cancer cell lines towards a variety of compounds. For this, we used three independent sample collections and applied several machine learning algorithms for predicting a variety of endpoints for drug response. We compared all possible models for combinations of sample collections, algorithm, drug, and labeling to an identically generated null model. The predictability of treatment effects varies among compounds, i.e. response could be predicted for some but not for all. The choice of sample collection plays a major role towards lowering the prediction error, as does sample size. However, we found that no algorithm was able to consistently outperform the other and there was no significant difference between regression and two- or three class predictors in this experimental setting. These results indicate that response-modeling projects should direct efforts mainly towards sample collection and data quality, rather than method adjustment.
基于模型的预测取决于许多选择,从样本采集和预测终点到算法及其参数的选择。在这里,我们研究了这些选择的影响,以预测癌细胞系对各种化合物的敏感性(作为 IC50)为例。为此,我们使用了三个独立的样本集,并应用了几种机器学习算法来预测药物反应的各种终点。我们将所有可能的模型组合(样本集、算法、药物和标签)与相同生成的空模型进行了比较。化合物之间的治疗效果可预测性存在差异,即有些化合物的反应可以预测,但并非所有化合物的反应都可以预测。样本集的选择对降低预测误差起着重要作用,样本量也是如此。然而,我们发现没有一种算法能够始终优于其他算法,并且在这种实验设置中,回归和两分类或三分类预测器之间没有显著差异。这些结果表明,响应建模项目应主要致力于样本采集和数据质量,而不是方法调整。