Informatics Program, Boston Children's Hospital, Boston, Massachusetts, United States of America.
PLoS One. 2013 Aug 16;8(8):e69932. doi: 10.1371/journal.pone.0069932. eCollection 2013.
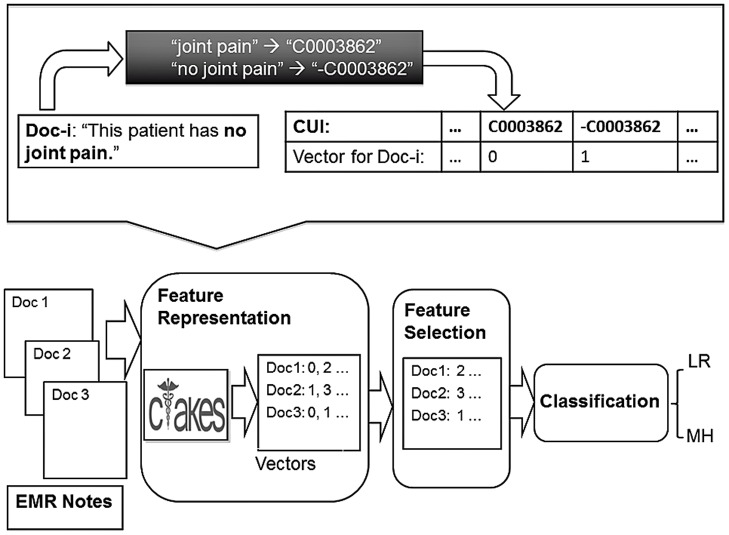
We aimed to mine the data in the Electronic Medical Record to automatically discover patients' Rheumatoid Arthritis disease activity at discrete rheumatology clinic visits. We cast the problem as a document classification task where the feature space includes concepts from the clinical narrative and lab values as stored in the Electronic Medical Record.
The Training Set consisted of 2792 clinical notes and associated lab values. Test Set 1 included 1749 clinical notes and associated lab values. Test Set 2 included 344 clinical notes for which there were no associated lab values. The Apache clinical Text Analysis and Knowledge Extraction System was used to analyze the text and transform it into informative features to be combined with relevant lab values.
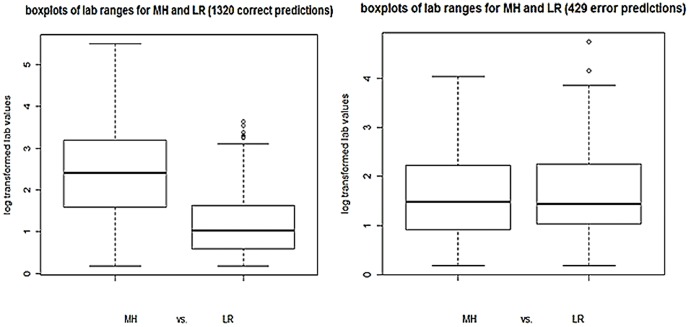
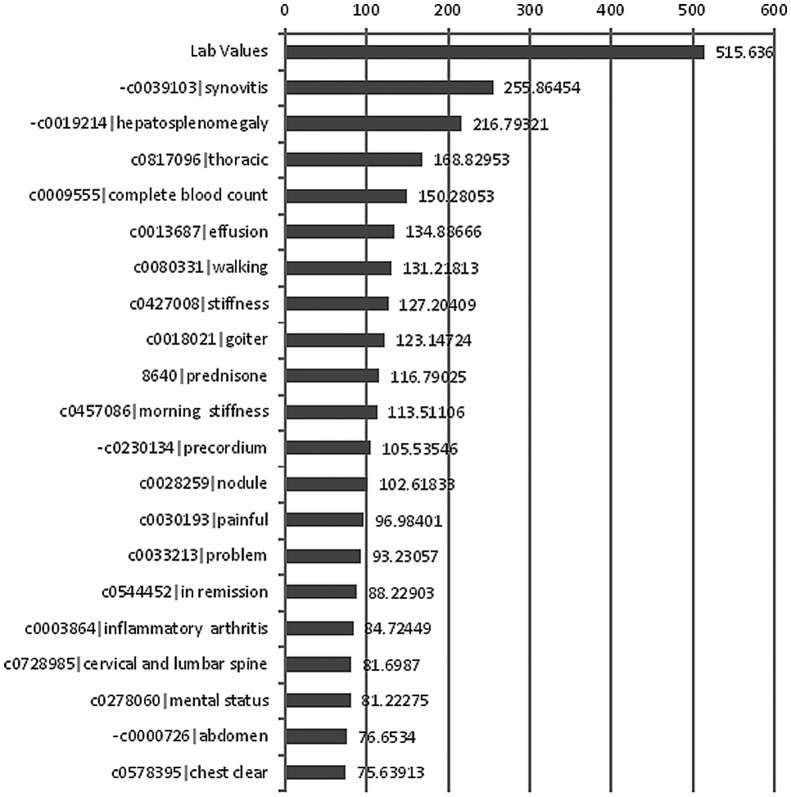
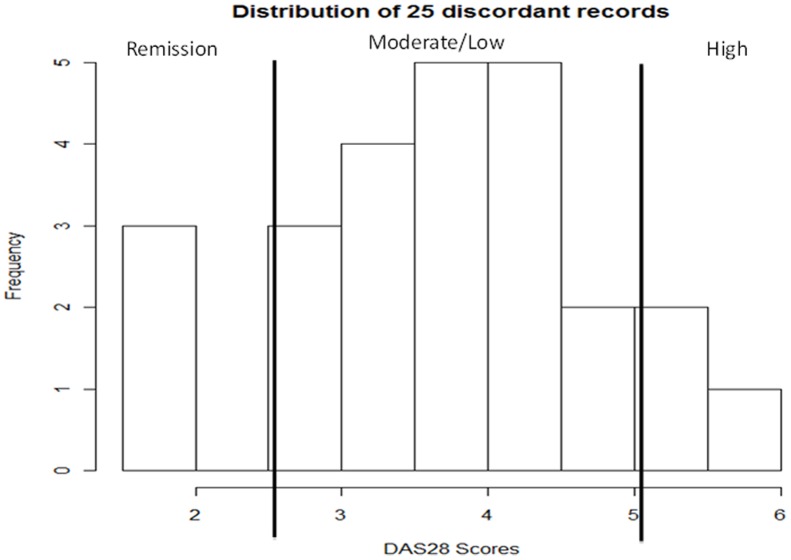
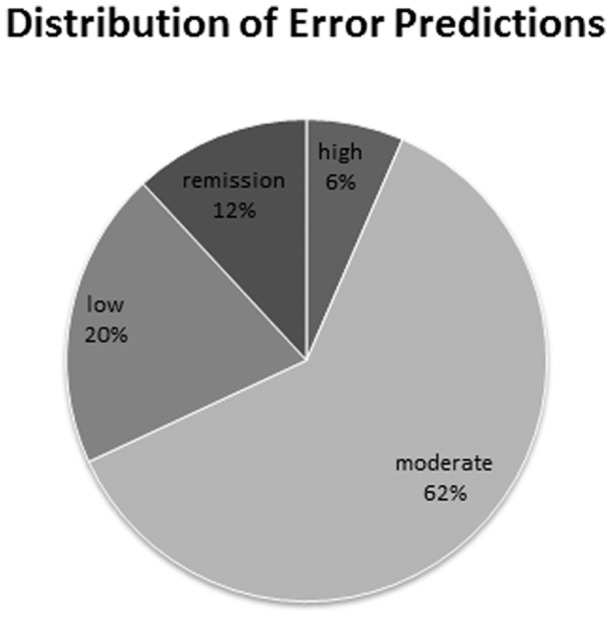
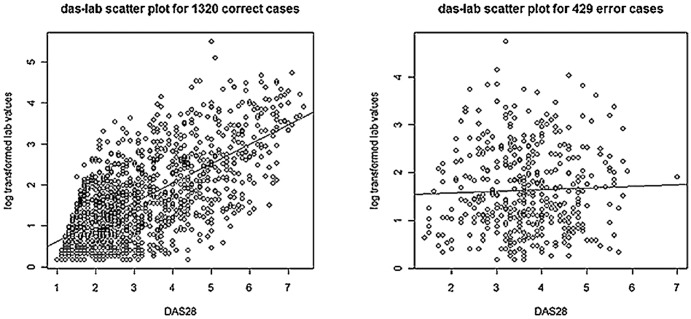
Experiments over a range of machine learning algorithms and features were conducted. The best performing combination was linear kernel Support Vector Machines with Unified Medical Language System Concept Unique Identifier features with feature selection and lab values. The Area Under the Receiver Operating Characteristic Curve (AUC) is 0.831 (σ = 0.0317), statistically significant as compared to two baselines (AUC = 0.758, σ = 0.0291). Algorithms demonstrated superior performance on cases clinically defined as extreme categories of disease activity (Remission and High) compared to those defined as intermediate categories (Moderate and Low) and included laboratory data on inflammatory markers.
Automatic Rheumatoid Arthritis disease activity discovery from Electronic Medical Record data is a learnable task approximating human performance. As a result, this approach might have several research applications, such as the identification of patients for genome-wide pharmacogenetic studies that require large sample sizes with precise definitions of disease activity and response to therapies.
我们旨在从电子病历数据中自动发现离散风湿病就诊时患者的类风湿关节炎疾病活动情况。我们将该问题建模为文档分类任务,其特征空间包括存储在电子病历中的临床叙述和实验室值中的概念。
训练集包含 2792 份临床记录和相关实验室值。测试集 1 包含 1749 份临床记录和相关实验室值。测试集 2 包含 344 份无相关实验室值的临床记录。Apache 临床文本分析和知识提取系统用于分析文本并将其转换为有意义的特征,以与相关实验室值相结合。
对一系列机器学习算法和特征进行了实验。表现最佳的组合是带有统一医学语言系统概念唯一标识符特征的线性核支持向量机,并结合特征选择和实验室值。接收者操作特征曲线下的面积(AUC)为 0.831(σ=0.0317),与两个基线(AUC=0.758,σ=0.0291)相比具有统计学意义。与定义为中间类别(中度和低度)的病例相比,算法在临床定义为疾病活动极端类别的病例(缓解和高度)上表现出更好的性能,并且包括炎症标志物的实验室数据。
从电子病历数据中自动发现类风湿关节炎疾病活动是一项可学习的任务,可近似于人类表现。因此,这种方法可能具有几个研究应用,例如需要具有疾病活动和对治疗反应的精确定义的大样本量的全基因组药物遗传学研究中患者的识别。