Department of Animal Sciences, University of Wisconsin-Madison Madison, WI, USA.
Zoetis Inc. Kalamazoo, MI, USA.
Front Genet. 2014 Mar 24;5:56. doi: 10.3389/fgene.2014.00056. eCollection 2014.
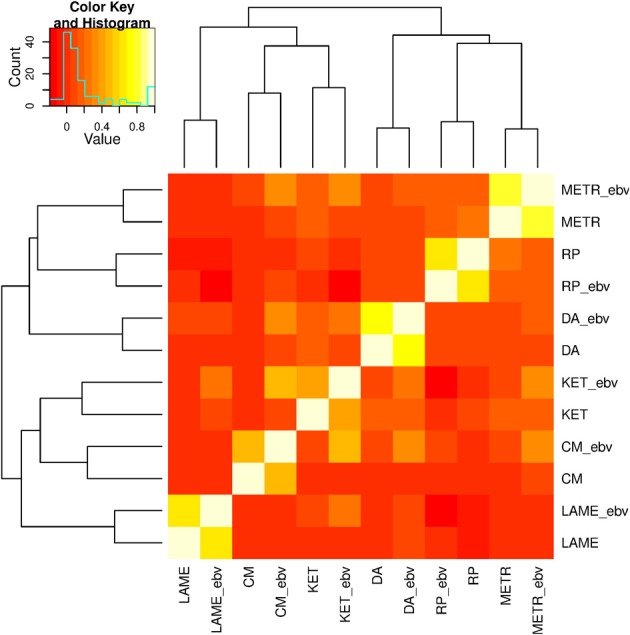
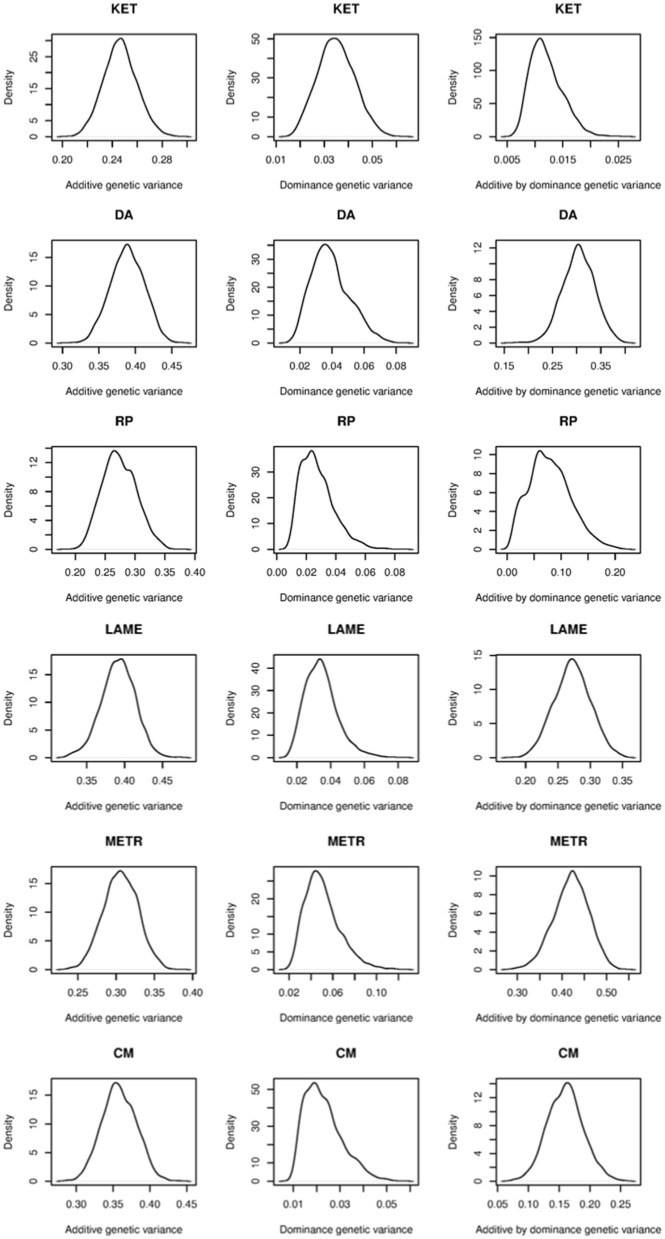
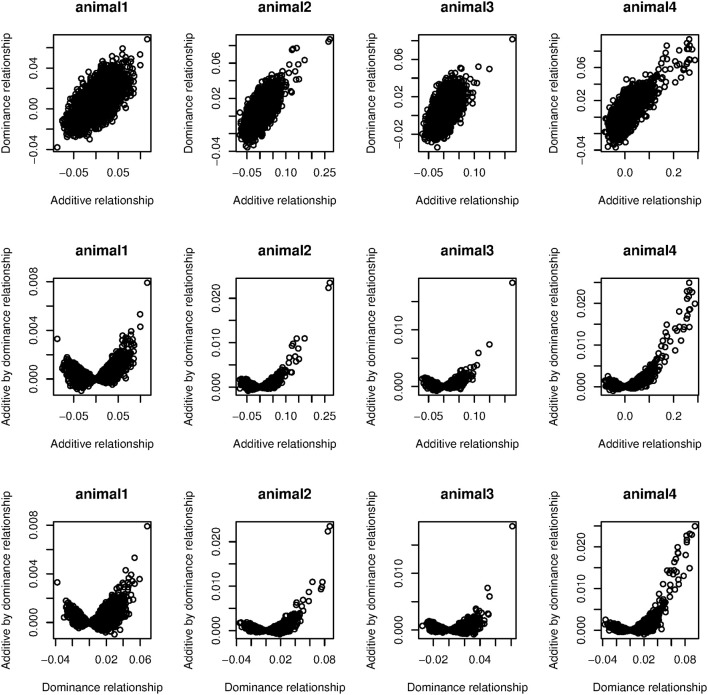
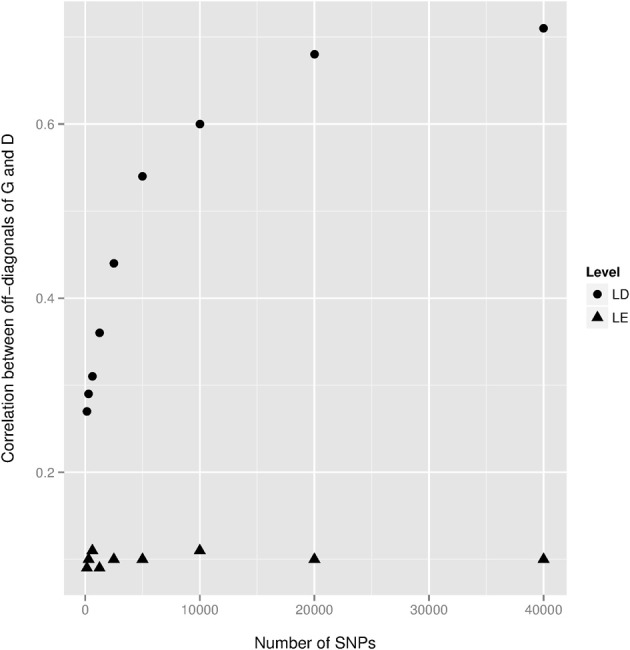
Prediction of complex trait phenotypes in the presence of unknown gene action is an ongoing challenge in animals, plants, and humans. Development of flexible predictive models that perform well irrespective of genetic and environmental architectures is desirable. Methods that can address non-additive variation in a non-explicit manner are gaining attention for this purpose and, in particular, semi-parametric kernel-based methods have been applied to diverse datasets, mostly providing encouraging results. On the other hand, the gains obtained from these methods have been smaller when smoothed values such as estimated breeding value (EBV) have been used as response variables. However, less emphasis has been placed on the choice of phenotypes to be used in kernel-based whole-genome prediction. This study aimed to evaluate differences between semi-parametric and parametric approaches using two types of response variables and molecular markers as inputs. Pre-corrected phenotypes (PCP) and EBV obtained for dairy cow health traits were used for this comparison. We observed that non-additive genetic variances were major contributors to total genetic variances in PCP, whereas additivity was the largest contributor to variability of EBV, as expected. Within the kernels evaluated, non-parametric methods yielded slightly better predictive performance across traits relative to their additive counterparts regardless of the type of response variable used. This reinforces the view that non-parametric kernels aiming to capture non-linear relationships between a panel of SNPs and phenotypes are appealing for complex trait prediction. However, like past studies, the gain in predictive correlation was not large for either PCP or EBV. We conclude that capturing non-additive genetic variation, especially epistatic variation, in a cross-validation framework remains a significant challenge even when it is important, as seems to be the case for health traits in dairy cows.
在动物、植物和人类中,预测存在未知基因作用的复杂性状表型是一个持续存在的挑战。开发能够灵活预测、不受遗传和环境结构影响的预测模型是理想的。为了实现这一目标,人们越来越关注能够以非显式方式处理非加性变异的方法,特别是半参数核基方法已被应用于各种数据集,这些方法大多提供了令人鼓舞的结果。另一方面,当使用平滑值(如估计育种值(EBV))作为响应变量时,这些方法获得的收益较小。然而,在核基全基因组预测中,用于选择表型的方法并没有得到足够的重视。本研究旨在使用两种类型的响应变量和分子标记作为输入,评估半参数和参数方法之间的差异。本研究使用奶牛健康性状的预校正表型(PCP)和 EBV 来进行比较。我们观察到,非加性遗传方差是 PCP 总遗传方差的主要贡献者,而加性方差是 EBV 变异性的最大贡献者,这与预期一致。在所评估的核函数中,无论使用哪种响应变量,非参数方法在各性状预测性能上均略优于其加性对应方法。这进一步证实了这样一种观点,即旨在捕捉 SNP 与表型之间非线性关系的非参数核函数对于复杂性状预测是很有吸引力的。然而,与过去的研究一样,无论是 PCP 还是 EBV,预测相关性的增益都不大。我们得出结论,即使对于奶牛健康性状等似乎很重要的情况,在交叉验证框架中捕捉非加性遗传变异,特别是上位性变异,仍然是一个重大挑战。