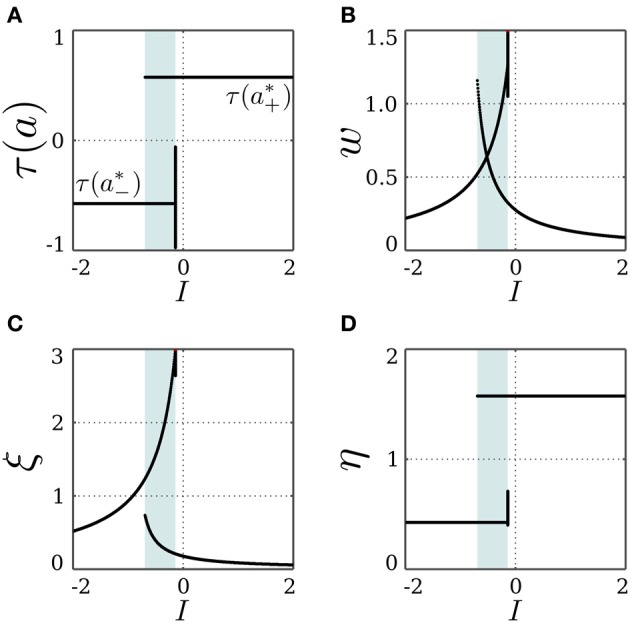
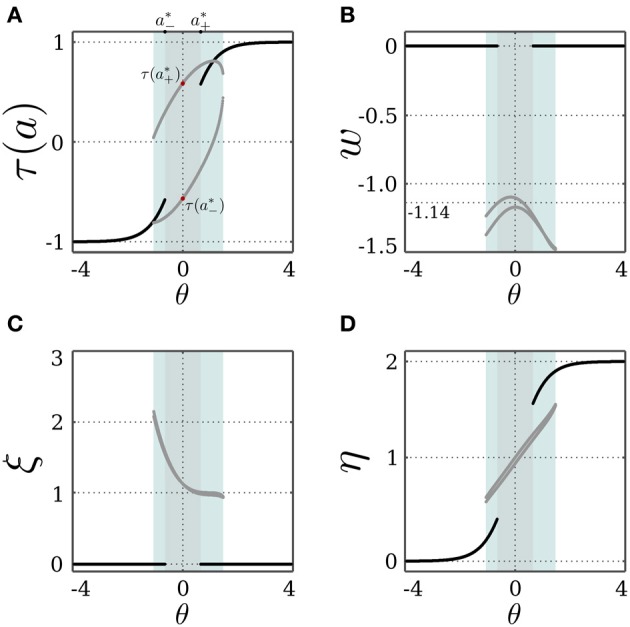
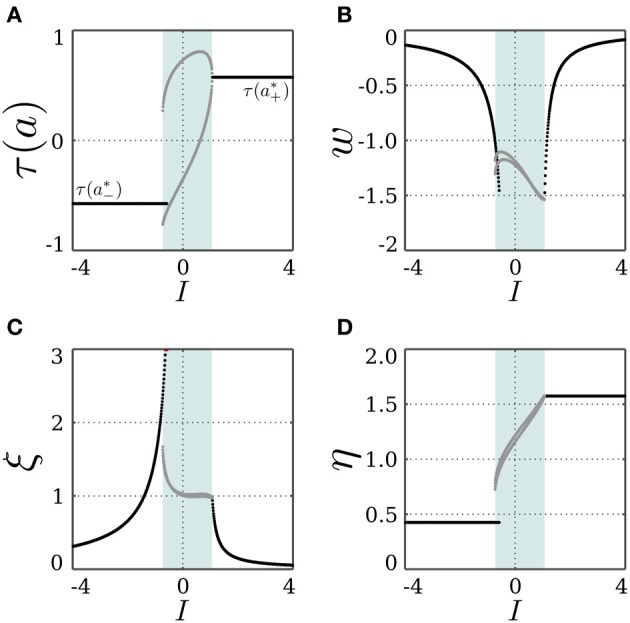
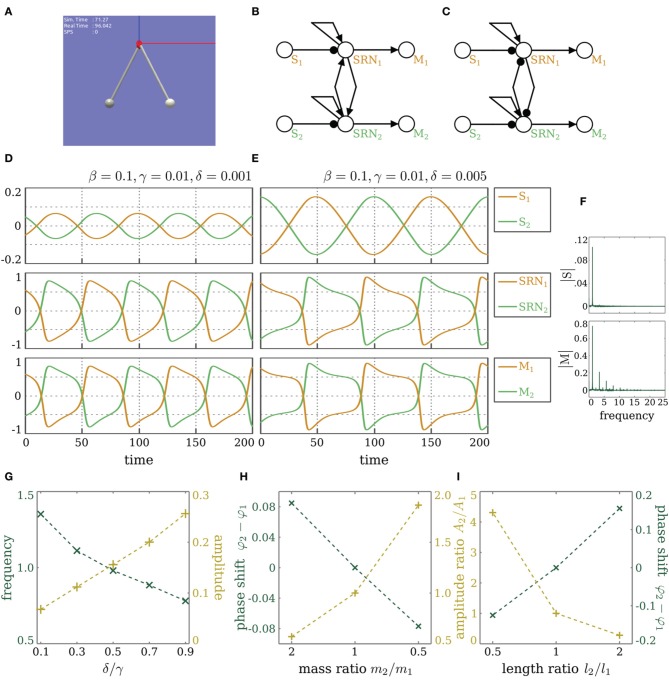
Department of Neurocybernetics, Institute of Cognitive Science, University of Osnabrück Osnabrück, Germany.
Front Neurorobot. 2014 May 23;8:19. doi: 10.3389/fnbot.2014.00019. eCollection 2014.
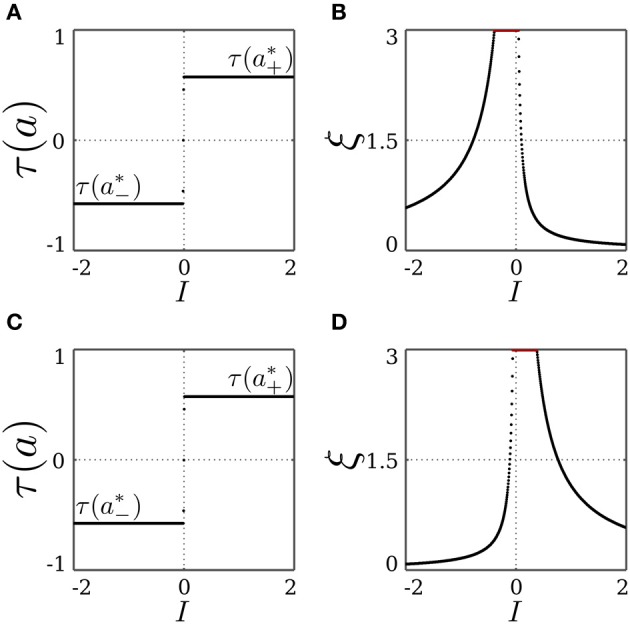
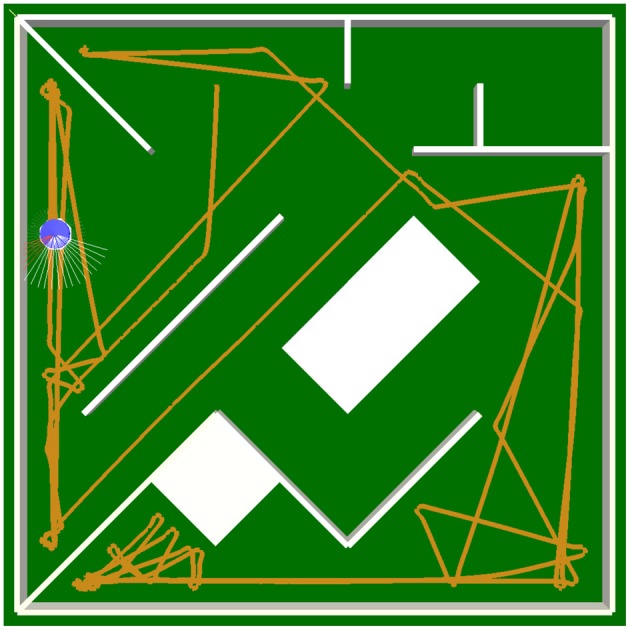
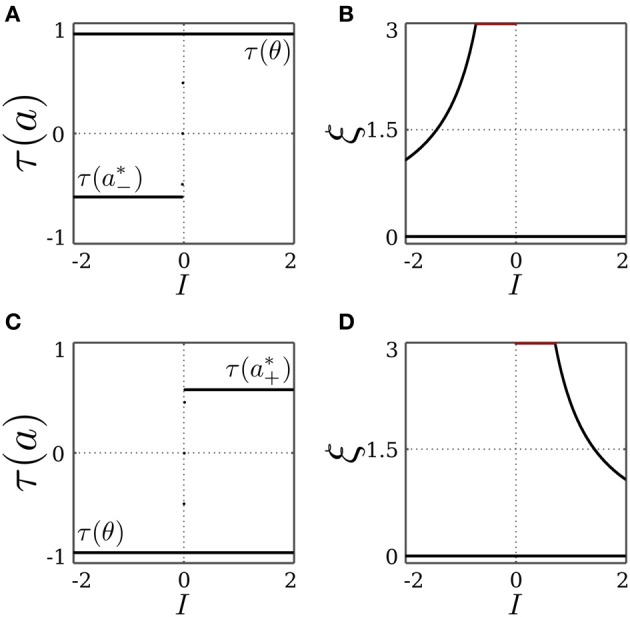
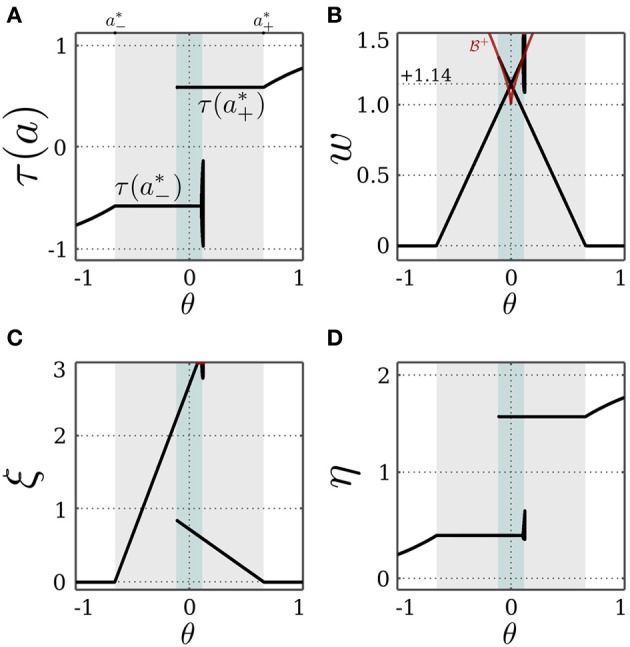
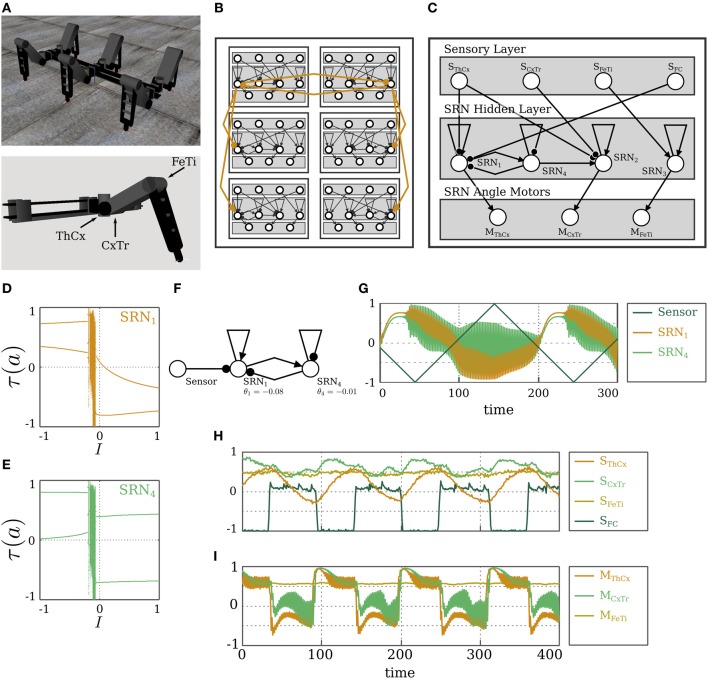
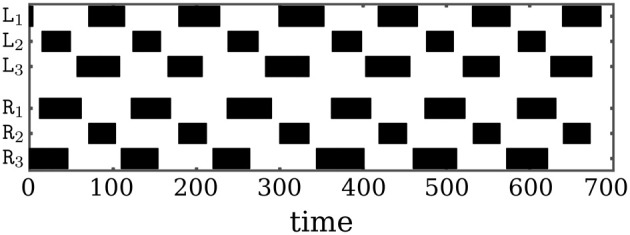
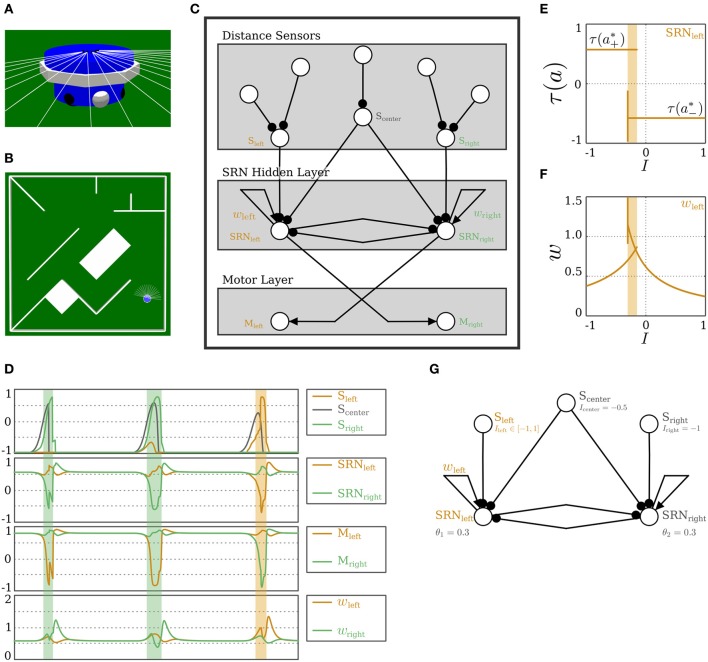
The behavior and skills of living systems depend on the distributed control provided by specialized and highly recurrent neural networks. Learning and memory in these systems is mediated by a set of adaptation mechanisms, known collectively as neuronal plasticity. Translating principles of recurrent neural control and plasticity to artificial agents has seen major strides, but is usually hampered by the complex interactions between the agent's body and its environment. One of the important standing issues is for the agent to support multiple stable states of behavior, so that its behavioral repertoire matches the requirements imposed by these interactions. The agent also must have the capacity to switch between these states in time scales that are comparable to those by which sensory stimulation varies. Achieving this requires a mechanism of short-term memory that allows the neurocontroller to keep track of the recent history of its input, which finds its biological counterpart in short-term synaptic plasticity. This issue is approached here by deriving synaptic dynamics in recurrent neural networks. Neurons are introduced as self-regulating units with a rich repertoire of dynamics. They exhibit homeostatic properties for certain parameter domains, which result in a set of stable states and the required short-term memory. They can also operate as oscillators, which allow them to surpass the level of activity imposed by their homeostatic operation conditions. Neural systems endowed with the derived synaptic dynamics can be utilized for the neural behavior control of autonomous mobile agents. The resulting behavior depends also on the underlying network structure, which is either engineered or developed by evolutionary techniques. The effectiveness of these self-regulating units is demonstrated by controlling locomotion of a hexapod with 18 degrees of freedom, and obstacle-avoidance of a wheel-driven robot.
生命系统的行为和技能依赖于专门化和高度重复神经网络提供的分布式控制。这些系统中的学习和记忆是由一组适应机制介导的,统称为神经元可塑性。将递归神经网络控制和可塑性的原理转化为人工智能代理已经取得了重大进展,但通常受到代理的身体与其环境之间复杂相互作用的阻碍。一个重要的待解决问题是,代理能够支持多个行为稳定状态,以便其行为范围与这些相互作用所施加的要求相匹配。代理还必须有能力在与感觉刺激变化可比的时间尺度内在这些状态之间切换。实现这一点需要一种短期记忆机制,使神经控制器能够跟踪其输入的最近历史,这在短期突触可塑性中找到了其生物学对应物。这里通过推导递归神经网络中的突触动力学来解决这个问题。神经元被引入为具有丰富动态的自调节单元。它们在某些参数域中表现出稳态特性,这导致了一组稳定状态和所需的短期记忆。它们还可以作为振荡器运行,这使它们能够超越其稳态操作条件所施加的活动水平。具有推导的突触动力学的神经系统可用于自主移动代理的神经行为控制。所得到的行为也取决于底层网络结构,该结构可以通过工程设计或通过进化技术来开发。这些自调节单元的有效性通过控制具有 18 个自由度的六足动物的运动和轮式机器人的避障来证明。