Computer Science and Engineering, The Pennsylvania State University, University Park, PA, USA.
Computer Science and Engineering, The Pennsylvania State University, University Park, PA, USA ; Information Sciences and Technology, The Pennsylvania State University, University Park, PA, USA.
J Cheminform. 2015 Jan 19;7(Suppl 1 Text mining for chemistry and the CHEMDNER track):S12. doi: 10.1186/1758-2946-7-S1-S12. eCollection 2015.
As we are witnessing a great interest in identifying and extracting chemical entities in academic articles, many approaches have been proposed to solve this problem. In this work we describe a probabilistic framework that allows for the output of multiple information extraction systems to be combined in a systematic way. The identified entities are assigned a probability score that reflects the extractors' confidence, without the need for each individual extractor to generate a probability score. We quantitively compared the performance of multiple chemical tokenizers to measure the effect of tokenization on extraction accuracy. Later, a single Conditional Random Fields (CRF) extractor that utilizes the best performing tokenizer is built using a unique collection of features such as word embeddings and Soundex codes, which, to the best of our knowledge, has not been explored in this context before.
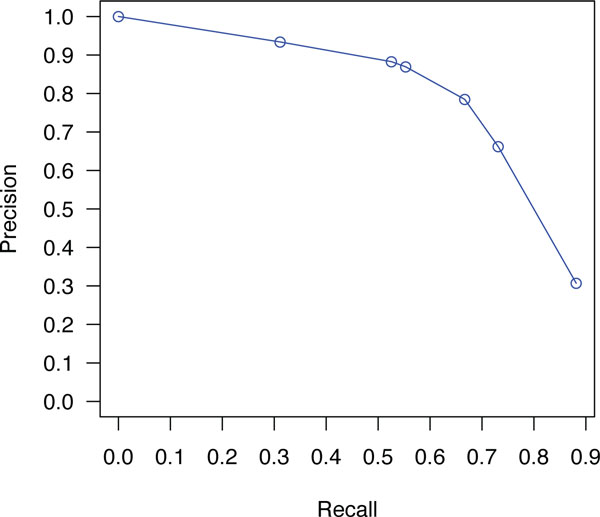
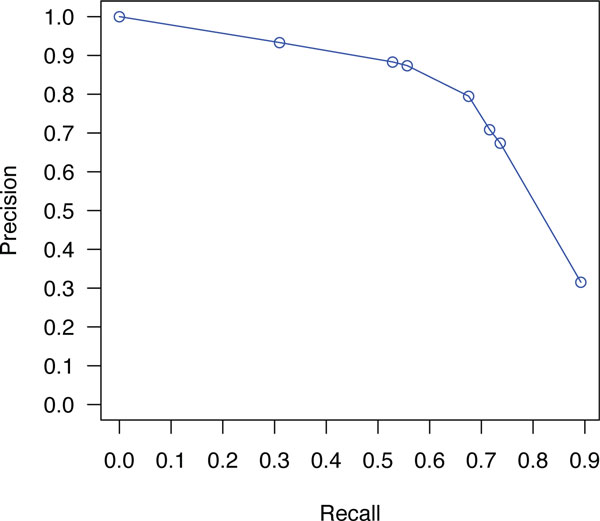
The ensemble of multiple extractors outperforms each extractor's individual performance during the CHEMDNER challenge. When the runs were optimized to favor recall, the ensemble approach achieved the second highest recall on unseen entities. As for the single CRF model with novel features, the extractor achieves an F1 score of 83.3% on the test set, without any post processing or abbreviation matching.
Ensemble information extraction is effective when multiple stand alone extractors are to be used, and produces higher performance than individual off the shelf extractors. The novel features introduced in the single CRF model are sufficient to achieve very competitive F1 score using a simple standalone extractor.
由于我们对识别和提取学术文章中的化学实体产生了浓厚的兴趣,因此已经提出了许多方法来解决这个问题。在这项工作中,我们描述了一个概率框架,该框架允许以系统的方式组合多个信息提取系统的输出。为识别出的实体分配概率得分,该得分反映了提取器的置信度,而无需每个单独的提取器生成概率得分。我们定量比较了多种化学标记器的性能,以衡量标记化对提取准确性的影响。之后,使用独特的特征集(例如词嵌入和 Soundex 代码)构建了单个利用最佳表现标记器的条件随机场(CRF)提取器,据我们所知,在此之前尚未在这种情况下探索过这些特征。
在 CHEMDNER 挑战赛中,多个提取器的集成在性能上优于每个提取器的单个性能。当优化运行以提高召回率时,集成方法在未见实体上实现了第二高的召回率。对于具有新颖功能的单个 CRF 模型,提取器在测试集上的 F1 得分为 83.3%,而无需进行任何后处理或缩写匹配。
当要使用多个独立的提取器时,集成信息提取是有效的,并且比单个现成的提取器具有更高的性能。在单个 CRF 模型中引入的新颖功能足以使用简单的独立提取器获得非常有竞争力的 F1 得分。