Duitama Jorge, Silva Alexander, Sanabria Yamid, Cruz Daniel Felipe, Quintero Constanza, Ballen Carolina, Lorieux Mathias, Scheffler Brian, Farmer Andrew, Torres Edgar, Oard James, Tohme Joe
Agrobiodiversity research area, International Center for Tropical Agriculture, Cali, Colombia.
Rice Research Station, Louisiana State University Agricultural Center, Rayne, Louisiana, United States of America.
PLoS One. 2015 Apr 29;10(4):e0124617. doi: 10.1371/journal.pone.0124617. eCollection 2015.
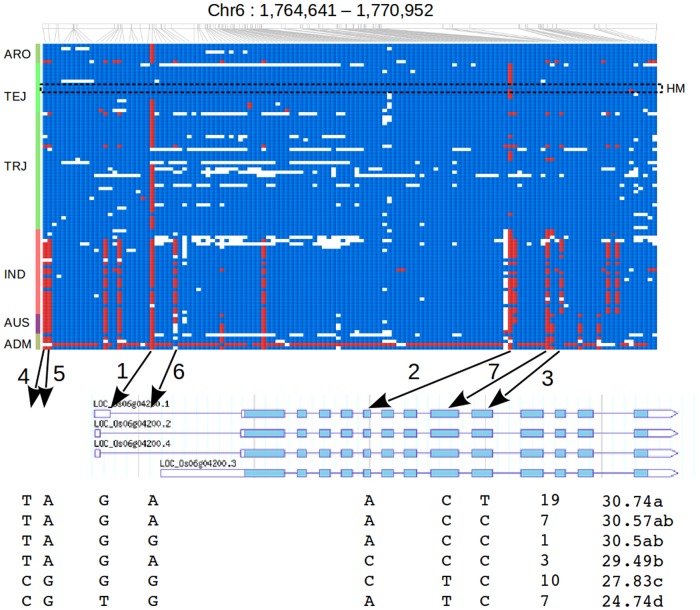
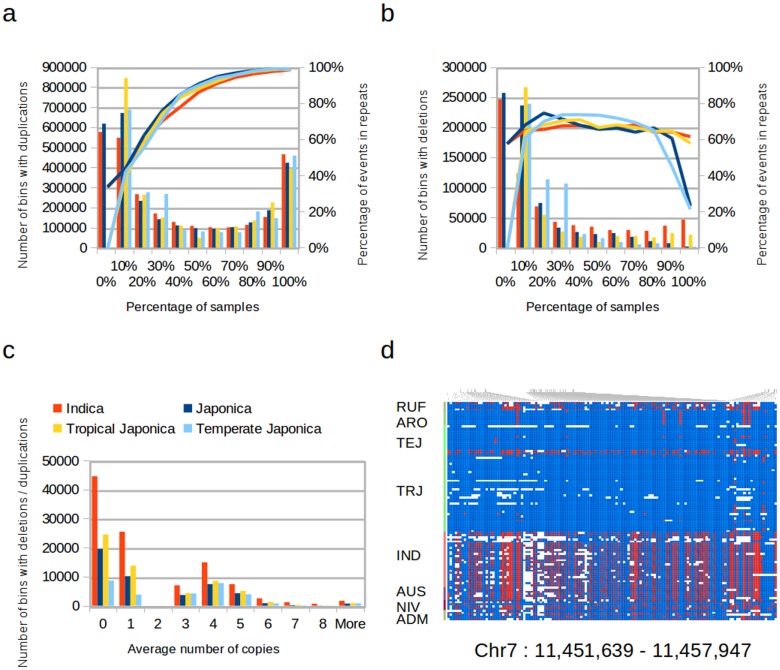
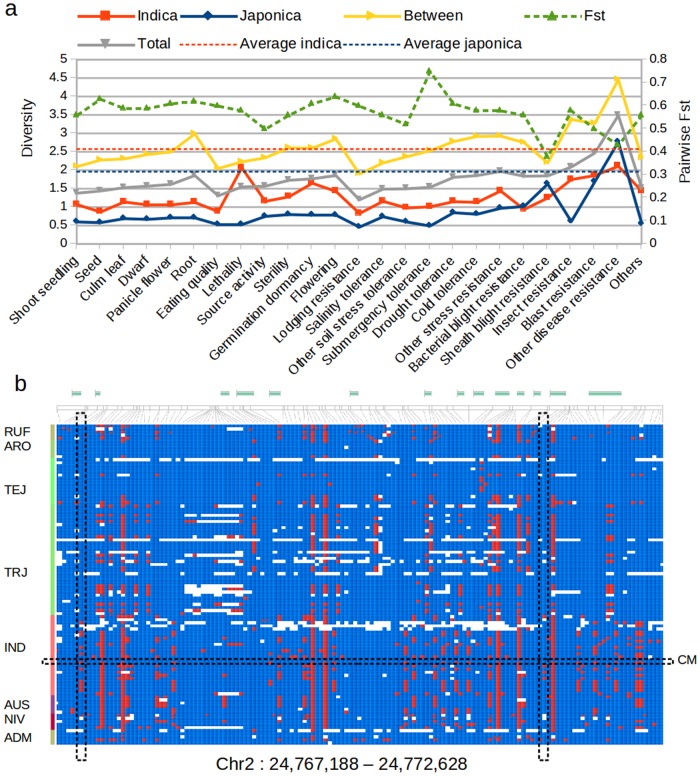
Current advances in sequencing technologies and bioinformatics revealed the genomic background of rice, a staple food for the poor people, and provided the basis to develop large genomic variation databases for thousands of cultivars. Proper analysis of this massive resource is expected to give novel insights into the structure, function, and evolution of the rice genome, and to aid the development of rice varieties through marker assisted selection or genomic selection. In this work we present sequencing and bioinformatics analyses of 104 rice varieties belonging to the major subspecies of Oryza sativa. We identified repetitive elements and recurrent copy number variation covering about 200 Mbp of the rice genome. Genotyping of over 18 million polymorphic locations within O. sativa allowed us to reconstruct the individual haplotype patterns shaping the genomic background of elite varieties used by farmers throughout the Americas. Based on a reconstruction of the alleles for the gene GBSSI, we could identify novel genetic markers for selection of varieties with high amylose content. We expect that both the analysis methods and the genomic information described here would be of great use for the rice research community and for other groups carrying on similar sequencing efforts in other crops.
测序技术和生物信息学的当前进展揭示了水稻(穷人的主食)的基因组背景,并为开发数千个品种的大型基因组变异数据库提供了基础。对这一海量资源进行恰当分析,有望为水稻基因组的结构、功能和进化提供新见解,并通过标记辅助选择或基因组选择助力水稻品种的培育。在这项工作中,我们展示了对属于亚洲栽培稻主要亚种的104个水稻品种的测序和生物信息学分析。我们鉴定出了覆盖水稻基因组约200兆碱基对的重复元件和反复出现的拷贝数变异。对亚洲栽培稻内超过1800万个多态性位点进行基因分型,使我们能够重建塑造美洲各地农民所使用的优良品种基因组背景的个体单倍型模式。基于对基因GBSSI等位基因的重建,我们能够鉴定出用于选择高直链淀粉含量品种的新型遗传标记。我们预计,本文所述的分析方法和基因组信息将对水稻研究群体以及其他对其他作物进行类似测序工作的群体有很大用处。