Jeong Jig Han, Resop Jonathan P, Mueller Nathaniel D, Fleisher David H, Yun Kyungdahm, Butler Ethan E, Timlin Dennis J, Shim Kyo-Moon, Gerber James S, Reddy Vangimalla R, Kim Soo-Hyung
School of Environmental and Forest Sciences, College of the Environment, University of Washington, Box 354115, Seattle, WA 98195, United States of America.
Department of Geographical Sciences, University of Maryland, College Park, MD, United States of America.
PLoS One. 2016 Jun 3;11(6):e0156571. doi: 10.1371/journal.pone.0156571. eCollection 2016.
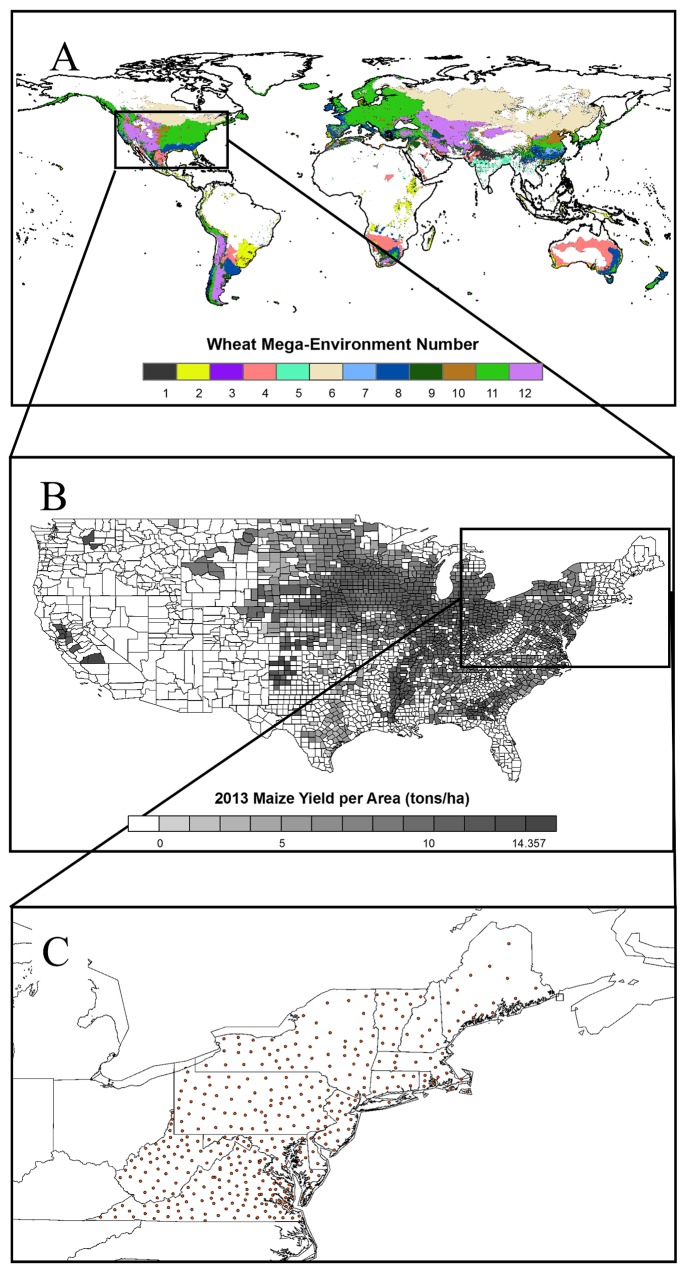
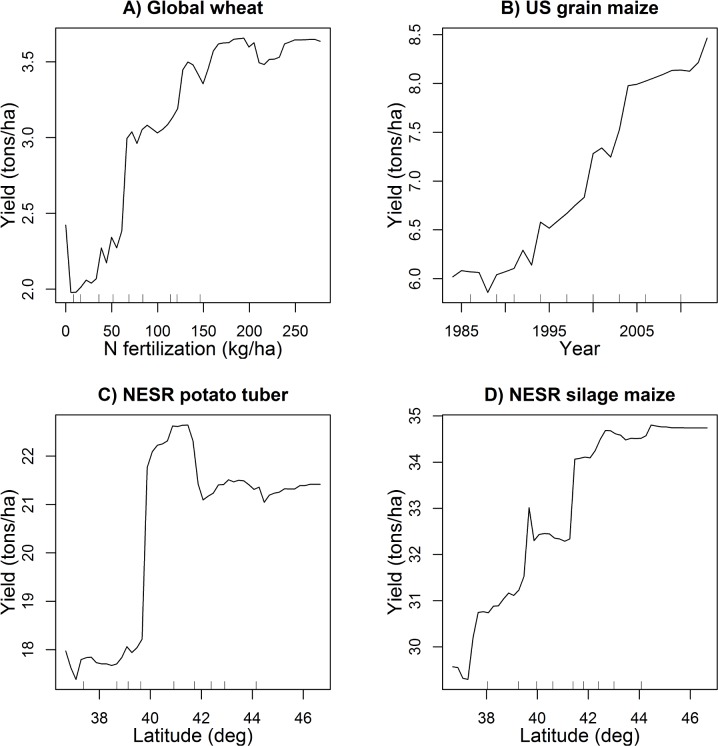
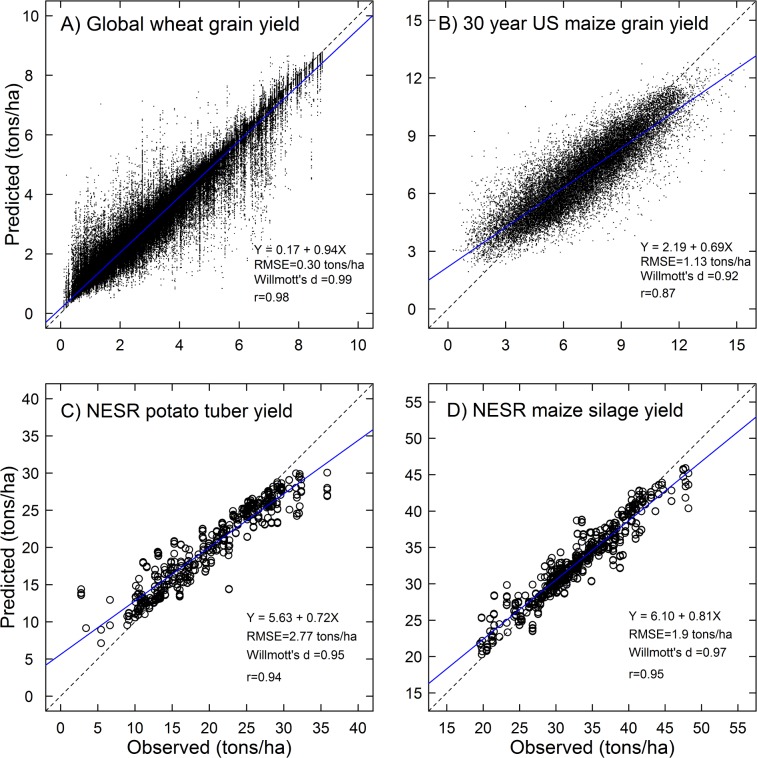
Accurate predictions of crop yield are critical for developing effective agricultural and food policies at the regional and global scales. We evaluated a machine-learning method, Random Forests (RF), for its ability to predict crop yield responses to climate and biophysical variables at global and regional scales in wheat, maize, and potato in comparison with multiple linear regressions (MLR) serving as a benchmark. We used crop yield data from various sources and regions for model training and testing: 1) gridded global wheat grain yield, 2) maize grain yield from US counties over thirty years, and 3) potato tuber and maize silage yield from the northeastern seaboard region. RF was found highly capable of predicting crop yields and outperformed MLR benchmarks in all performance statistics that were compared. For example, the root mean square errors (RMSE) ranged between 6 and 14% of the average observed yield with RF models in all test cases whereas these values ranged from 14% to 49% for MLR models. Our results show that RF is an effective and versatile machine-learning method for crop yield predictions at regional and global scales for its high accuracy and precision, ease of use, and utility in data analysis. RF may result in a loss of accuracy when predicting the extreme ends or responses beyond the boundaries of the training data.
准确预测作物产量对于制定区域和全球层面有效的农业和粮食政策至关重要。我们评估了一种机器学习方法——随机森林(RF),与作为基准的多元线性回归(MLR)相比,其在全球和区域尺度上预测小麦、玉米和马铃薯产量对气候和生物物理变量响应的能力。我们使用来自不同来源和地区的作物产量数据进行模型训练和测试:1)网格化的全球小麦籽粒产量,2)美国各县30年的玉米籽粒产量,以及3)美国东北沿海地区的马铃薯块茎和玉米青贮产量。在所有比较的性能统计中,发现随机森林非常能够预测作物产量,并且优于多元线性回归基准。例如,在所有测试案例中,随机森林模型的均方根误差(RMSE)在平均观测产量的6%至14%之间,而多元线性回归模型的这些值在14%至49%之间。我们的结果表明,随机森林因其高精度、易用性以及在数据分析中的实用性,是一种在区域和全球尺度上预测作物产量的有效且通用的机器学习方法。当预测超出训练数据边界的极端情况或响应时,随机森林可能会导致准确性下降。