Martin Glen P, Mamas Mamas A, Peek Niels, Buchan Iain, Sperrin Matthew
Health e-Research Centre, University of Manchester, Vaughan House, Portsmouth Street, M13 9GB, Manchester, UK.
Keele Cardiovascular Research Group, Keele University, Stoke-on-Trent, UK.
BMC Med Res Methodol. 2017 Jan 6;17(1):1. doi: 10.1186/s12874-016-0277-1.
Clinical prediction models (CPMs) are increasingly deployed to support healthcare decisions but they are derived inconsistently, in part due to limited data. An emerging alternative is to aggregate existing CPMs developed for similar settings and outcomes. This simulation study aimed to investigate the impact of between-population-heterogeneity and sample size on aggregating existing CPMs in a defined population, compared with developing a model de novo.
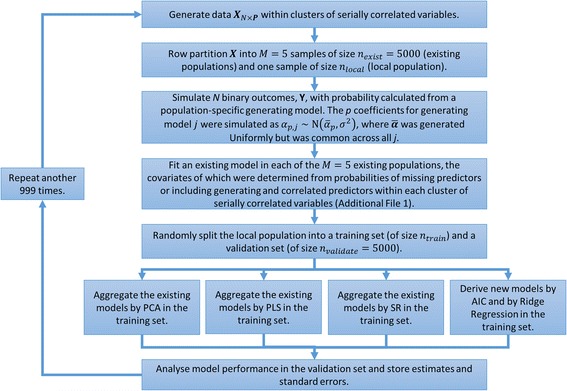
Simulations were designed to mimic a scenario in which multiple CPMs for a binary outcome had been derived in distinct, heterogeneous populations, with potentially different predictors available in each. We then generated a new 'local' population and compared the performance of CPMs developed for this population by aggregation, using stacked regression, principal component analysis or partial least squares, with redevelopment from scratch using backwards selection and penalised regression.
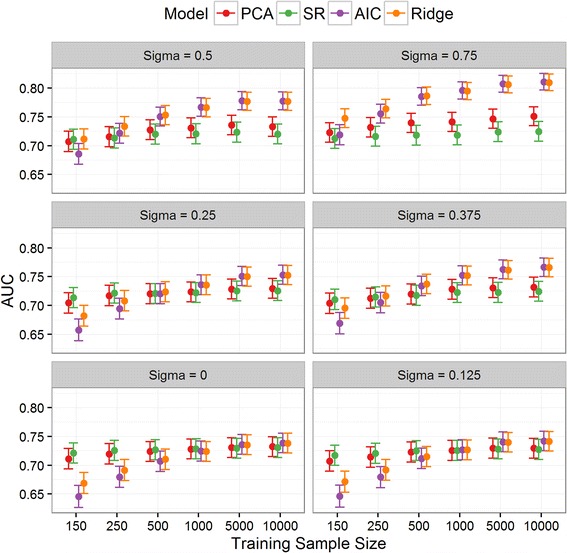
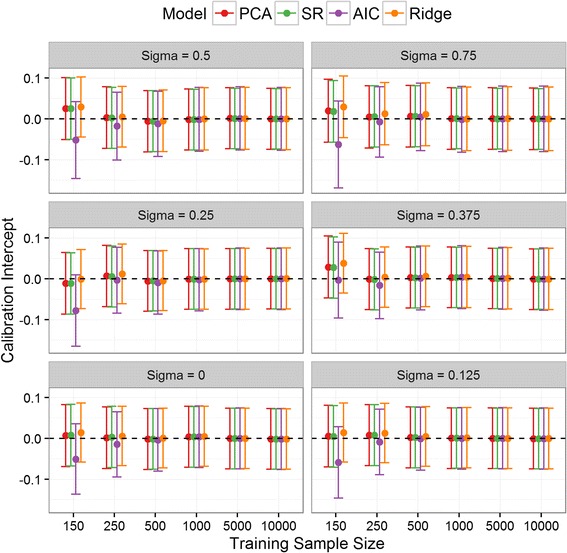
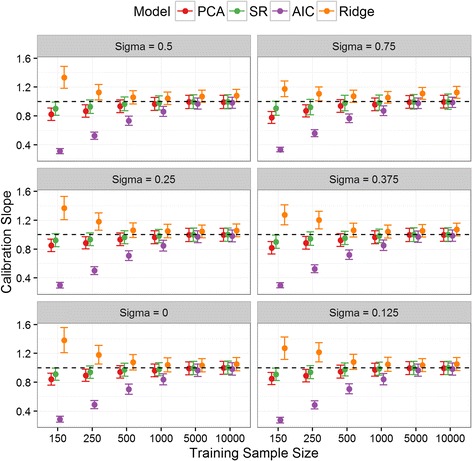
While redevelopment approaches resulted in models that were miscalibrated for local datasets of less than 500 observations, model aggregation methods were well calibrated across all simulation scenarios. When the size of local data was less than 1000 observations and between-population-heterogeneity was small, aggregating existing CPMs gave better discrimination and had the lowest mean square error in the predicted risks compared with deriving a new model. Conversely, given greater than 1000 observations and significant between-population-heterogeneity, then redevelopment outperformed the aggregation approaches. In all other scenarios, both aggregation and de novo derivation resulted in similar predictive performance.
This study demonstrates a pragmatic approach to contextualising CPMs to defined populations. When aiming to develop models in defined populations, modellers should consider existing CPMs, with aggregation approaches being a suitable modelling strategy particularly with sparse data on the local population.
临床预测模型(CPMs)越来越多地被用于支持医疗决策,但它们的推导并不一致,部分原因是数据有限。一种新出现的替代方法是汇总针对相似情况和结果开发的现有CPMs。本模拟研究旨在调查人群间异质性和样本量对在特定人群中汇总现有CPMs的影响,并与从头开发模型进行比较。
模拟旨在模仿这样一种情景,即针对二元结局的多个CPMs已在不同的异质人群中推导得出,每个群体中可用的预测因素可能不同。然后我们生成一个新的“本地”人群,并比较通过汇总(使用堆叠回归、主成分分析或偏最小二乘法)为该人群开发的CPMs的性能,与使用向后选择和惩罚回归从头重新开发的性能。
虽然重新开发方法导致的模型在观测值少于500的本地数据集中校准不佳,但模型汇总方法在所有模拟情景中校准良好。当本地数据量少于1000个观测值且人群间异质性较小时,与推导新模型相比,汇总现有CPMs具有更好的区分度,并且在预测风险方面的均方误差最低。相反,当观测值大于1000且人群间异质性显著时,重新开发的效果优于汇总方法。在所有其他情景中,汇总和从头推导都产生了相似的预测性能。
本研究展示了一种将CPMs应用于特定人群的实用方法。当旨在为特定人群开发模型时,建模者应考虑现有CPMs,汇总方法是一种合适的建模策略,特别是在本地人群数据稀疏的情况下。