National Center for Biotechnology Information, National Library of Medicine, National Institutes of Health, Bethesda, MD, 20894, USA.
Sci Rep. 2017 Jan 12;7:40376. doi: 10.1038/srep40376.
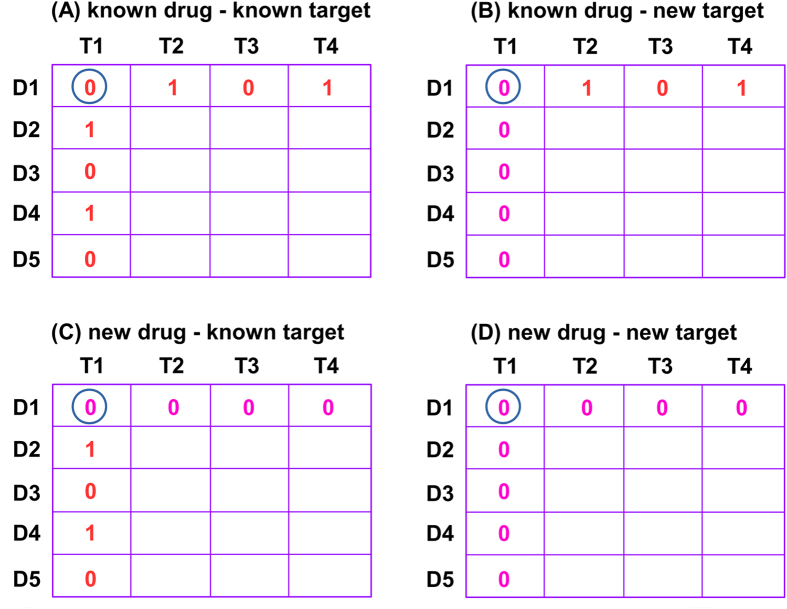
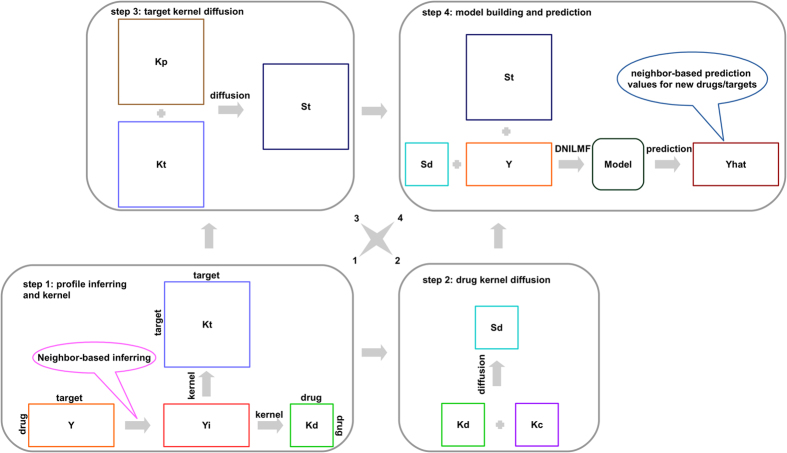
In this work, we propose a dual-network integrated logistic matrix factorization (DNILMF) algorithm to predict potential drug-target interactions (DTI). The prediction procedure consists of four steps: (1) inferring new drug/target profiles and constructing profile kernel matrix; (2) diffusing drug profile kernel matrix with drug structure kernel matrix; (3) diffusing target profile kernel matrix with target sequence kernel matrix; and (4) building DNILMF model and smoothing new drug/target predictions based on their neighbors. We compare our algorithm with the state-of-the-art method based on the benchmark dataset. Results indicate that the DNILMF algorithm outperforms the previously reported approaches in terms of AUPR (area under precision-recall curve) and AUC (area under curve of receiver operating characteristic) based on the 5 trials of 10-fold cross-validation. We conclude that the performance improvement depends on not only the proposed objective function, but also the used nonlinear diffusion technique which is important but under studied in the DTI prediction field. In addition, we also compile a new DTI dataset for increasing the diversity of currently available benchmark datasets. The top prediction results for the new dataset are confirmed by experimental studies or supported by other computational research.
在这项工作中,我们提出了一种双网络集成逻辑矩阵分解(DNILMF)算法来预测潜在的药物-靶标相互作用(DTI)。预测过程包括四个步骤:(1)推断新的药物/靶标谱并构建谱核矩阵;(2)用药物结构核矩阵扩散药物谱核矩阵;(3)用靶序列核矩阵扩散靶标谱核矩阵;(4)构建 DNILMF 模型并根据其邻居对新的药物/靶标预测进行平滑处理。我们基于基准数据集将我们的算法与最先进的方法进行了比较。结果表明,DNILMF 算法在基于 10 折交叉验证的 5 次试验的 AUPR(精度-召回率曲线下面积)和 AUC(接收者操作特征曲线下面积)方面优于以前的方法。我们得出的结论是,性能的提高不仅取决于所提出的目标函数,还取决于所使用的非线性扩散技术,这在 DTI 预测领域很重要,但研究不足。此外,我们还为增加当前可用基准数据集的多样性编译了一个新的 DTI 数据集。新数据集的顶级预测结果通过实验研究得到了证实,或者得到了其他计算研究的支持。