Bisenius Sandrine, Mueller Karsten, Diehl-Schmid Janine, Fassbender Klaus, Grimmer Timo, Jessen Frank, Kassubek Jan, Kornhuber Johannes, Landwehrmeyer Bernhard, Ludolph Albert, Schneider Anja, Anderl-Straub Sarah, Stuke Katharina, Danek Adrian, Otto Markus, Schroeter Matthias L
Max Planck Institute for Human Cognitive and Brain Sciences & Clinic for Cognitive Neurology, University Hospital Leipzig, Germany.
Clinic and Polyclinic for Psychiatry & Psychotherapy, Technical University Munich, Germany.
Neuroimage Clin. 2017 Feb 6;14:334-343. doi: 10.1016/j.nicl.2017.02.003. eCollection 2017.
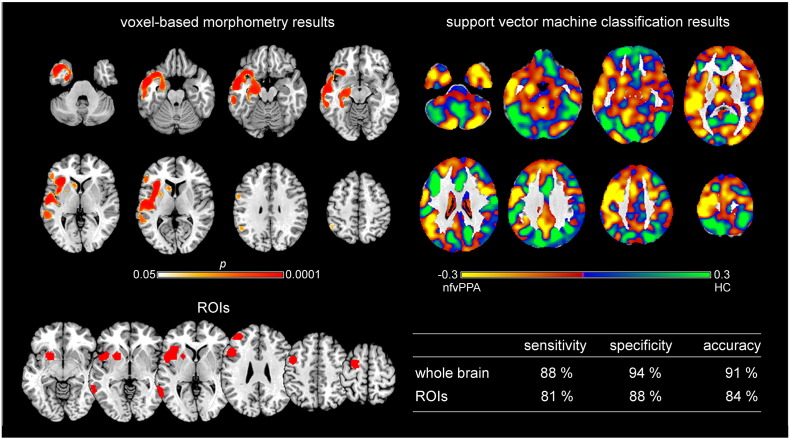
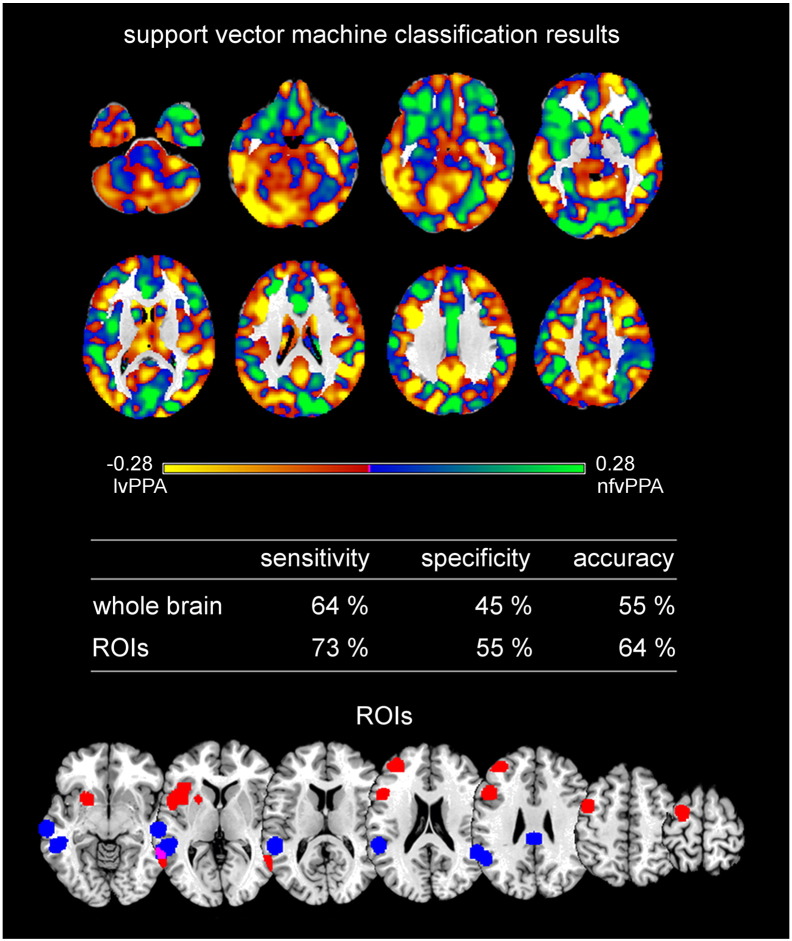
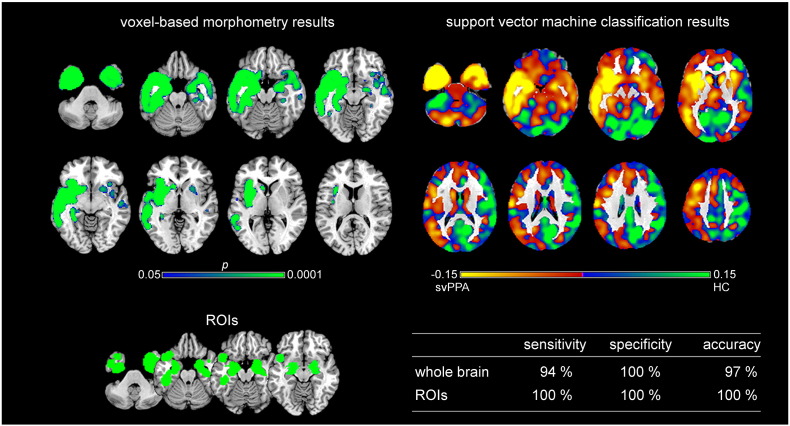
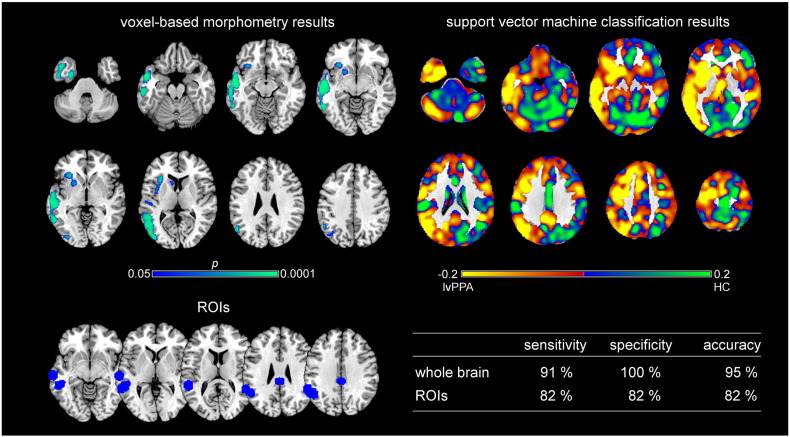
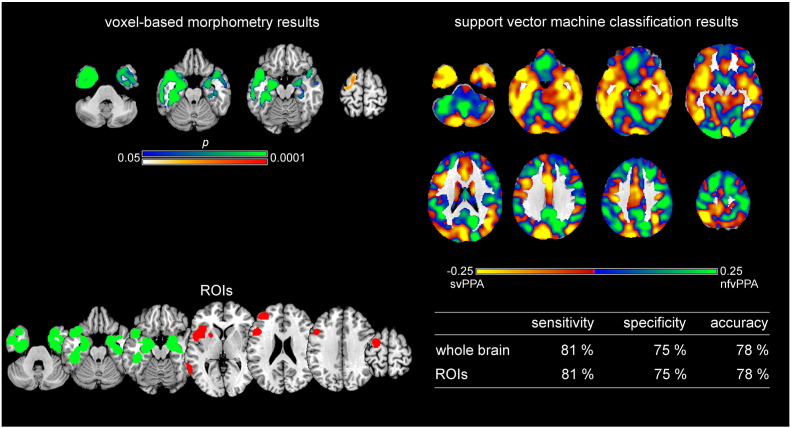
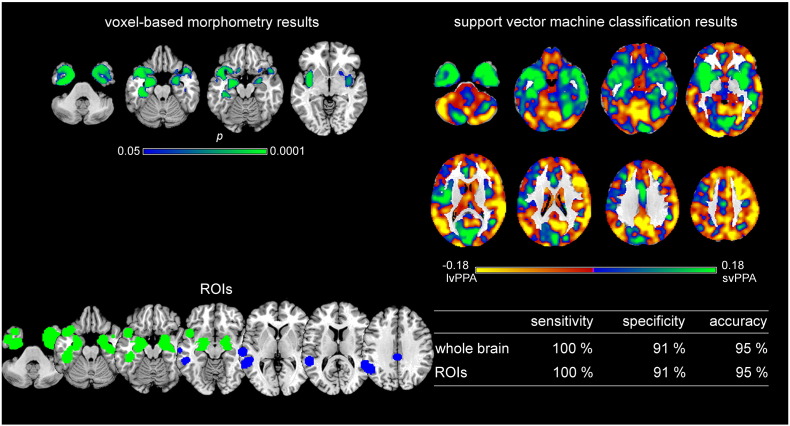
Primary progressive aphasia (PPA) encompasses the three subtypes nonfluent/agrammatic variant PPA, semantic variant PPA, and the logopenic variant PPA, which are characterized by distinct patterns of language difficulties and regional brain atrophy. To validate the potential of structural magnetic resonance imaging data for early individual diagnosis, we used support vector machine classification on grey matter density maps obtained by voxel-based morphometry analysis to discriminate PPA subtypes (44 patients: 16 nonfluent/agrammatic variant PPA, 17 semantic variant PPA, 11 logopenic variant PPA) from 20 healthy controls (matched for sample size, age, and gender) in the cohort of the multi-center study of the German consortium for frontotemporal lobar degeneration. Here, we compared a whole-brain with a meta-analysis-based disease-specific regions-of-interest approach for support vector machine classification. We also used support vector machine classification to discriminate the three PPA subtypes from each other. Whole brain support vector machine classification enabled a very high accuracy between 91 and 97% for identifying specific PPA subtypes vs. healthy controls, and 78/95% for the discrimination between semantic variant vs. nonfluent/agrammatic or logopenic PPA variants. Only for the discrimination between nonfluent/agrammatic and logopenic PPA variants accuracy was low with 55%. Interestingly, the regions that contributed the most to the support vector machine classification of patients corresponded largely to the regions that were atrophic in these patients as revealed by group comparisons. Although the whole brain approach took also into account regions that were not covered in the regions-of-interest approach, both approaches showed similar accuracies due to the disease-specificity of the selected networks. Conclusion, support vector machine classification of multi-center structural magnetic resonance imaging data enables prediction of PPA subtypes with a very high accuracy paving the road for its application in clinical settings.
原发性进行性失语(PPA)包括三种亚型:非流利/语法缺失型PPA、语义型PPA和音韵性失写型PPA,它们具有独特的语言困难模式和局部脑萎缩特征。为了验证结构磁共振成像数据在早期个体诊断中的潜力,我们在基于体素的形态测量分析获得的灰质密度图上使用支持向量机分类,以区分PPA亚型(44例患者:16例非流利/语法缺失型PPA、17例语义型PPA、11例音韵性失写型PPA)与德国额颞叶变性协会多中心研究队列中的20名健康对照者(样本量、年龄和性别匹配)。在此,我们比较了基于全脑和基于荟萃分析的疾病特异性感兴趣区域方法进行支持向量机分类的效果。我们还使用支持向量机分类来区分三种PPA亚型。全脑支持向量机分类在识别特定PPA亚型与健康对照者之间的准确率非常高,在91%至97%之间,而在区分语义型与非流利/语法缺失型或音韵性失写型PPA变体方面的准确率为78/95%。仅在区分非流利/语法缺失型和音韵性失写型PPA变体时准确率较低,为55%。有趣的是,对患者支持向量机分类贡献最大的区域在很大程度上与组间比较显示的这些患者萎缩的区域相对应。尽管全脑方法也考虑了感兴趣区域方法未涵盖的区域,但由于所选网络的疾病特异性,两种方法显示出相似的准确率。结论是,对多中心结构磁共振成像数据进行支持向量机分类能够以非常高的准确率预测PPA亚型,为其在临床环境中的应用铺平了道路。