Torlay L, Perrone-Bertolotti M, Thomas E, Baciu M
CNRS LPNC UMR 5105, Univ. Grenoble Alpes, 380000, Grenoble, France.
Laboratoire INSERM U1093, Université de Bourgogne, 21000, Dijon, France.
Brain Inform. 2017 Sep;4(3):159-169. doi: 10.1007/s40708-017-0065-7. Epub 2017 Apr 22.
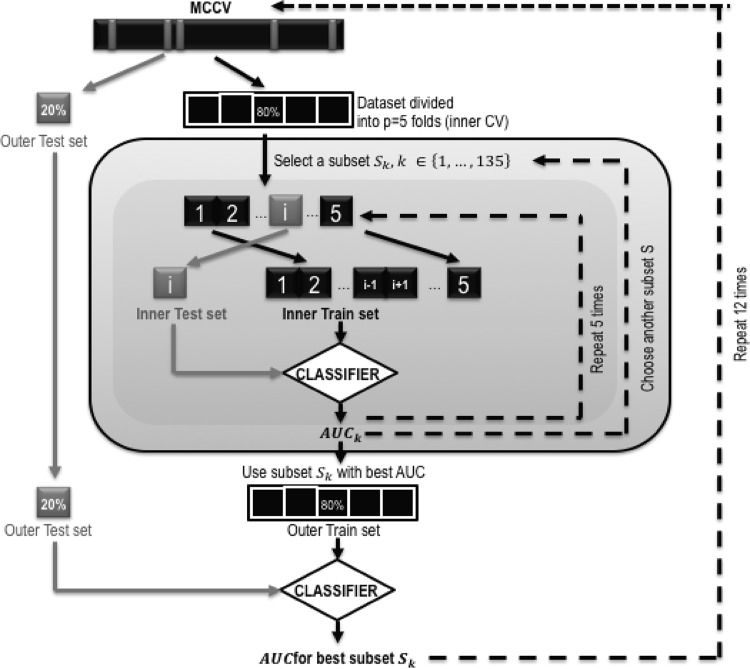
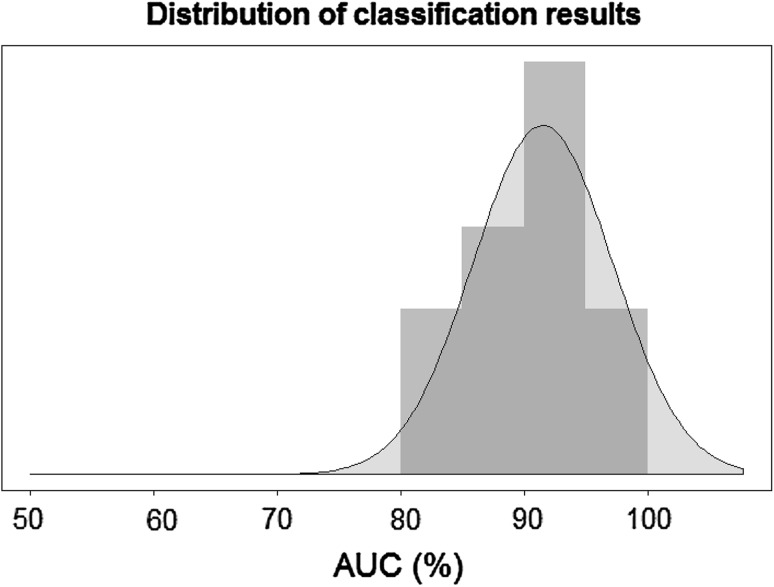
Our goal was to apply a statistical approach to allow the identification of atypical language patterns and to differentiate patients with epilepsy from healthy subjects, based on their cerebral activity, as assessed by functional MRI (fMRI). Patients with focal epilepsy show reorganization or plasticity of brain networks involved in cognitive functions, inducing 'atypical' (compared to 'typical' in healthy people) brain profiles. Moreover, some of these patients suffer from drug-resistant epilepsy, and they undergo surgery to stop seizures. The neurosurgeon should only remove the zone generating seizures and must preserve cognitive functions to avoid deficits. To preserve functions, one should know how they are represented in the patient's brain, which is in general different from that of healthy subjects. For this purpose, in the pre-surgical stage, robust and efficient methods are required to identify atypical from typical representations. Given the frequent location of regions generating seizures in the vicinity of language networks, one important function to be considered is language. The risk of language impairment after surgery is determined pre-surgically by mapping language networks. In clinical settings, cognitive mapping is classically performed with fMRI. The fMRI analyses allowing the identification of atypical patterns of language networks in patients are not sufficiently robust and require additional statistic approaches. In this study, we report the use of a statistical nonlinear machine learning classification, the Extreme Gradient Boosting (XGBoost) algorithm, to identify atypical patterns and classify 55 participants as healthy subjects or patients with epilepsy. XGBoost analyses were based on neurophysiological features in five language regions (three frontal and two temporal) in both hemispheres and activated with fMRI for a phonological (PHONO) and a semantic (SEM) language task. These features were combined into 135 cognitively plausible subsets and further submitted to selection and binary classification. Classification performance was scored with the Area Under the receiver operating characteristic curve (AUC). Our results showed that the subset SEM_LH BA_47-21 (left fronto-temporal activation induced by the SEM task) provided the best discrimination between the two groups (AUC of 91 ± 5%). The results are discussed in the framework of the current debates of language reorganization in focal epilepsy.
我们的目标是应用一种统计方法,以便基于功能磁共振成像(fMRI)评估的大脑活动,识别非典型语言模式,并区分癫痫患者与健康受试者。局灶性癫痫患者表现出参与认知功能的脑网络重组或可塑性,导致(与健康人“典型”情况相比)“非典型”脑图谱。此外,这些患者中的一些患有药物难治性癫痫,他们会接受手术以停止癫痫发作。神经外科医生应仅切除产生癫痫发作的区域,并且必须保留认知功能以避免缺陷。为了保留功能,应该了解它们在患者大脑中的表现方式,这通常与健康受试者不同。为此,在手术前阶段,需要强大而有效的方法来从典型表现中识别非典型表现。鉴于产生癫痫发作的区域经常位于语言网络附近,一个需要考虑的重要功能是语言。手术后语言障碍的风险在手术前通过绘制语言网络来确定。在临床环境中,认知图谱经典地通过fMRI进行。能够识别患者语言网络非典型模式的fMRI分析不够稳健,需要额外的统计方法。在本研究中,我们报告了使用统计非线性机器学习分类方法——极端梯度提升(XGBoost)算法,来识别非典型模式并将55名参与者分类为健康受试者或癫痫患者。XGBoost分析基于双侧五个语言区域(三个额叶和两个颞叶)的神经生理特征,并通过fMRI在一个语音(PHONO)和一个语义(SEM)语言任务中激活。这些特征被组合成135个认知上合理的子集,并进一步进行选择和二元分类。分类性能用受试者操作特征曲线下面积(AUC)评分。我们的结果表明,子集SEM_LH BA_47 - 21(由SEM任务诱导的左额颞叶激活)在两组之间提供了最佳区分(AUC为91±5%)。在局灶性癫痫语言重组当前争论的框架内对结果进行了讨论。