King Abdullah University of Science and Technology (KAUST), Computational Bioscience Research Center, Thuwal, 23955-6900, Saudi Arabia.
Sci Rep. 2017 Jun 20;7(1):3898. doi: 10.1038/s41598-017-04281-9.
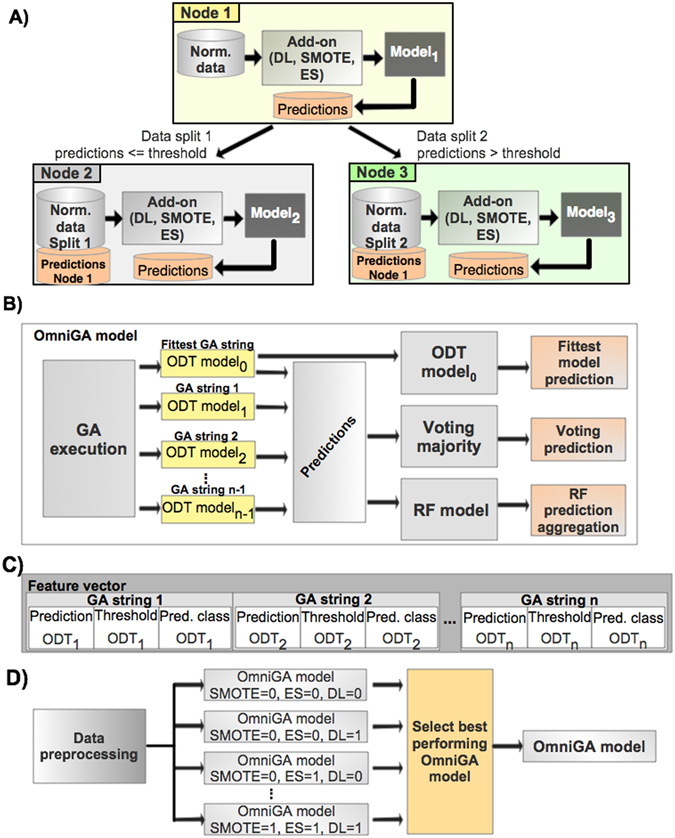
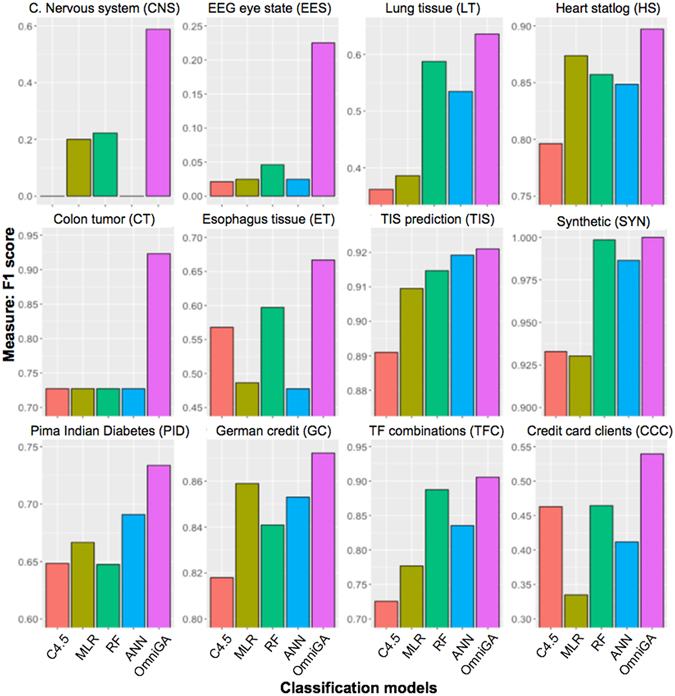
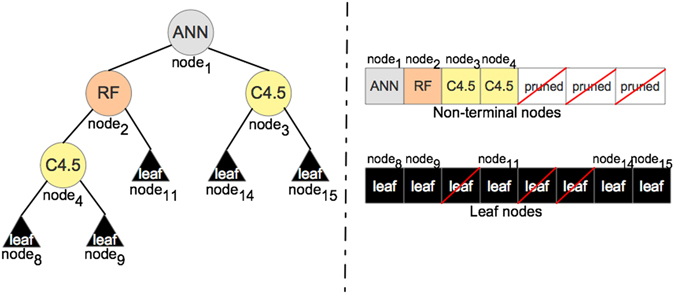
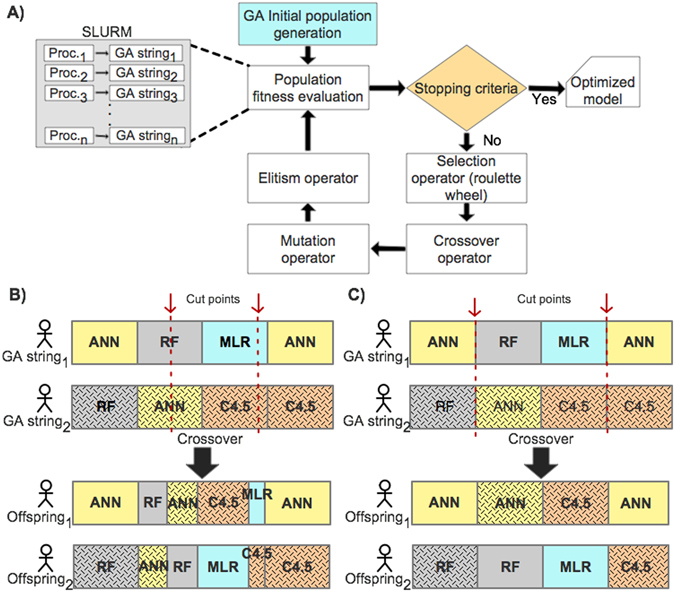
Classification problems from different domains vary in complexity, size, and imbalance of the number of samples from different classes. Although several classification models have been proposed, selecting the right model and parameters for a given classification task to achieve good performance is not trivial. Therefore, there is a constant interest in developing novel robust and efficient models suitable for a great variety of data. Here, we propose OmniGA, a framework for the optimization of omnivariate decision trees based on a parallel genetic algorithm, coupled with deep learning structure and ensemble learning methods. The performance of the OmniGA framework is evaluated on 12 different datasets taken mainly from biomedical problems and compared with the results obtained by several robust and commonly used machine-learning models with optimized parameters. The results show that OmniGA systematically outperformed these models for all the considered datasets, reducing the F score error in the range from 100% to 2.25%, compared to the best performing model. This demonstrates that OmniGA produces robust models with improved performance. OmniGA code and datasets are available at www.cbrc.kaust.edu.sa/omniga/.
不同领域的分类问题在复杂性、规模和不同类别样本数量的不平衡性方面存在差异。尽管已经提出了几种分类模型,但为给定的分类任务选择正确的模型和参数以实现良好的性能并非易事。因此,人们一直有兴趣开发适用于各种数据的新型强大且高效的模型。在这里,我们提出了 OmniGA,这是一种基于并行遗传算法优化单变量决策树的框架,结合了深度学习结构和集成学习方法。我们在 12 个不同的数据集上评估了 OmniGA 框架的性能,这些数据集主要来自生物医学问题,并将结果与经过优化参数的几个稳健且常用的机器学习模型进行了比较。结果表明,对于所有考虑的数据集,OmniGA 系统地优于这些模型,与表现最好的模型相比,F 分数误差降低了 100%到 2.25%。这表明 OmniGA 生成了具有改进性能的稳健模型。OmniGA 的代码和数据集可在 www.cbrc.kaust.edu.sa/omniga/ 上获取。