Henderson Jette, Bridges Ryan, Ho Joyce C, Wallace Byron C, Ghosh Joydeep
The University of Texas at Austin, Austin, TX.
Epic Systems, Verona, WI.
AMIA Jt Summits Transl Sci Proc. 2017 Jul 26;2017:149-157. eCollection 2017.
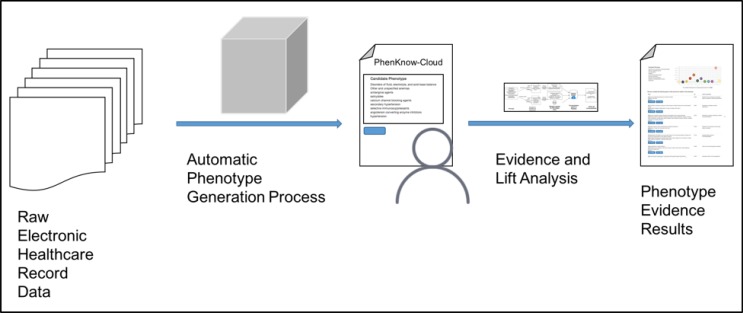
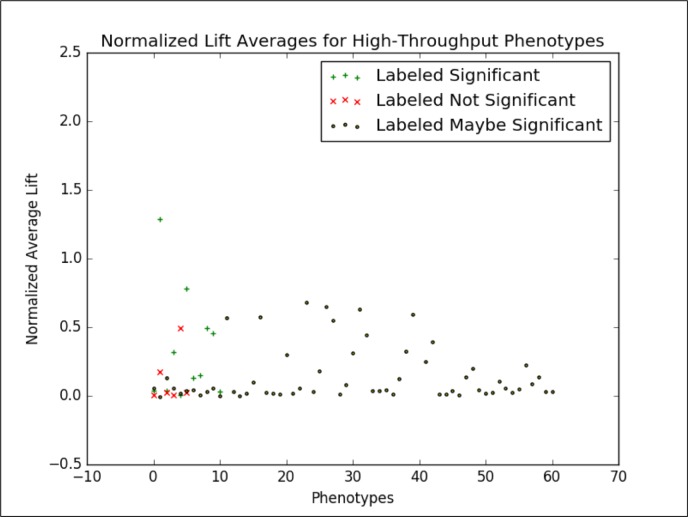
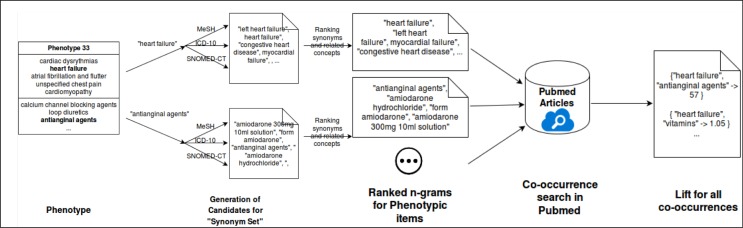
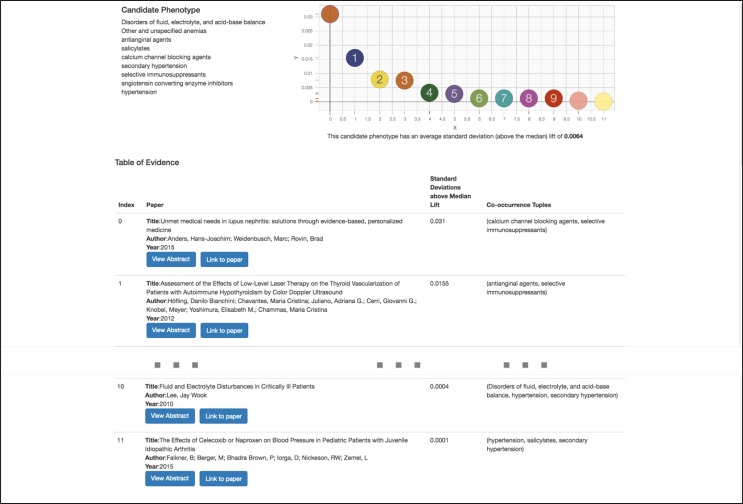
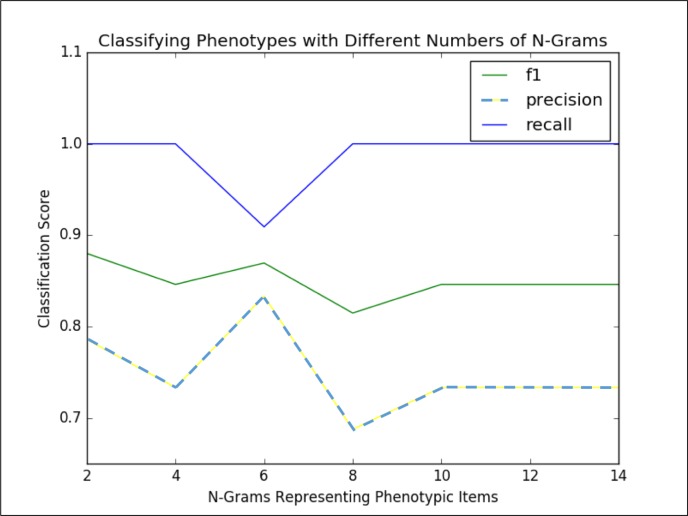
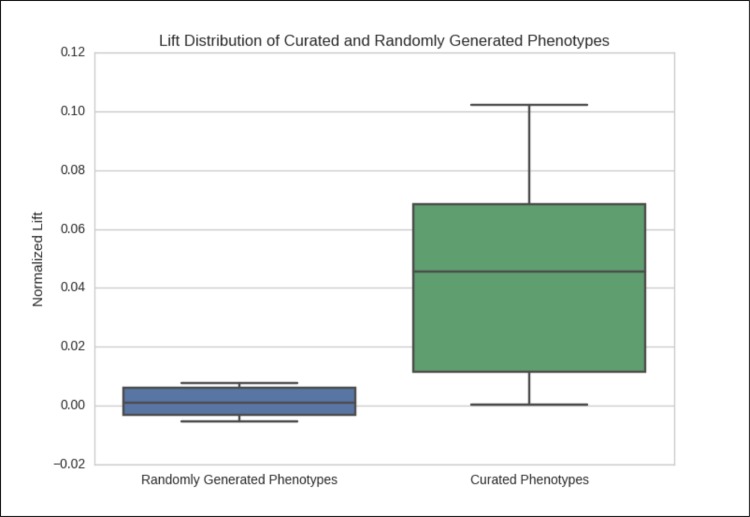
As the adoption of Electronic Healthcare Records has grown, the need to transform manual processes that extract and characterize medical data into automatic and high-throughput processes has also grown. Recently, researchers have tackled the problem of automatically extracting candidate phenotypes from EHR data. Since these phenotypes are usually generated using unsupervised or semi-supervised methods, it is necessary to examine and validate the clinical relevance of the generated "candidate" phenotypes. We present PheKnow-Cloud, a framework that uses co-occurrence analysis on the publicly available, online repository ofjournal articles, PubMed, to build sets of evidence for user-supplied candidate phenotypes. PheKnow-Cloud works in an interactive manner to present the results of the candidate phenotype analysis. This tool seeks to help researchers and clinical professionals evaluate the automatically generated phenotypes so they may tune their processes and understand the candidate phenotypes.
随着电子健康记录的采用日益广泛,将提取和表征医疗数据的手动流程转变为自动且高通量流程的需求也在增加。最近,研究人员着手解决从电子健康记录数据中自动提取候选表型的问题。由于这些表型通常使用无监督或半监督方法生成,因此有必要检查和验证所生成的“候选”表型的临床相关性。我们提出了PheKnow-Cloud,这是一个利用对公开可用的在线期刊文章存储库PubMed进行共现分析的框架,为用户提供的候选表型构建证据集。PheKnow-Cloud以交互方式工作,展示候选表型分析的结果。该工具旨在帮助研究人员和临床专业人员评估自动生成的表型,以便他们调整流程并理解候选表型。