DeMasi Orianna, Kording Konrad, Recht Benjamin
Department of Electrical Engineering and Computer Sciences, University of California, Berkeley, California, United States of America.
Department of Bioengineering, University of Pennsylvania, Philadelphia, Pennsylvania, United States of America.
PLoS One. 2017 Sep 26;12(9):e0184604. doi: 10.1371/journal.pone.0184604. eCollection 2017.
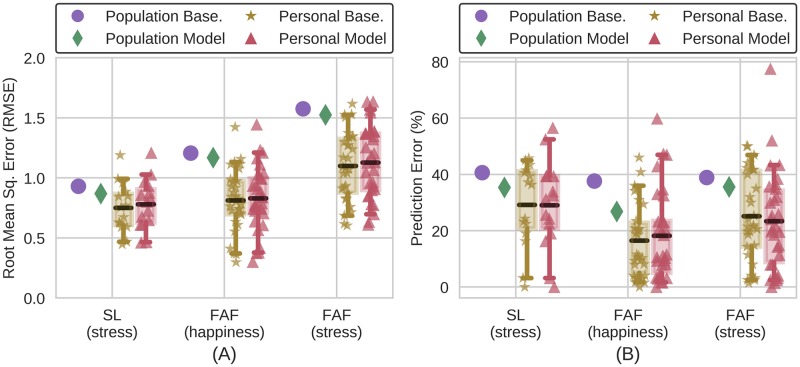
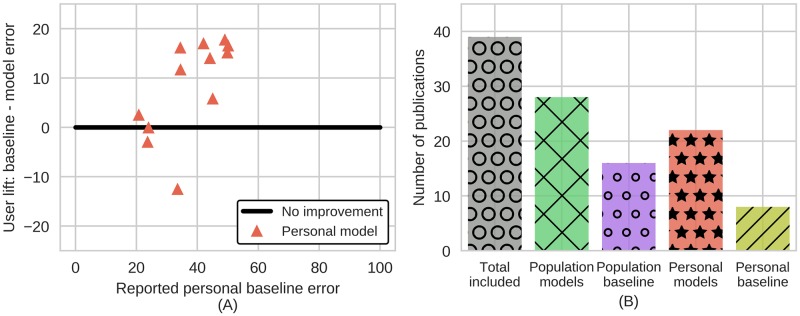
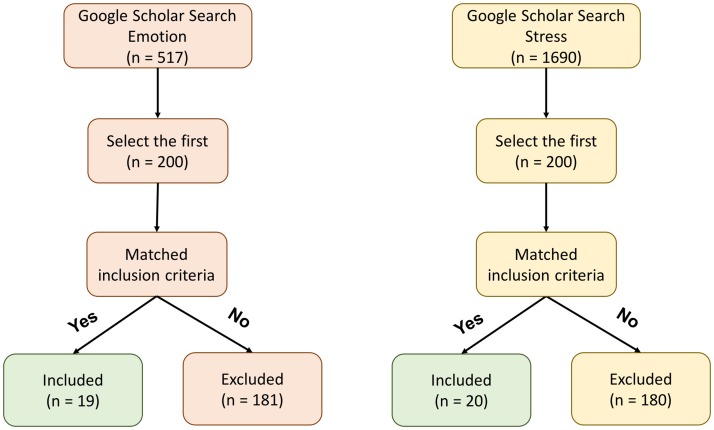
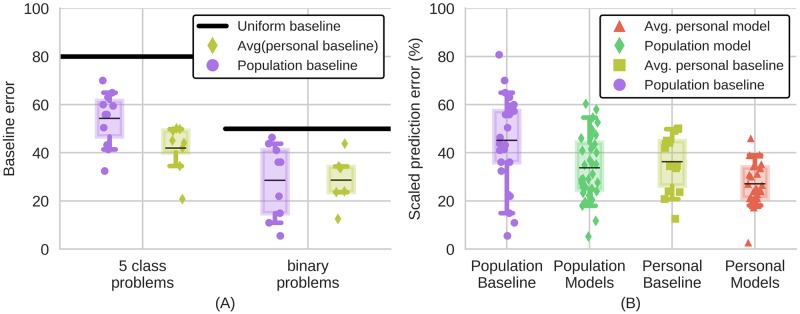
A new trend in medicine is the use of algorithms to analyze big datasets, e.g. using everything your phone measures about you for diagnostics or monitoring. However, these algorithms are commonly compared against weak baselines, which may contribute to excessive optimism. To assess how well an algorithm works, scientists typically ask how well its output correlates with medically assigned scores. Here we perform a meta-analysis to quantify how the literature evaluates their algorithms for monitoring mental wellbeing. We find that the bulk of the literature (∼77%) uses meaningless comparisons that ignore patient baseline state. For example, having an algorithm that uses phone data to diagnose mood disorders would be useful. However, it is possible to explain over 80% of the variance of some mood measures in the population by simply guessing that each patient has their own average mood-the patient-specific baseline. Thus, an algorithm that just predicts that our mood is like it usually is can explain the majority of variance, but is, obviously, entirely useless. Comparing to the wrong (population) baseline has a massive effect on the perceived quality of algorithms and produces baseless optimism in the field. To solve this problem we propose "user lift" that reduces these systematic errors in the evaluation of personalized medical monitoring.
医学领域的一个新趋势是利用算法来分析大型数据集,例如利用手机测量的关于你的所有数据进行诊断或监测。然而,这些算法通常是与较弱的基线进行比较,这可能会导致过度乐观。为了评估算法的效果如何,科学家们通常会询问其输出与医学指定分数的关联程度。在此,我们进行一项荟萃分析,以量化文献中对监测心理健康算法的评估方式。我们发现,大部分文献(约77%)使用的是无意义的比较,忽略了患者的基线状态。例如,有一个利用手机数据诊断情绪障碍的算法可能会很有用。然而,通过简单猜测每个患者都有自己的平均情绪——即患者特定的基线,就有可能解释人群中某些情绪指标超过80%的方差。因此,一个仅仅预测我们的情绪和平时一样的算法可以解释大部分方差,但显然完全没有用处。与错误的(总体)基线进行比较,会对算法的感知质量产生巨大影响,并在该领域产生毫无根据的乐观情绪。为了解决这个问题,我们提出了“用户提升”方法,以减少个性化医疗监测评估中的这些系统误差。