Department of Psychological and Brain Sciences, Dartmouth College, Hanover, NH, 03755, USA.
Department of Neuroscience, Yale School of Medicine, New Haven, CT, 06510, USA.
Nat Commun. 2017 Nov 24;8(1):1768. doi: 10.1038/s41467-017-01874-w.
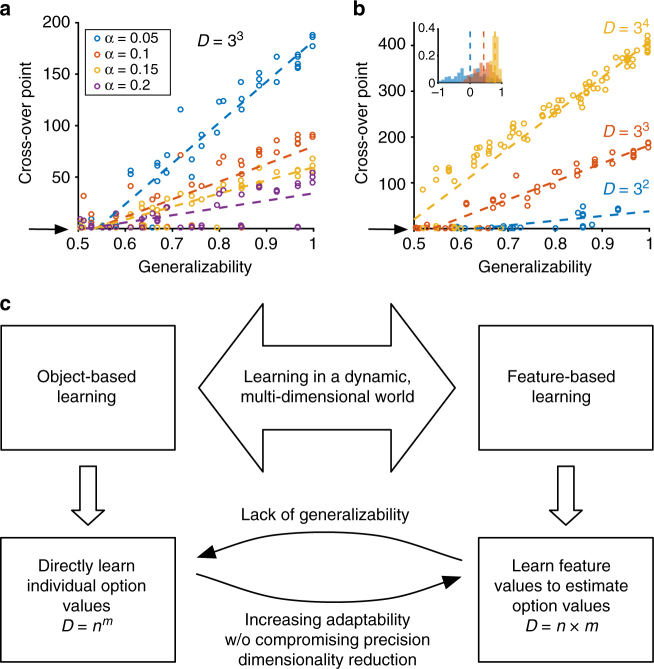
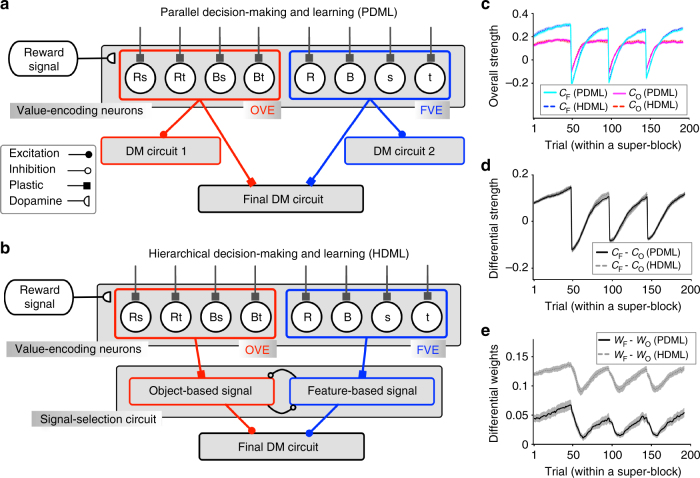
Learning from reward feedback is essential for survival but can become extremely challenging with myriad choice options. Here, we propose that learning reward values of individual features can provide a heuristic for estimating reward values of choice options in dynamic, multi-dimensional environments. We hypothesize that this feature-based learning occurs not just because it can reduce dimensionality, but more importantly because it can increase adaptability without compromising precision of learning. We experimentally test this hypothesis and find that in dynamic environments, human subjects adopt feature-based learning even when this approach does not reduce dimensionality. Even in static, low-dimensional environments, subjects initially adopt feature-based learning and gradually switch to learning reward values of individual options, depending on how accurately objects' values can be predicted by combining feature values. Our computational models reproduce these results and highlight the importance of neurons coding feature values for parallel learning of values for features and objects.
从奖励反馈中学习对于生存至关重要,但在面临无数选择时,这可能变得极具挑战性。在这里,我们提出,学习单个特征的奖励值可以为在动态、多维环境中估计选择选项的奖励值提供一种启发式方法。我们假设这种基于特征的学习不仅因为它可以降低维度,而且更重要的是,因为它可以在不影响学习精度的情况下提高适应性。我们通过实验检验了这一假设,结果发现,在动态环境中,人类受试者采用基于特征的学习,即使这种方法不能降低维度。即使在静态、低维环境中,受试者最初也采用基于特征的学习,然后根据通过组合特征值来准确预测对象值的能力,逐渐切换到学习各个选项的奖励值。我们的计算模型再现了这些结果,并强调了编码特征值的神经元对于特征和对象值的并行学习的重要性。