Department of Data Sciences and Operations, Marshall School of Business, University of Southern California, Los Angeles, CA 90089, USA.
Department of Statistics, Columbia University, New York, NY 10027-5927, USA.
Sci Adv. 2018 Feb 2;4(2):eaao1659. doi: 10.1126/sciadv.aao1659. eCollection 2018 Feb.
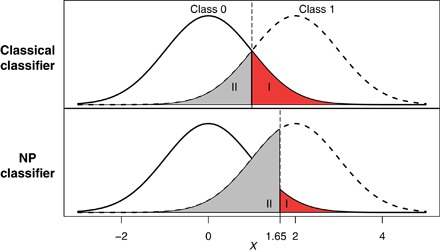
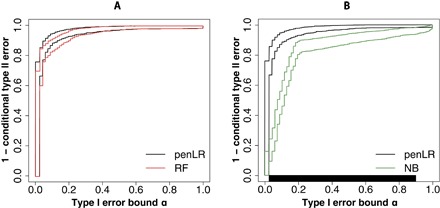
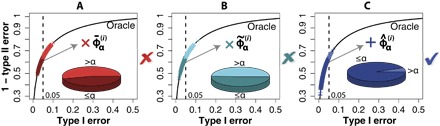
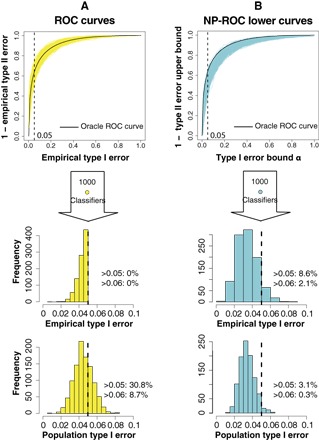
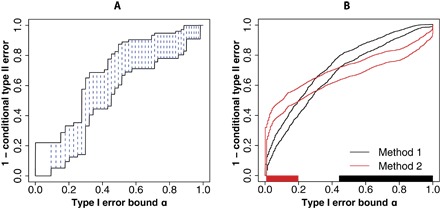
In many binary classification applications, such as disease diagnosis and spam detection, practitioners commonly face the need to limit type I error (that is, the conditional probability of misclassifying a class 0 observation as class 1) so that it remains below a desired threshold. To address this need, the Neyman-Pearson (NP) classification paradigm is a natural choice; it minimizes type II error (that is, the conditional probability of misclassifying a class 1 observation as class 0) while enforcing an upper bound, α, on the type I error. Despite its century-long history in hypothesis testing, the NP paradigm has not been well recognized and implemented in classification schemes. Common practices that directly limit the empirical type I error to no more than α do not satisfy the type I error control objective because the resulting classifiers are likely to have type I errors much larger than α, and the NP paradigm has not been properly implemented in practice. We develop the first umbrella algorithm that implements the NP paradigm for all scoring-type classification methods, such as logistic regression, support vector machines, and random forests. Powered by this algorithm, we propose a novel graphical tool for NP classification methods: NP receiver operating characteristic (NP-ROC) bands motivated by the popular ROC curves. NP-ROC bands will help choose α in a data-adaptive way and compare different NP classifiers. We demonstrate the use and properties of the NP umbrella algorithm and NP-ROC bands, available in the R package nproc, through simulation and real data studies.
在许多二分类应用中,如疾病诊断和垃圾邮件检测,从业者通常需要将第一类错误(即错误地将 0 类观测值分类为 1 类的条件概率)限制在一个期望的阈值以下。为了满足这一需求,Neyman-Pearson(NP)分类范式是一个自然的选择;它在强制限制第一类错误(即错误地将 1 类观测值分类为 0 类的条件概率)的同时,最小化第二类错误(即错误地将 1 类观测值分类为 0 类的条件概率)。尽管在假设检验方面已经有了一个世纪的历史,但 NP 范式在分类方案中并没有得到很好的认可和实施。直接将经验第一类错误限制在不超过α的常见做法并不能满足第一类错误控制目标,因为由此产生的分类器很可能具有远大于α的第一类错误,并且 NP 范式在实践中没有得到正确实施。我们开发了第一个用于所有评分型分类方法的 NP 范式的伞式算法,例如逻辑回归、支持向量机和随机森林。基于这个算法,我们提出了一个新的 NP 分类方法的图形工具:基于流行的 ROC 曲线的 NP 接收器操作特性(NP-ROC)带。NP-ROC 带将帮助以数据自适应的方式选择α,并比较不同的 NP 分类器。我们通过模拟和真实数据研究展示了 NP 伞式算法和 NP-ROC 带的用途和特性,这些工具可在 R 包 nproc 中使用。