Agrawal Piyush, Bhalla Sherry, Chaudhary Kumardeep, Kumar Rajesh, Sharma Meenu, Raghava Gajendra P S
Council of Scientific and Industrial Research, Institute of Microbial Technology, Chandigarh, India.
Center for Computational Biology, Indraprastha Institute of Information Technology, New Delhi, India.
Front Microbiol. 2018 Feb 26;9:323. doi: 10.3389/fmicb.2018.00323. eCollection 2018.
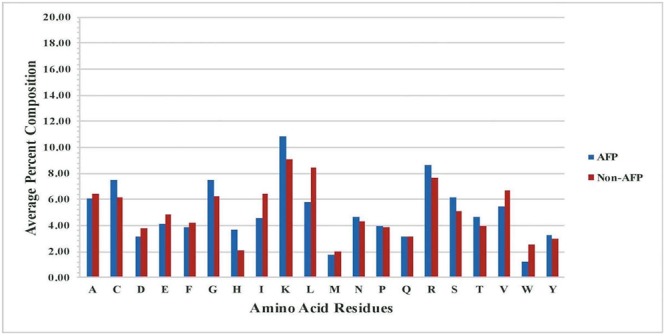
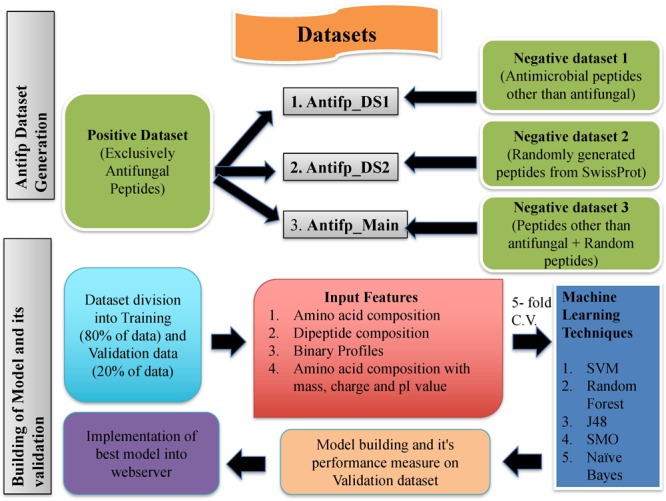
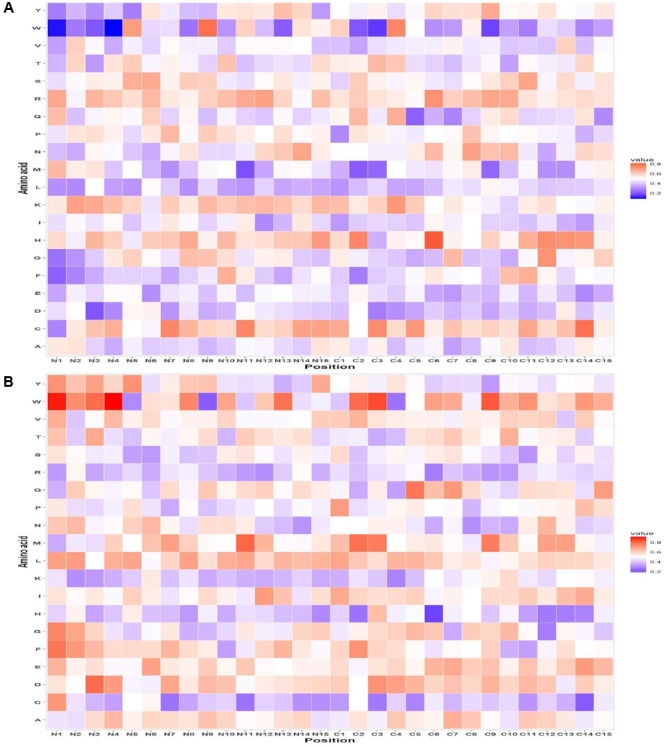
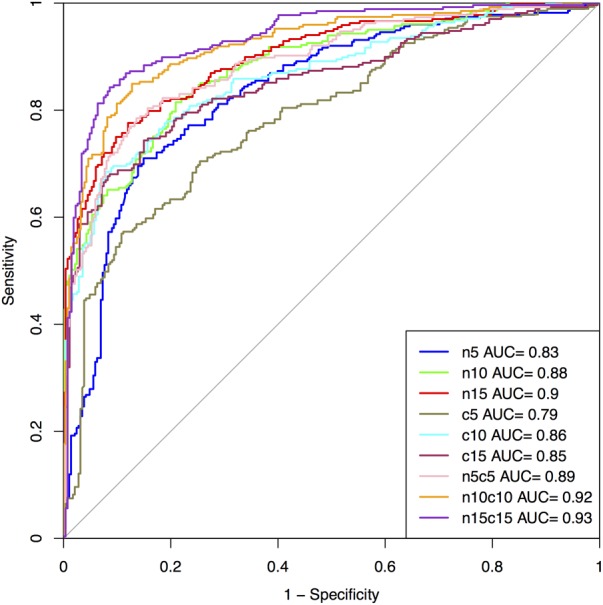
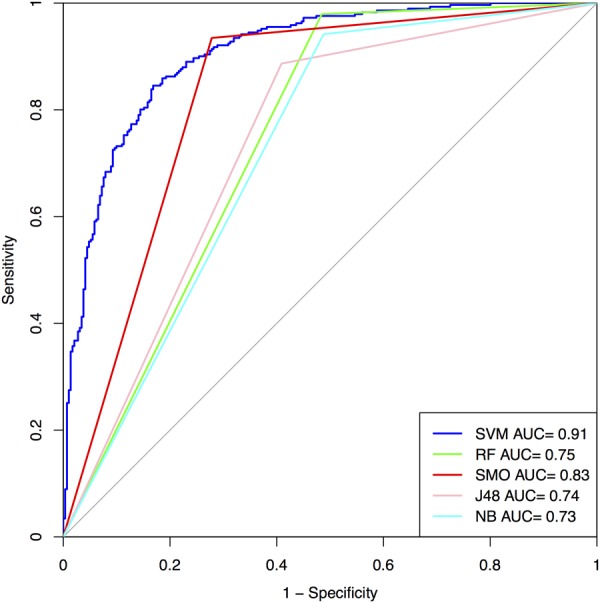
This paper describes models developed using a wide range of peptide features for predicting antifungal peptides (AFPs). Our analyses indicate that certain types of residue (e.g., C, G, H, K, R, Y) are more abundant in AFPs. The positional residue preference analysis reveals the prominence of the particular type of residues (e.g., R, V, K) at N-terminus and a certain type of residues (e.g., C, H) at C-terminus. In this study, models have been developed for predicting AFPs using a wide range of peptide features (like residue composition, binary profile, terminal residues). The support vector machine based model developed using compositional features of peptides achieved maximum accuracy of 88.78% on the training dataset and 83.33% on independent or validation dataset. Our model developed using binary patterns of terminal residues of peptides achieved maximum accuracy of 84.88% on training and 84.64% on validation dataset. We benchmark models developed in this study and existing methods on a dataset containing compositionally similar antifungal and non-AFPs. It was observed that binary based model developed in this study preforms better than any model/method. In order to facilitate scientific community, we developed a mobile app, standalone and a user-friendly web server 'Antifp' (http://webs.iiitd.edu.in/raghava/antifp).
本文描述了利用多种肽特征开发的用于预测抗真菌肽(AFP)的模型。我们的分析表明,某些类型的残基(如C、G、H、K、R、Y)在抗真菌肽中更为丰富。位置残基偏好分析揭示了特定类型残基(如R、V、K)在N端的突出地位以及特定类型残基(如C、H)在C端的突出地位。在本研究中,已利用多种肽特征(如残基组成、二元图谱、末端残基)开发了用于预测抗真菌肽的模型。使用肽的组成特征开发的基于支持向量机的模型在训练数据集上的最大准确率为88.78%,在独立或验证数据集上为83.33%。我们使用肽末端残基的二元模式开发的模型在训练集上的最大准确率为84.88%,在验证数据集上为84.64%。我们在一个包含组成相似的抗真菌肽和非抗真菌肽的数据集上对本研究中开发的模型和现有方法进行了基准测试。结果发现,本研究中开发的基于二元模式的模型比任何模型/方法的性能都更好。为了方便科学界,我们开发了一个移动应用程序、一个独立的且用户友好的网络服务器“Antifp”(http://webs.iiitd.edu.in/raghava/antifp)。