Wu Zhenqin, Ramsundar Bharath, Feinberg Evan N, Gomes Joseph, Geniesse Caleb, Pappu Aneesh S, Leswing Karl, Pande Vijay
Department of Chemistry , Stanford University , Stanford , CA 94305 , USA . Email:
Department of Computer Science , Stanford University , Stanford , CA 94305 , USA.
Chem Sci. 2017 Oct 31;9(2):513-530. doi: 10.1039/c7sc02664a. eCollection 2018 Jan 14.
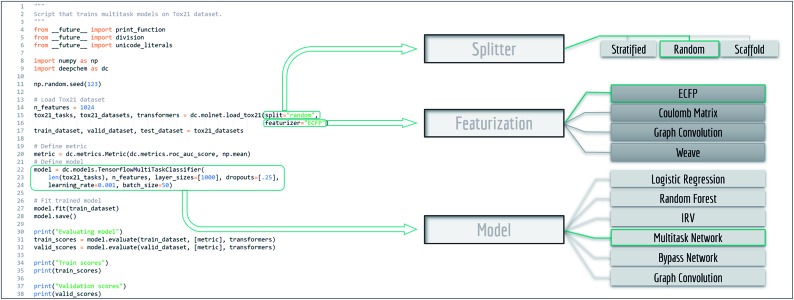
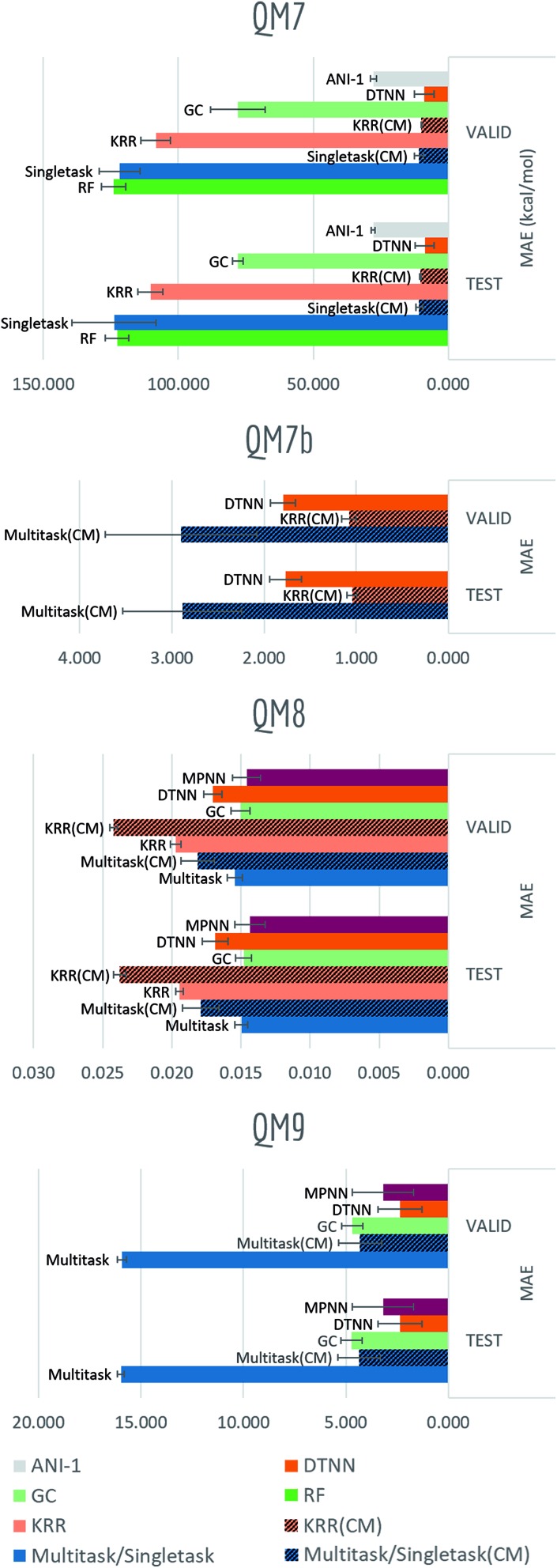
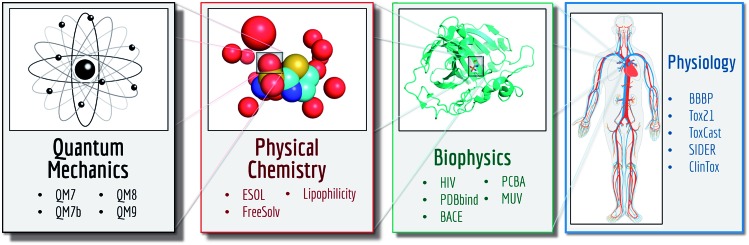
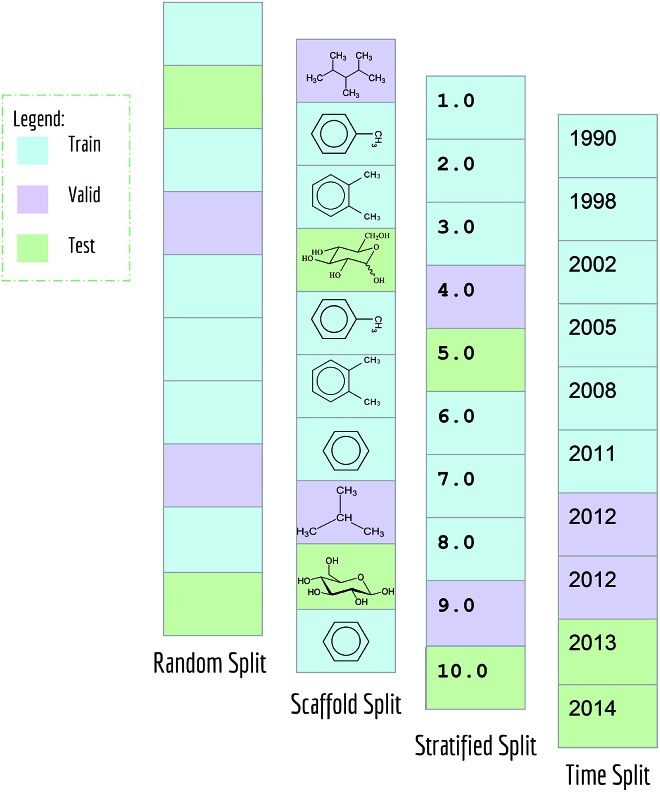
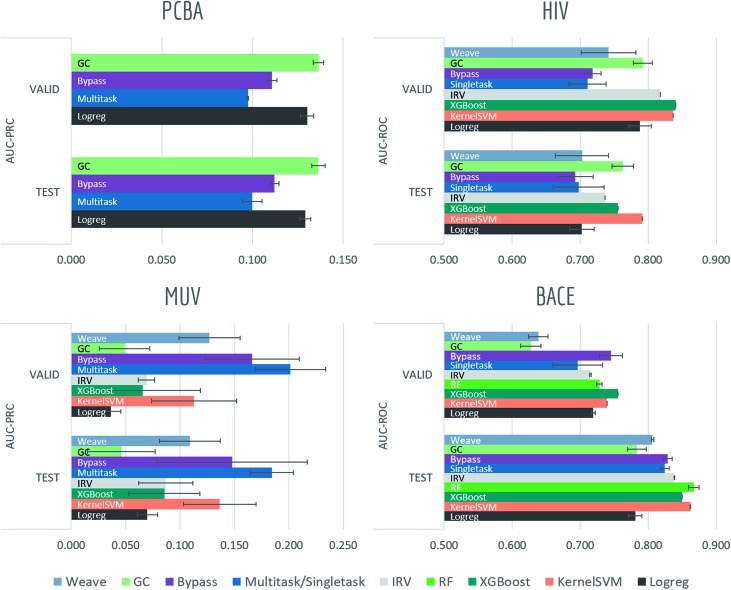
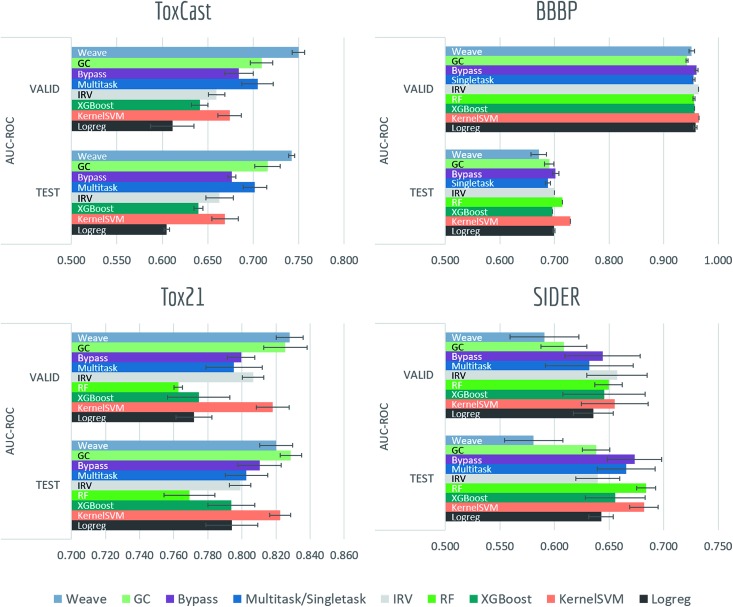
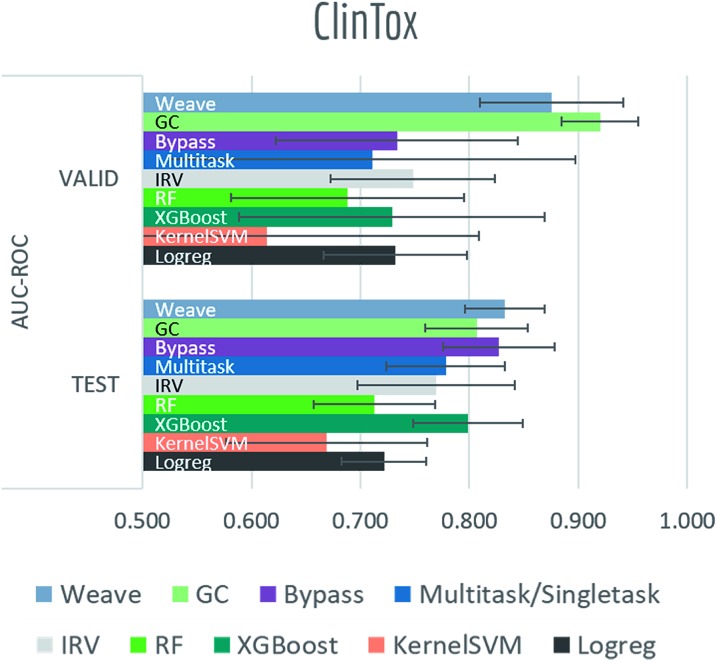
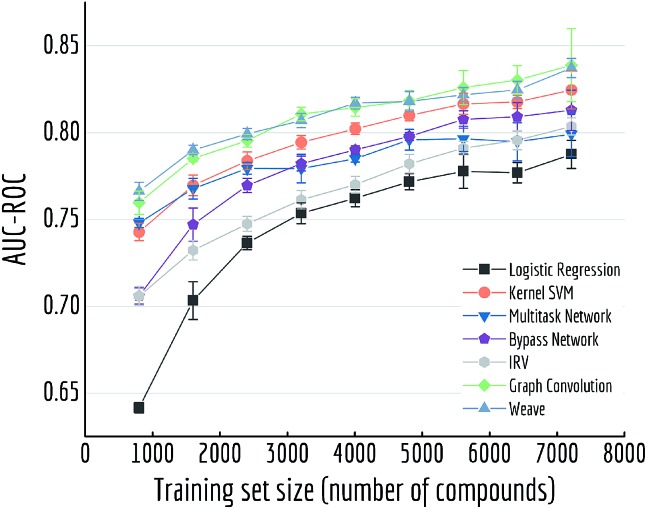
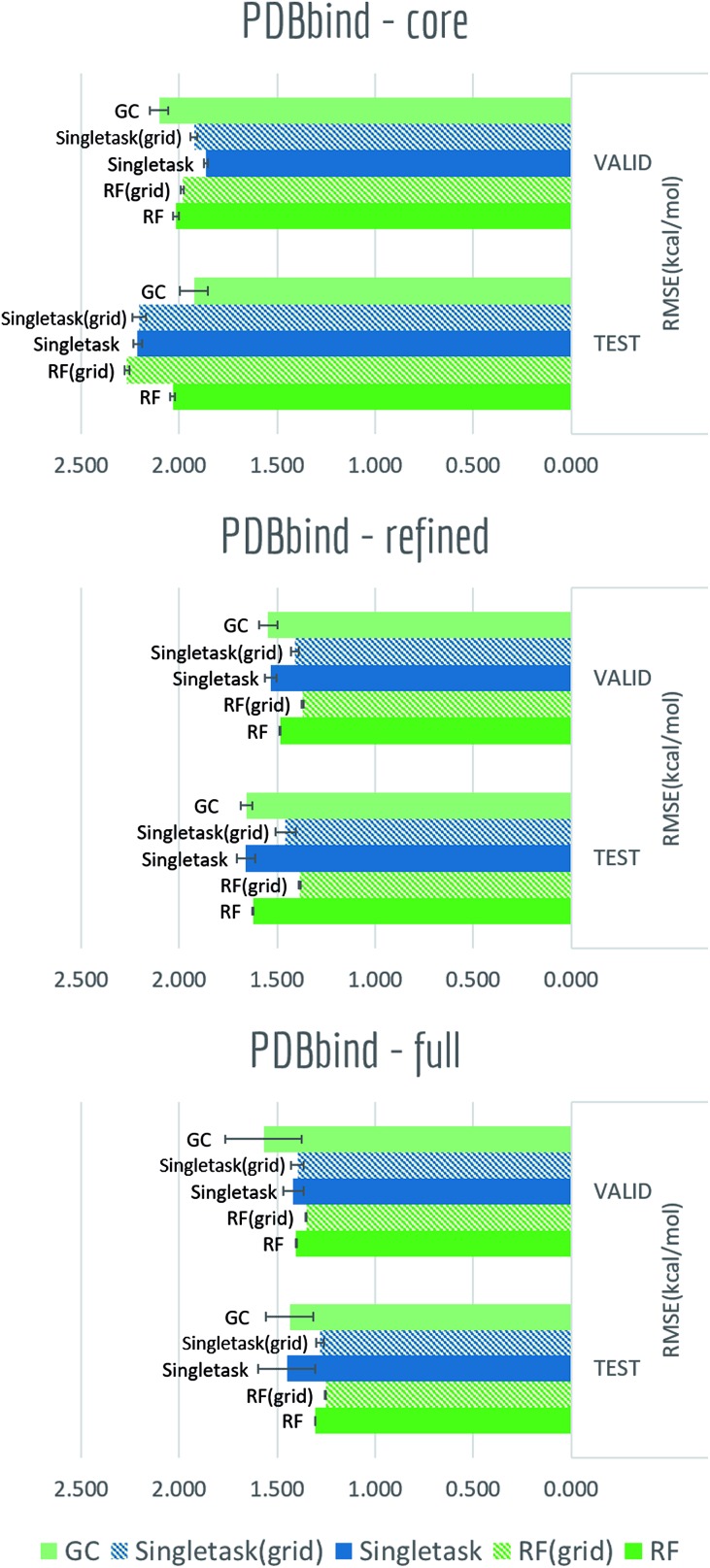
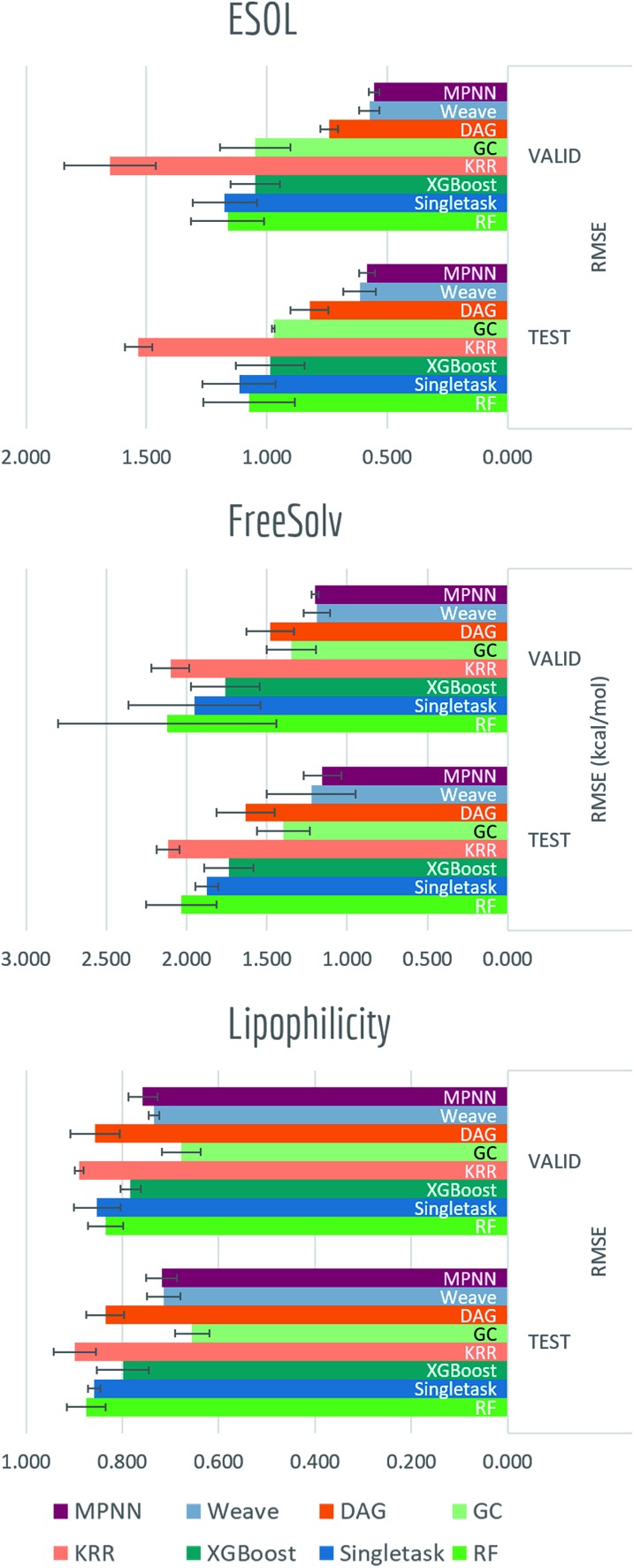
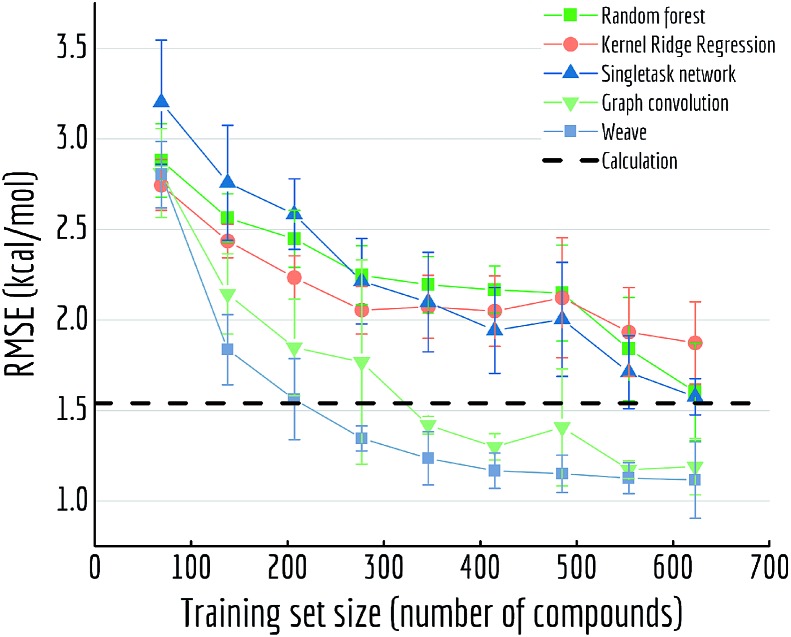
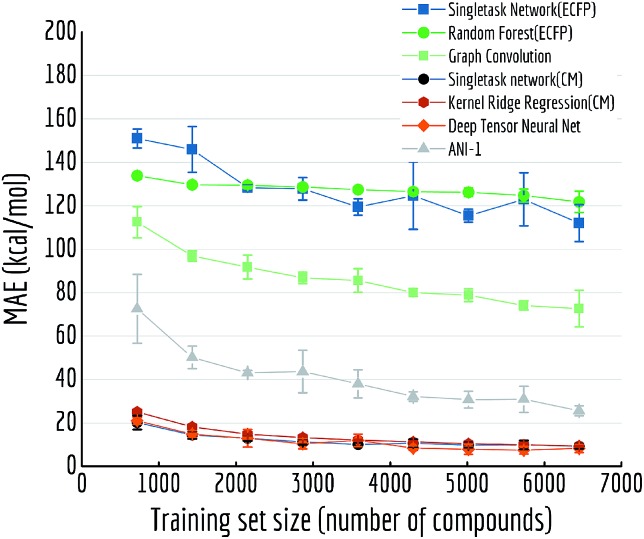
Molecular machine learning has been maturing rapidly over the last few years. Improved methods and the presence of larger datasets have enabled machine learning algorithms to make increasingly accurate predictions about molecular properties. However, algorithmic progress has been limited due to the lack of a standard benchmark to compare the efficacy of proposed methods; most new algorithms are benchmarked on different datasets making it challenging to gauge the quality of proposed methods. This work introduces MoleculeNet, a large scale benchmark for molecular machine learning. MoleculeNet curates multiple public datasets, establishes metrics for evaluation, and offers high quality open-source implementations of multiple previously proposed molecular featurization and learning algorithms (released as part of the DeepChem open source library). MoleculeNet benchmarks demonstrate that learnable representations are powerful tools for molecular machine learning and broadly offer the best performance. However, this result comes with caveats. Learnable representations still struggle to deal with complex tasks under data scarcity and highly imbalanced classification. For quantum mechanical and biophysical datasets, the use of physics-aware featurizations can be more important than choice of particular learning algorithm.
在过去几年中,分子机器学习发展迅速。改进的方法和更大数据集的出现使机器学习算法能够对分子性质做出越来越准确的预测。然而,由于缺乏用于比较所提出方法有效性的标准基准,算法进展受到限制;大多数新算法在不同数据集上进行基准测试,这使得评估所提出方法的质量具有挑战性。这项工作引入了MoleculeNet,这是一个用于分子机器学习的大规模基准。MoleculeNet精心整理了多个公共数据集,建立了评估指标,并提供了多个先前提出的分子特征化和学习算法的高质量开源实现(作为DeepChem开源库的一部分发布)。MoleculeNet基准测试表明,可学习表示是分子机器学习的强大工具,并且总体上提供了最佳性能。然而,这一结果也有需要注意的地方。在数据稀缺和高度不平衡分类的情况下,可学习表示在处理复杂任务时仍然存在困难。对于量子力学和生物物理数据集,使用物理感知特征化可能比选择特定的学习算法更为重要。