Department of Computer Science, KU Leuven, Leuven, Belgium.
Department of Public Health and Primary Care, KU Leuven Kulak, Kortrijk, Belgium.
PLoS Comput Biol. 2018 Apr 23;14(4):e1006097. doi: 10.1371/journal.pcbi.1006097. eCollection 2018 Apr.
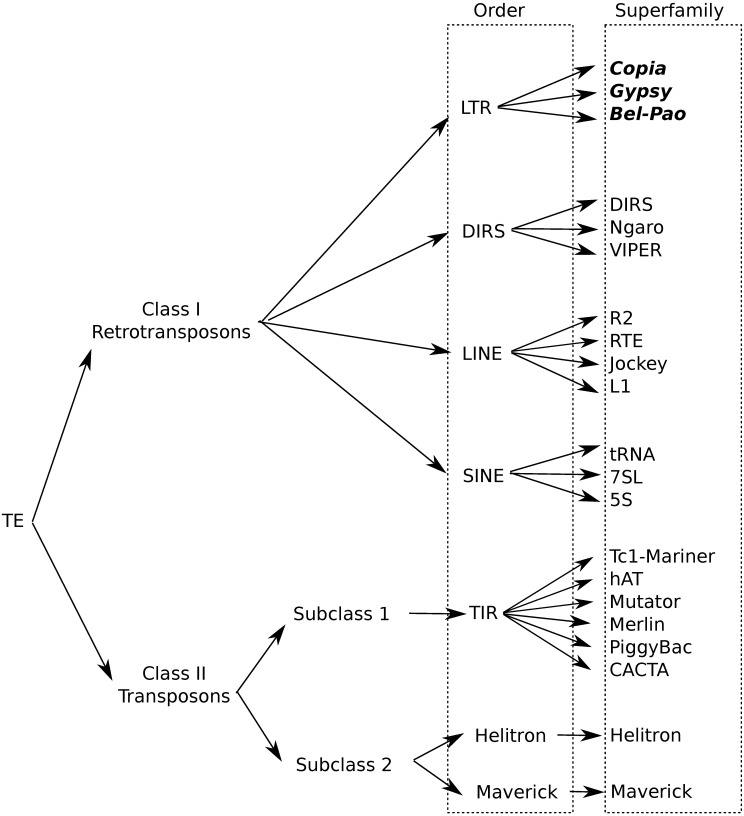
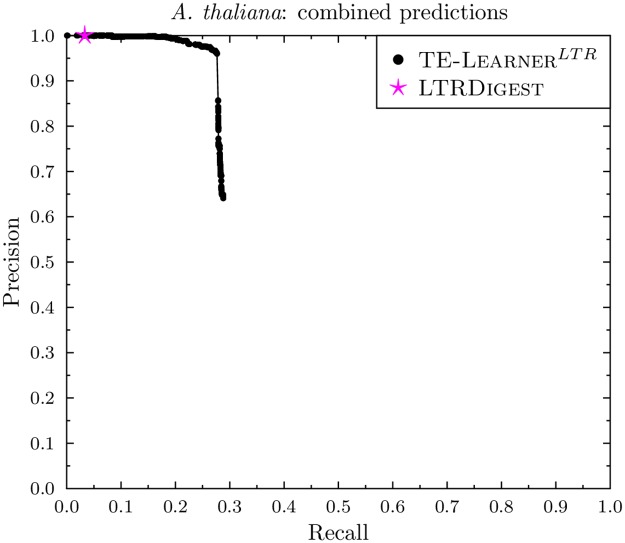
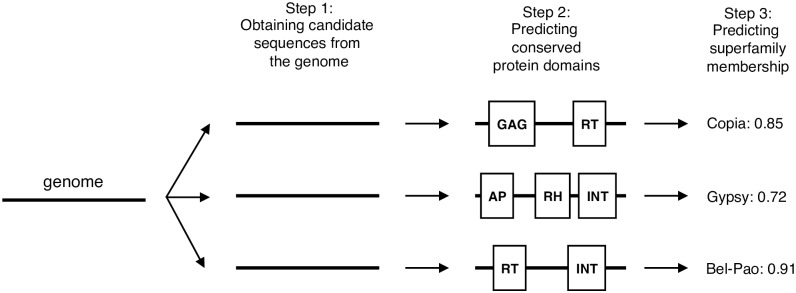
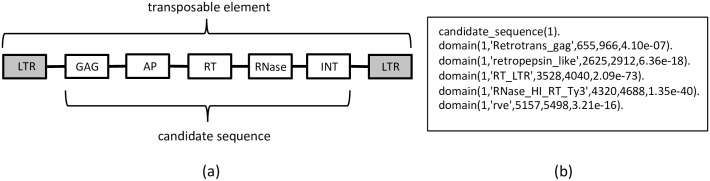
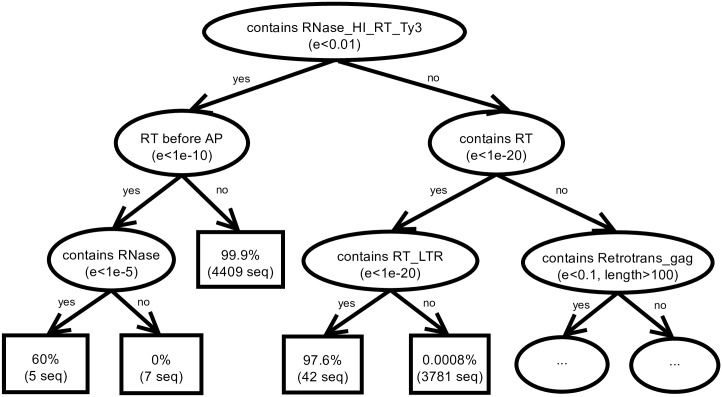
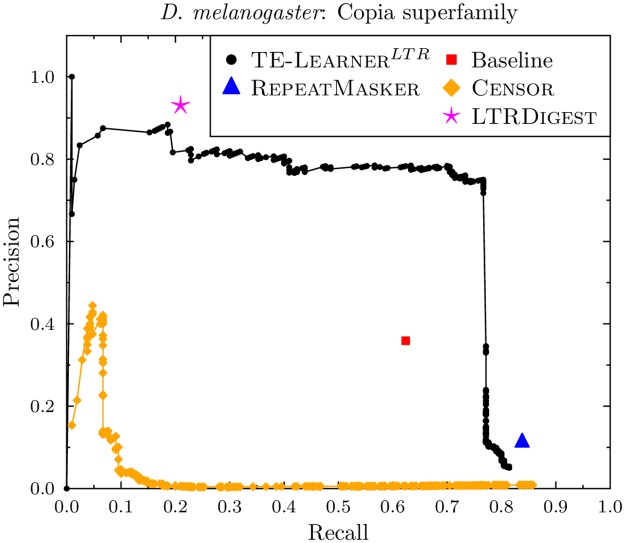
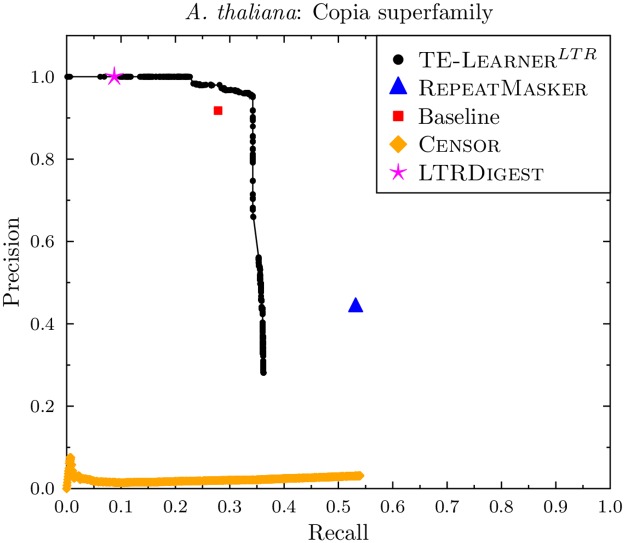
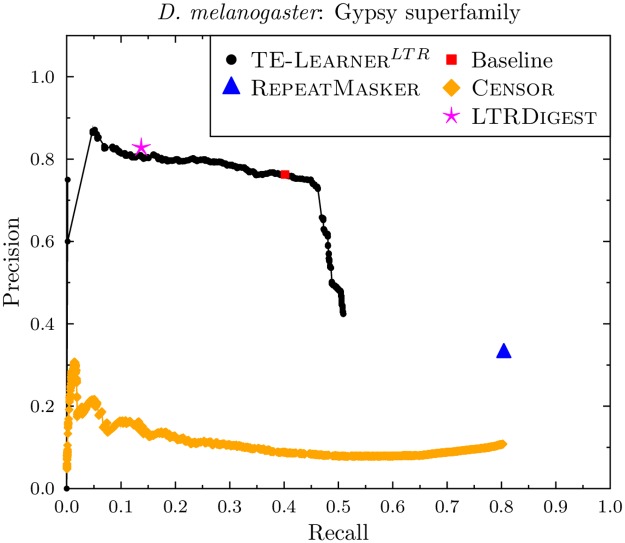
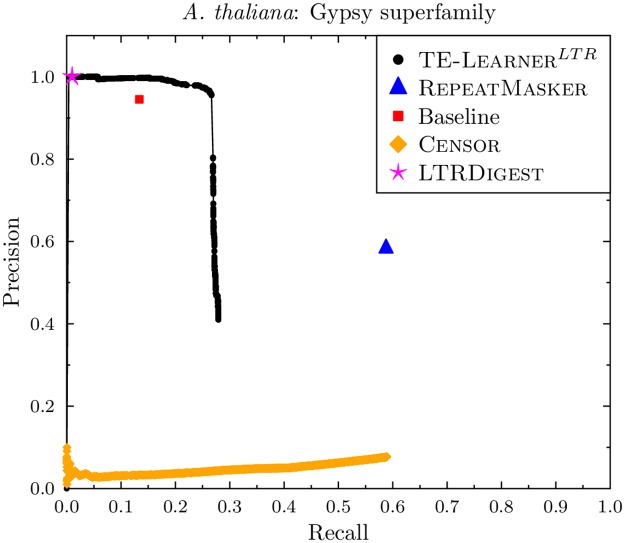
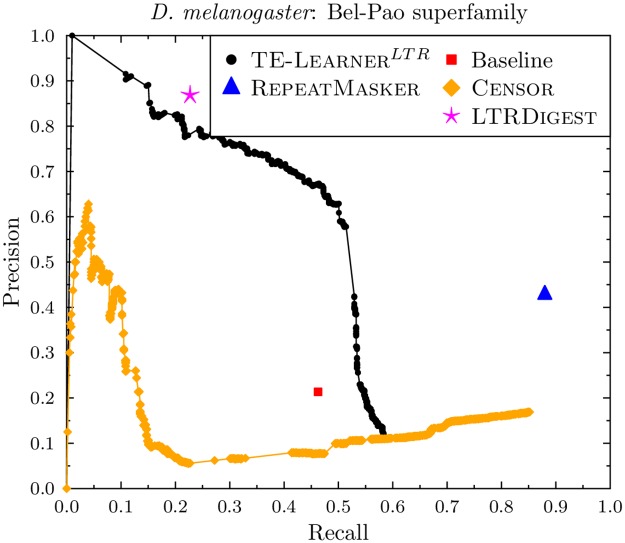
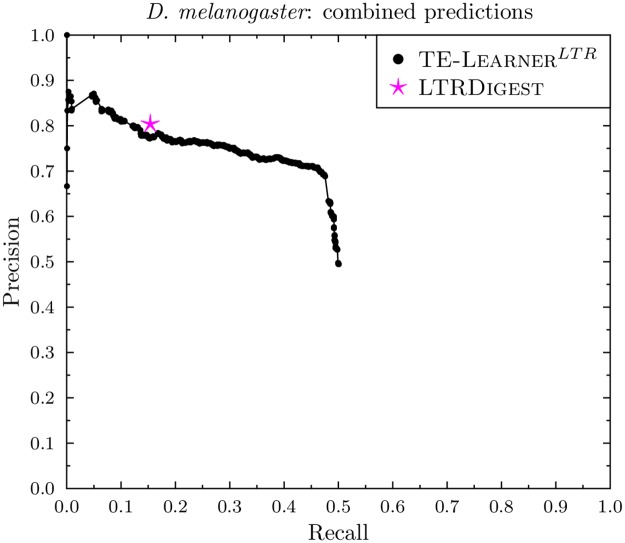
Transposable elements (TEs) are repetitive nucleotide sequences that make up a large portion of eukaryotic genomes. They can move and duplicate within a genome, increasing genome size and contributing to genetic diversity within and across species. Accurate identification and classification of TEs present in a genome is an important step towards understanding their effects on genes and their role in genome evolution. We introduce TE-Learner, a framework based on machine learning that automatically identifies TEs in a given genome and assigns a classification to them. We present an implementation of our framework towards LTR retrotransposons, a particular type of TEs characterized by having long terminal repeats (LTRs) at their boundaries. We evaluate the predictive performance of our framework on the well-annotated genomes of Drosophila melanogaster and Arabidopsis thaliana and we compare our results for three LTR retrotransposon superfamilies with the results of three widely used methods for TE identification or classification: RepeatMasker, Censor and LtrDigest. In contrast to these methods, TE-Learner is the first to incorporate machine learning techniques, outperforming these methods in terms of predictive performance, while able to learn models and make predictions efficiently. Moreover, we show that our method was able to identify TEs that none of the above method could find, and we investigated TE-Learner's predictions which did not correspond to an official annotation. It turns out that many of these predictions are in fact strongly homologous to a known TE.
转座元件(TEs)是构成真核生物基因组大部分的重复核苷酸序列。它们可以在基因组内移动和复制,增加基因组大小,并有助于物种内和种间的遗传多样性。准确识别和分类基因组中存在的 TEs 是理解它们对基因的影响及其在基因组进化中的作用的重要步骤。我们引入了 TE-Learner,这是一个基于机器学习的框架,可以自动识别给定基因组中的 TEs 并对其进行分类。我们展示了我们框架的 LTR 反转录转座子实现,这是一种特定类型的 TEs,其特征是在其边界处具有长末端重复(LTRs)。我们在已注释良好的果蝇和拟南芥基因组上评估了我们框架的预测性能,并将我们对三个 LTR 反转录转座子超家族的结果与三种广泛用于 TE 识别或分类的方法的结果进行了比较:RepeatMasker、Censor 和 LtrDigest。与这些方法不同,TE-Learner 是第一个将机器学习技术纳入其中的方法,在预测性能方面优于这些方法,同时能够有效地学习模型并进行预测。此外,我们表明,我们的方法能够识别出上述任何一种方法都无法找到的 TEs,并且我们研究了 TE-Learner 的预测,这些预测与官方注释不对应。事实证明,其中许多预测实际上与已知的 TE 具有很强的同源性。