School of Computer Science and Technology, Hangzhou Dianzi University, China.
King Abdullah University of Science and Technology (KAUST), Saudi Arabia.
Nucleic Acids Res. 2018 Jul 2;46(W1):W432-W437. doi: 10.1093/nar/gky420.
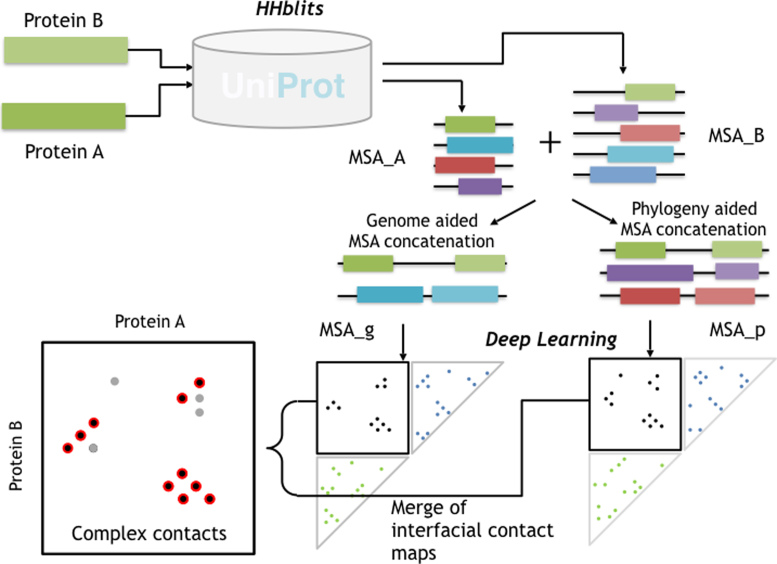
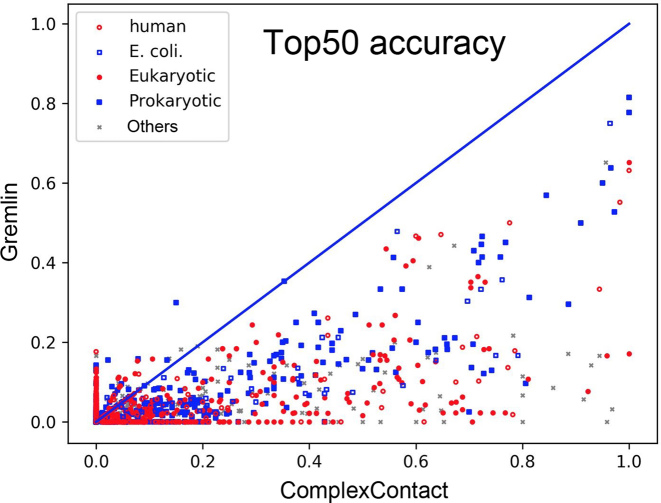
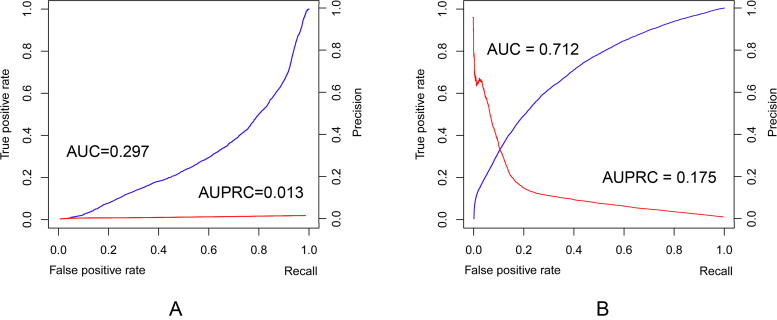
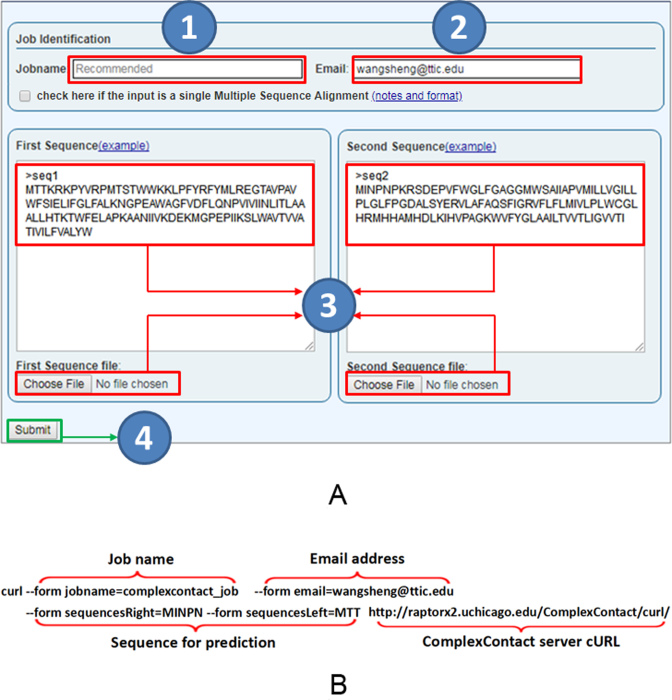
ComplexContact (http://raptorx2.uchicago.edu/ComplexContact/) is a web server for sequence-based interfacial residue-residue contact prediction of a putative protein complex. Interfacial residue-residue contacts are critical for understanding how proteins form complex and interact at residue level. When receiving a pair of protein sequences, ComplexContact first searches for their sequence homologs and builds two paired multiple sequence alignments (MSA), then it applies co-evolution analysis and a CASP-winning deep learning (DL) method to predict interfacial contacts from paired MSAs and visualizes the prediction as an image. The DL method was originally developed for intra-protein contact prediction and performed the best in CASP12. Our large-scale experimental test further shows that ComplexContact greatly outperforms pure co-evolution methods for inter-protein contact prediction, regardless of the species.
ComplexContact(http://raptorx2.uchicago.edu/ComplexContact/)是一个基于序列的预测蛋白质复合物界面残基-残基接触的网络服务器。界面残基-残基接触对于理解蛋白质如何形成复合物以及在残基水平上相互作用至关重要。当接收到一对蛋白质序列时,ComplexContact 首先搜索它们的序列同源物,并构建两个配对的多重序列比对(MSA),然后应用共进化分析和 CASP 获奖的深度学习(DL)方法从配对的 MSA 中预测界面接触,并将预测可视化成图像。DL 方法最初是为蛋白质内接触预测而开发的,并在 CASP12 中表现最好。我们的大规模实验测试还表明,对于蛋白质间接触预测,ComplexContact 大大优于纯共进化方法,无论物种如何。