Joseph Henry Laboratories, Princeton University, Princeton, NJ, USA.
Laboratoire de physique statistique, CNRS, Sorbonne Université, Université Paris-Diderot, and École Normale Supérieure (PSL University), Paris, France.
Immunol Rev. 2018 Jul;284(1):167-179. doi: 10.1111/imr.12665.
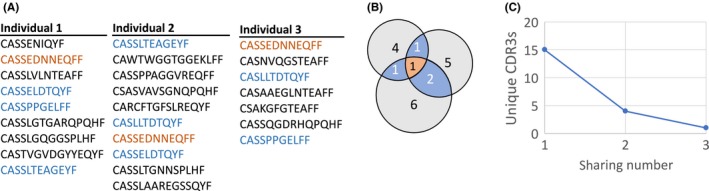
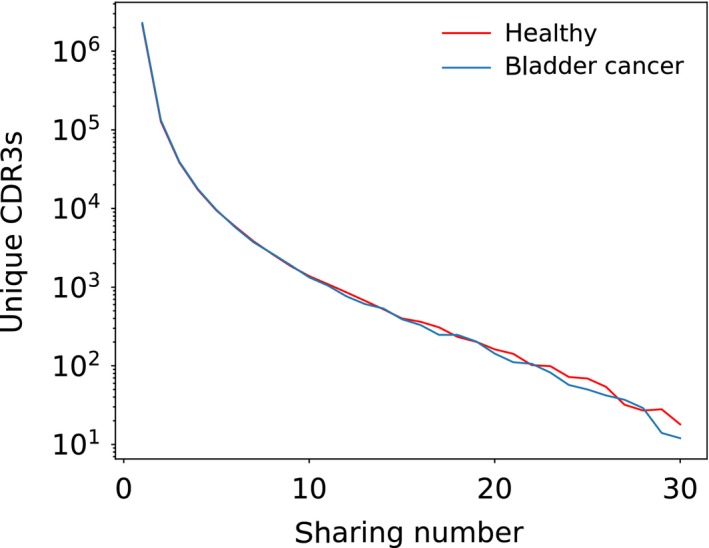
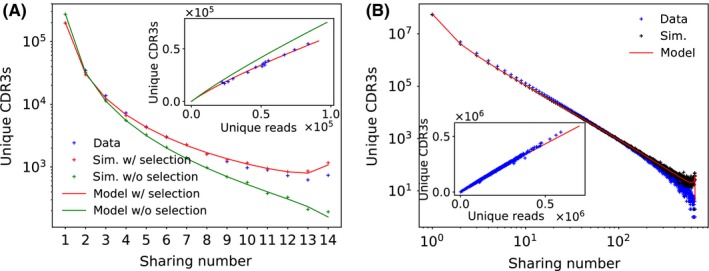
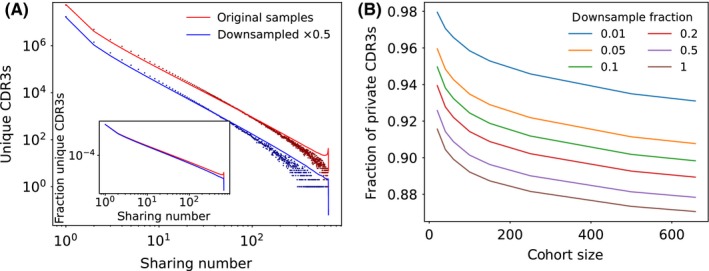
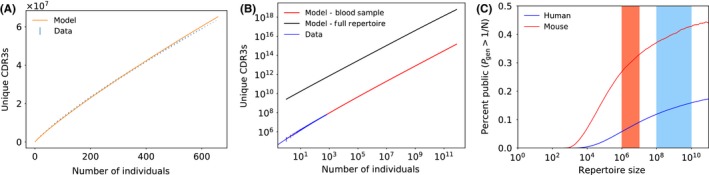
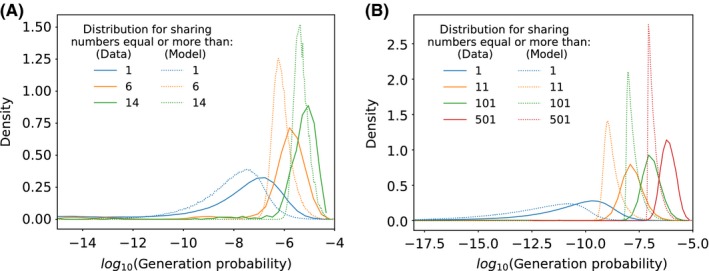
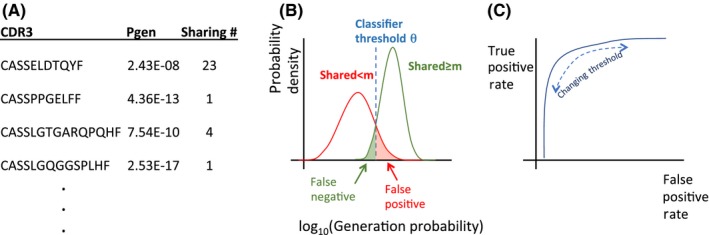
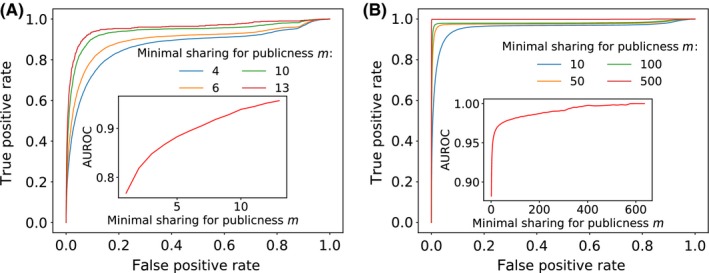
Despite the extreme diversity of T-cell repertoires, many identical T-cell receptor (TCR) sequences are found in a large number of individual mice and humans. These widely shared sequences, often referred to as "public," have been suggested to be over-represented due to their potential immune functionality or their ease of generation by V(D)J recombination. Here, we show that even for large cohorts, the observed degree of sharing of TCR sequences between individuals is well predicted by a model accounting for the known quantitative statistical biases in the generation process, together with a simple model of thymic selection. Whether a sequence is shared by many individuals is predicted to depend on the number of queried individuals and the sampling depth, as well as on the sequence itself, in agreement with the data. We introduce the degree of publicness conditional on the queried cohort size and the size of the sampled repertoires. Based on these observations, we propose a public/private sequence classifier, "PUBLIC" (Public Universal Binary Likelihood Inference Classifier), based on the generation probability, which performs very well even for small cohort sizes.
尽管 T 细胞受体(TCR)的多样性极高,但在大量个体小鼠和人类中发现了许多相同的 TCR 序列。这些广泛共享的序列,通常被称为“公共”,由于其潜在的免疫功能或通过 V(D)J 重组产生的容易性,被认为是过度代表的。在这里,我们表明,即使对于大型队列,个体之间 TCR 序列的共享程度也可以通过考虑生成过程中已知的定量统计偏差的模型以及胸腺选择的简单模型来很好地预测。一个序列是否被许多个体共享,取决于所查询的个体数量和采样深度,以及序列本身,这与数据一致。我们引入了根据查询队列大小和采样库大小条件下的公共度。基于这些观察结果,我们提出了一个基于生成概率的公共/私有序列分类器“PUBLIC”(公共通用二进制似然推理分类器),即使对于较小的队列大小,它的性能也非常好。