Princess Margaret Cancer Centre, University Health Network, Toronto, Ontario, Canada.
Department of Medical Biophysics, University of Toronto, Toronto, Ontario, Canada.
Nucleic Acids Res. 2018 Jan 4;46(D1):D994-D1002. doi: 10.1093/nar/gkx911.
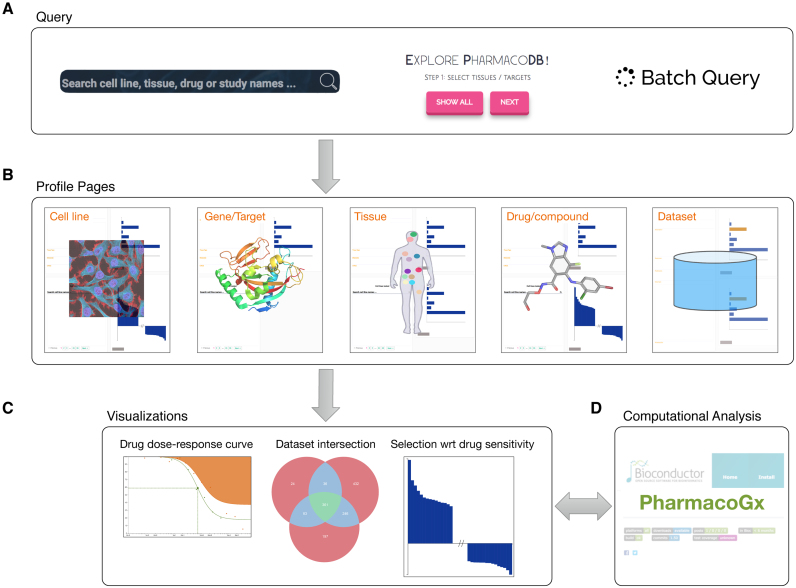
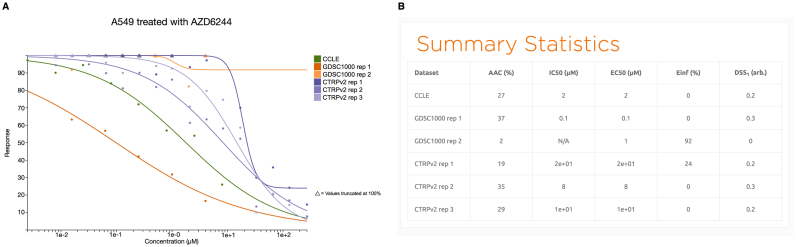
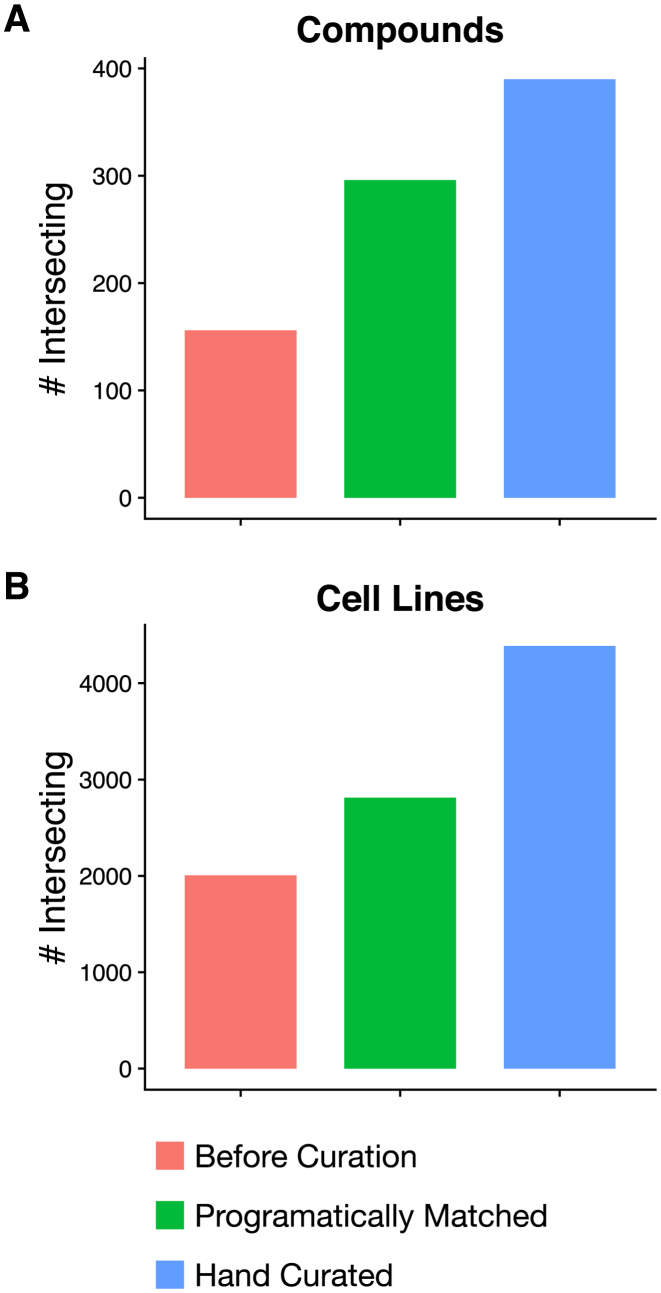
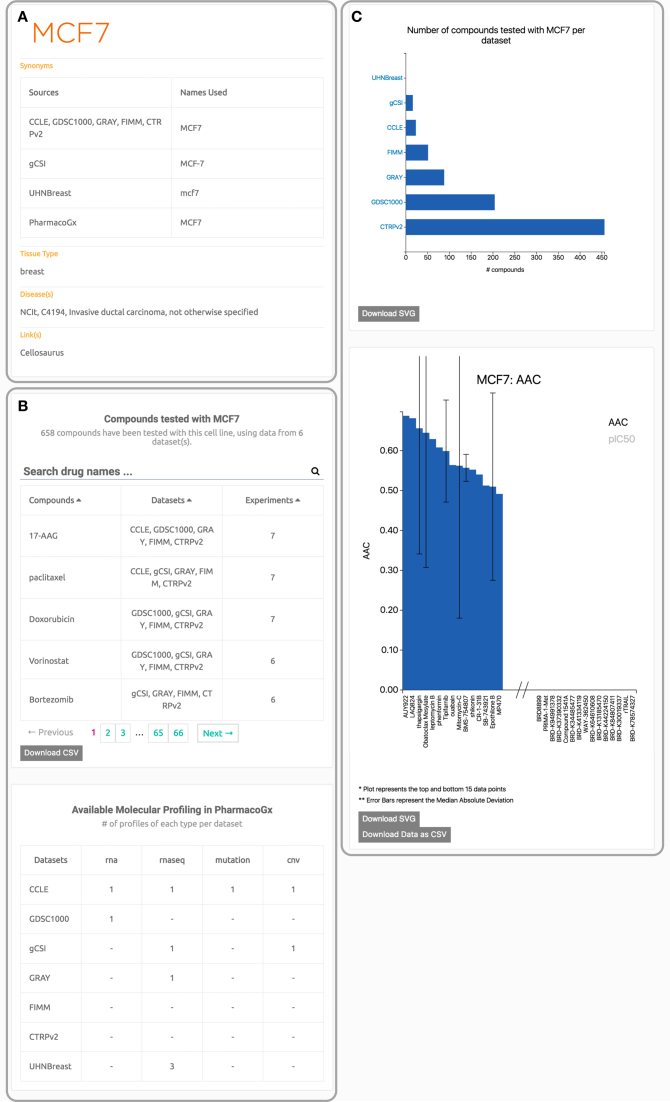
Recent cancer pharmacogenomic studies profiled large panels of cell lines against hundreds of approved drugs and experimental chemical compounds. The overarching goal of these screens is to measure sensitivity of cell lines to chemical perturbations, correlate these measures to genomic features, and thereby develop novel predictors of drug response. However, leveraging these valuable data is challenging due to the lack of standards for annotating cell lines and chemical compounds, and quantifying drug response. Moreover, it has been recently shown that the complexity and complementarity of the experimental protocols used in the field result in high levels of technical and biological variation in the in vitro pharmacological profiles. There is therefore a need for new tools to facilitate rigorous comparison and integrative analysis of large-scale drug screening datasets. To address this issue, we have developed PharmacoDB (pharmacodb.pmgenomics.ca), a database integrating the largest cancer pharmacogenomic studies published to date. Here, we describe how the curation of cell line and chemical compound identifiers maximizes the overlap between datasets and how users can leverage such data to compare and extract robust drug phenotypes. PharmacoDB provides a unique resource to mine a compendium of curated cancer pharmacogenomic datasets that are otherwise disparate and difficult to integrate.
最近的癌症药物基因组学研究对数百种已批准的药物和实验性化学化合物进行了大型细胞系分析。这些筛选的总体目标是测量细胞系对化学干扰的敏感性,将这些测量结果与基因组特征相关联,从而开发新的药物反应预测因子。然而,由于缺乏注释细胞系和化学化合物以及量化药物反应的标准,因此利用这些有价值的数据具有挑战性。此外,最近已经表明,该领域中使用的实验方案的复杂性和互补性导致体外药理学特征中存在高水平的技术和生物学变异。因此,需要新的工具来促进大规模药物筛选数据集的严格比较和综合分析。为了解决这个问题,我们开发了 PharmacoDB(pharmacodb.pmgenomics.ca),这是一个数据库,整合了迄今为止发表的最大的癌症药物基因组学研究。在这里,我们描述了如何通过细胞系和化学化合物标识符的编目来最大化数据集之间的重叠,以及用户如何利用这些数据来比较和提取稳健的药物表型。PharmacoDB 提供了一个独特的资源,用于挖掘编目癌症药物基因组学数据集的摘要,这些数据集否则是不同的,难以整合。