Big Data Institute, University of Oxford, Oxford, United Kingdom.
Ecology and Evolutionary Biology, University of California, Irvine, Irvine, California, United States of America.
PLoS Comput Biol. 2018 Nov 1;14(11):e1006581. doi: 10.1371/journal.pcbi.1006581. eCollection 2018 Nov.
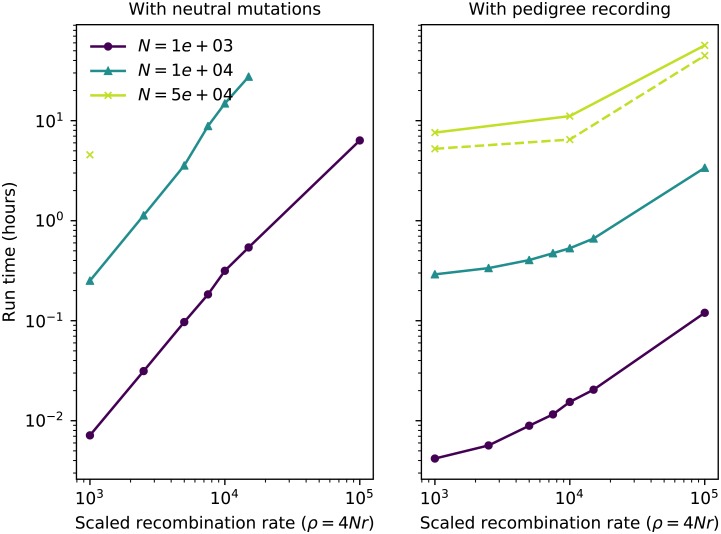
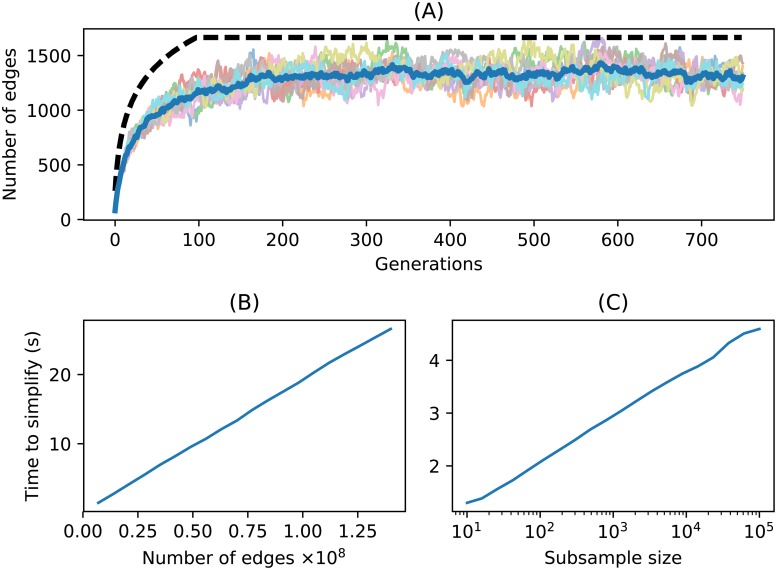
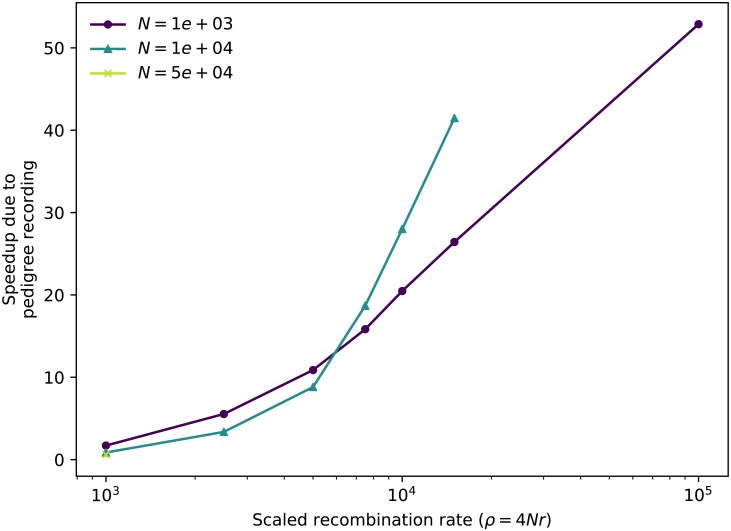
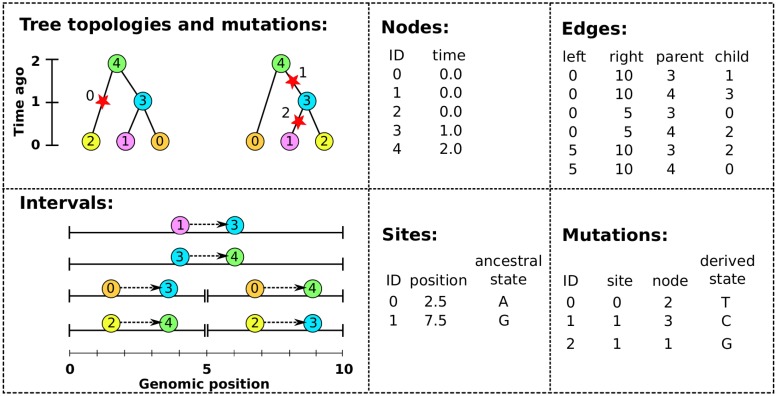
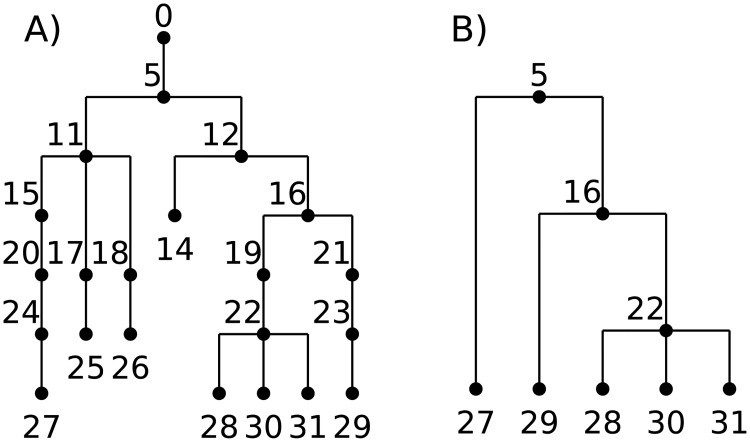
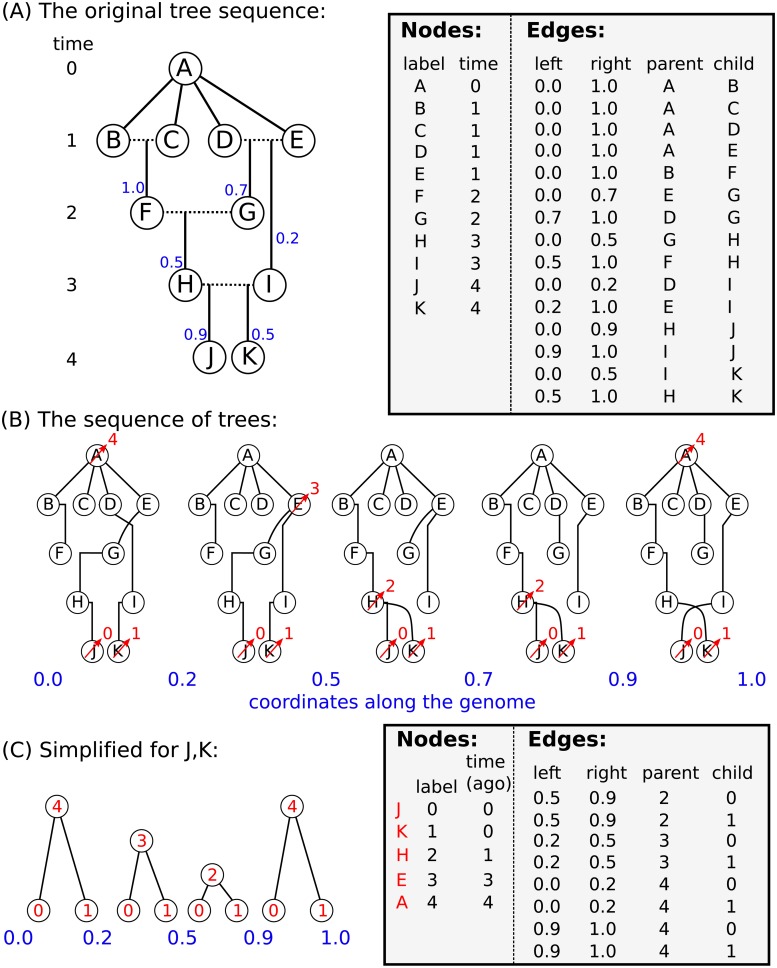
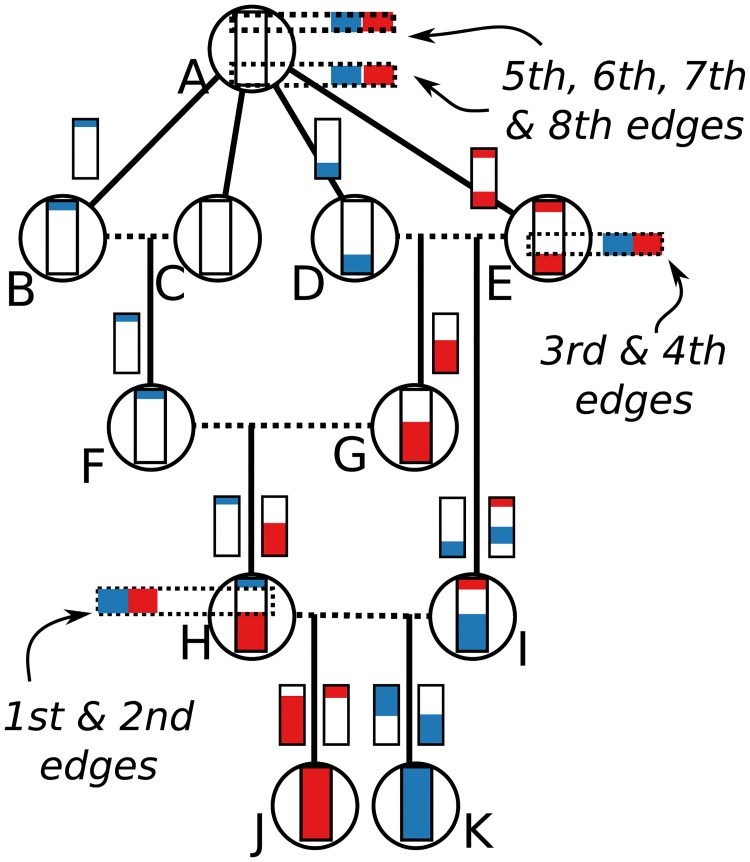
In this paper we describe how to efficiently record the entire genetic history of a population in forwards-time, individual-based population genetics simulations with arbitrary breeding models, population structure and demography. This approach dramatically reduces the computational burden of tracking individual genomes by allowing us to simulate only those loci that may affect reproduction (those having non-neutral variants). The genetic history of the population is recorded as a succinct tree sequence as introduced in the software package msprime, on which neutral mutations can be quickly placed afterwards. Recording the results of each breeding event requires storage that grows linearly with time, but there is a great deal of redundancy in this information. We solve this storage problem by providing an algorithm to quickly 'simplify' a tree sequence by removing this irrelevant history for a given set of genomes. By periodically simplifying the history with respect to the extant population, we show that the total storage space required is modest and overall large efficiency gains can be made over classical forward-time simulations. We implement a general-purpose framework for recording and simplifying genealogical data, which can be used to make simulations of any population model more efficient. We modify two popular forwards-time simulation frameworks to use this new approach and observe efficiency gains in large, whole-genome simulations of one to two orders of magnitude. In addition to speed, our method for recording pedigrees has several advantages: (1) All marginal genealogies of the simulated individuals are recorded, rather than just genotypes. (2) A population of N individuals with M polymorphic sites can be stored in O(N log N + M) space, making it feasible to store a simulation's entire final generation as well as its history. (3) A simulation can easily be initialized with a more efficient coalescent simulation of deep history. The software for recording and processing tree sequences is named tskit.
在本文中,我们描述了如何在具有任意繁殖模型、群体结构和人口统计学的正向个体基础群体遗传学模拟中,高效地记录群体的整个遗传历史。这种方法通过允许我们仅模拟那些可能影响繁殖的基因座(即具有非中性变体的基因座),极大地减少了跟踪个体基因组的计算负担。群体的遗传历史被记录为一个简洁的树序列,如软件包 msprime 中引入的那样,随后可以快速在其上放置中性突变。记录每个繁殖事件的结果需要线性增长的存储空间,但这些信息中有很大的冗余。我们通过提供一种算法来解决这个存储问题,该算法可以通过删除给定基因组集合的无关历史来快速“简化”树序列。通过定期根据现存群体简化历史,我们表明所需的总存储空间适中,并且相对于经典的正向时间模拟可以实现整体的高效率提升。我们实现了一个用于记录和简化系统发育数据的通用框架,可以用于使任何种群模型的模拟更有效率。我们修改了两个流行的正向时间模拟框架,以使用这种新方法,并观察到在一个到两个数量级的大型全基因组模拟中效率的提高。除了速度之外,我们记录系谱的方法还有几个优点:(1)记录了模拟个体的所有边缘系统发育,而不仅仅是基因型。(2)可以在 O(NlogN+M) 的空间中存储具有 N 个个体和 M 个多态性位点的群体,使得存储模拟的整个最终世代及其历史成为可能。(3)可以轻松地用更有效的深历史的合并模拟来初始化模拟。用于记录和处理树序列的软件名为 tskit。