Department of Psychology, University of Pennsylvania, Philadelphia, Pennsylvania, United States of America.
PLoS One. 2018 Nov 7;13(11):e0207083. doi: 10.1371/journal.pone.0207083. eCollection 2018.
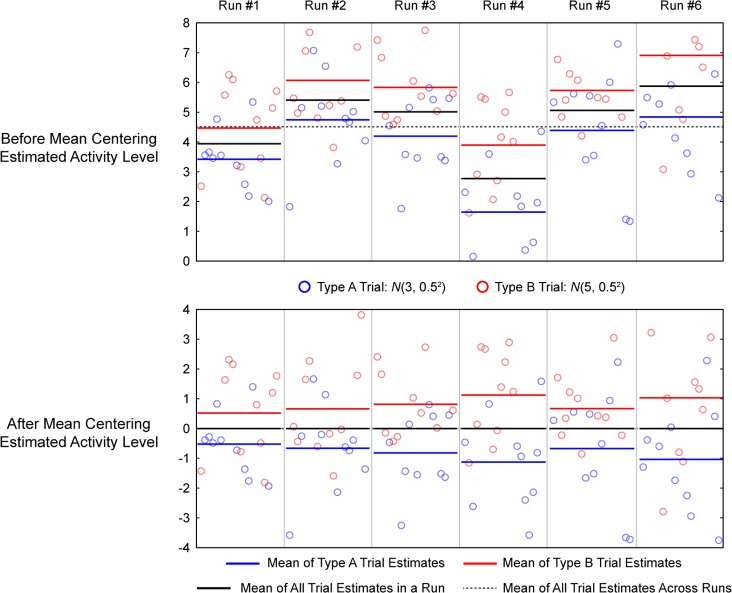
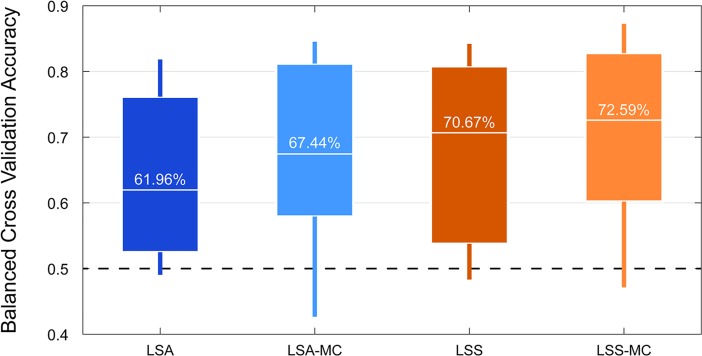
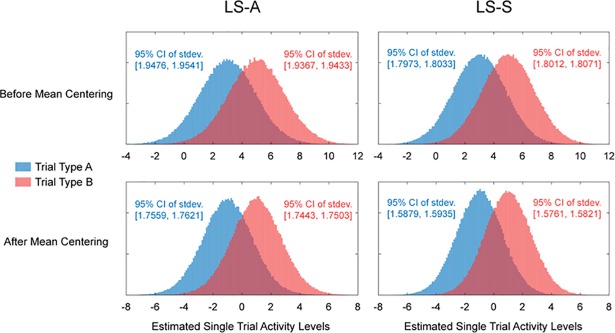
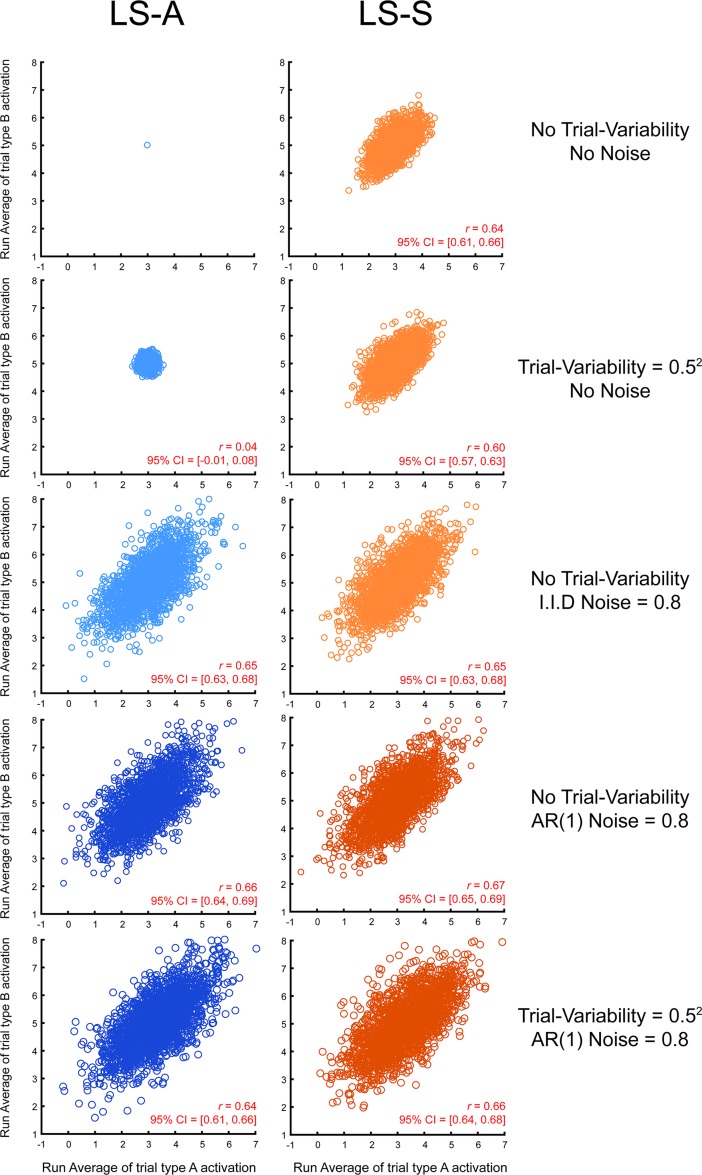
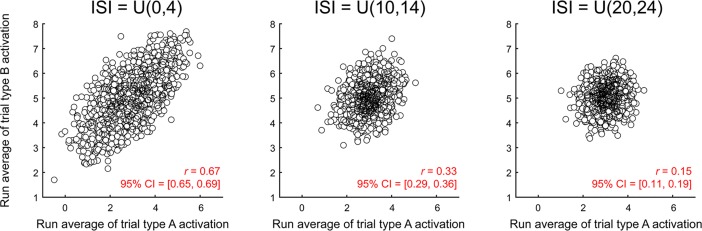
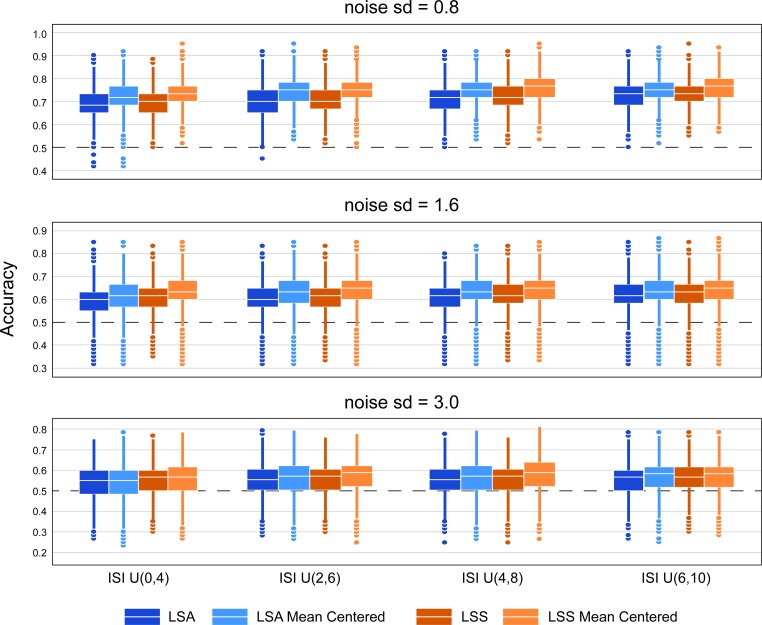
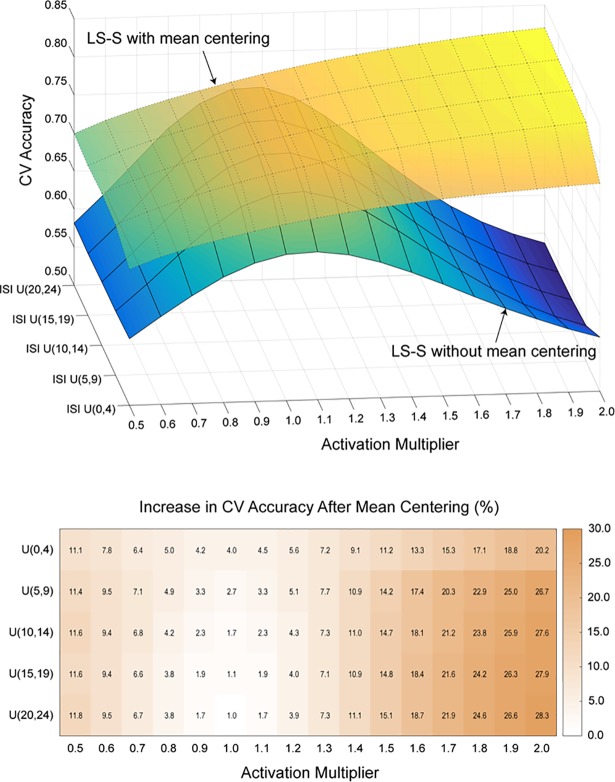
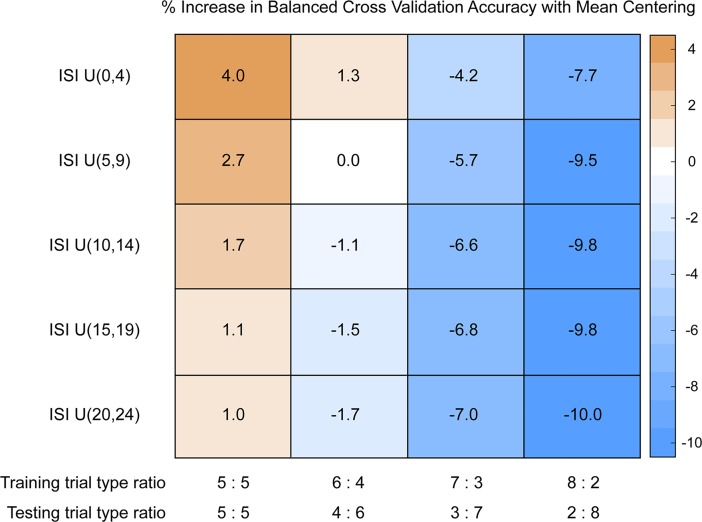
Multivoxel pattern analysis (MVPA) typically begins with the estimation of single trial activation levels, and several studies have examined how different procedures for estimating single trial activity affect the ultimate classification accuracy of MVPA. Here we show that the currently preferred estimation procedures impart spurious positive correlations between the means of different category activity estimates within the same scanner run. In other words, if the mean of the estimates for one type of trials is high (low) in a given scanner run, then the mean of the other type of trials is also high (low) for that same scanner run, and the run-level mean across all trials therefore shifts from run to run. Simulations show that these correlations occur whenever there is a need to deconvolve overlapping trial activities in the presence of noise. We show that subtracting each voxel's run-level mean across all trials from all the estimates within that run (i.e., run-level mean centering of estimates), by cancelling out these mean shifts, leads to robust and significant improvements in MVPA classification accuracy. These improvements are seen in both simulated and real data across a wide variety of situations. However, we also point out that there could be cases when mean activations are expected to shift across runs and that run-level mean centering could be detrimental in some of these cases (e.g., different proportion of trial types between different runs).
多体素模式分析 (MVPA) 通常从单个试验激活水平的估计开始,已有多项研究探讨了不同的估计单试活动的程序如何影响 MVPA 的最终分类准确性。在这里,我们表明目前首选的估计程序在同一扫描仪运行中不同类别活动估计的平均值之间产生了虚假的正相关。换句话说,如果给定扫描仪运行中某一类型试验的估计平均值较高(较低),则同一扫描仪运行中另一类型试验的平均值也较高(较低),并且所有试验的运行级平均值因此从一次运行到另一次运行发生变化。模拟表明,只要存在需要在存在噪声的情况下解卷积重叠试验活动的情况,就会出现这些相关性。我们表明,通过从该运行中的所有估计中减去所有试验的每个体素的运行级平均值(即,对估计进行运行级均值中心化),可以消除这些平均值的变化,从而导致 MVPA 分类准确性的稳健和显著提高。这些改进在各种情况下的模拟和真实数据中都可见到。然而,我们还指出,在某些情况下,可能期望平均激活跨运行发生变化,并且在某些情况下,运行级均值中心化可能会产生不利影响(例如,不同运行之间的试验类型比例不同)。