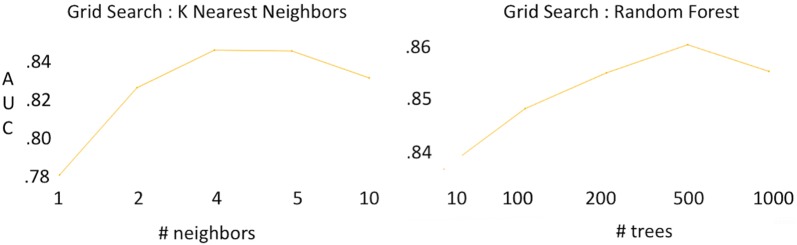Srinivas Raghuram, Klimovich Pavel V, Larson Eric C
Department of Computer Science and Engineering, Bobby B. Lyle School of Engineering, Southern Methodist University, 3145 Dyer Street, Dallas, TX, 75205, USA.
DataScience@SMU, Dallas, 75205, TX, USA.
J Cheminform. 2018 Nov 22;10(1):56. doi: 10.1186/s13321-018-0310-y.
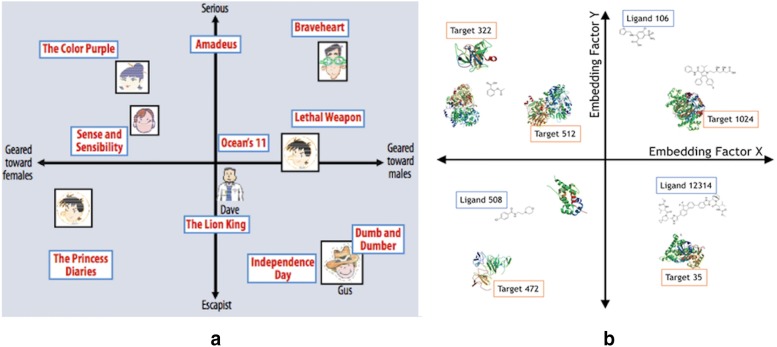
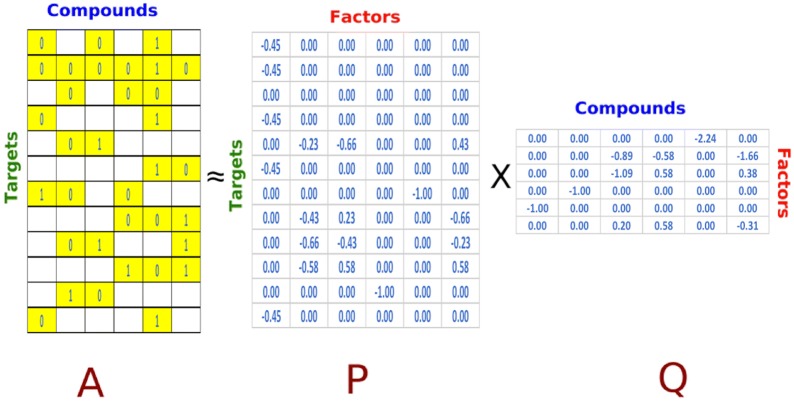
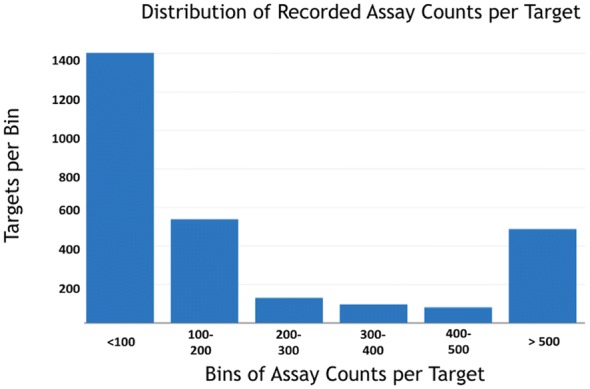
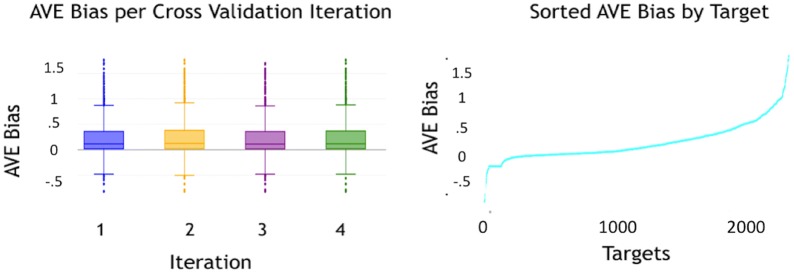
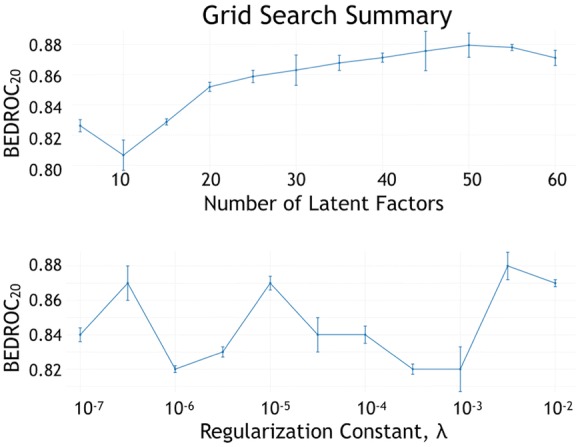
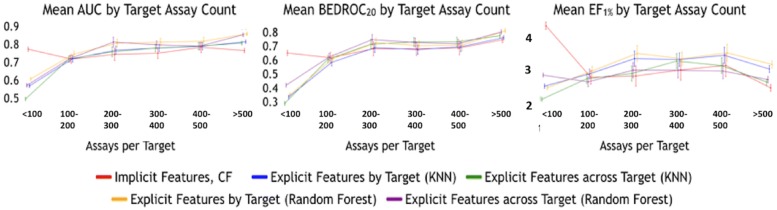
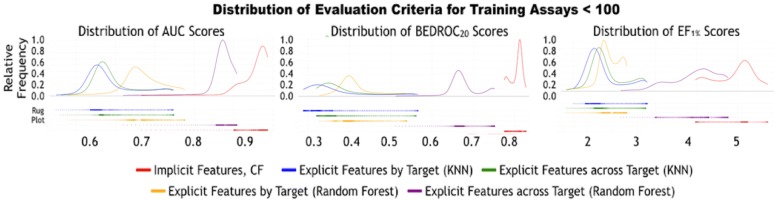
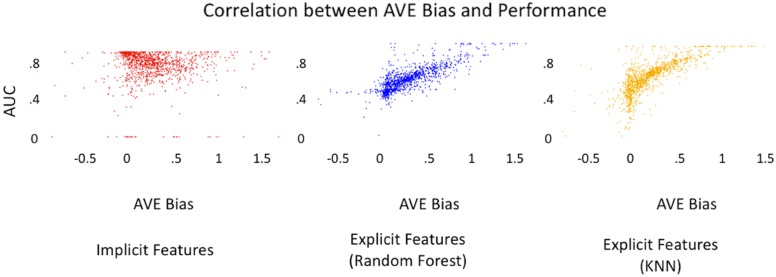
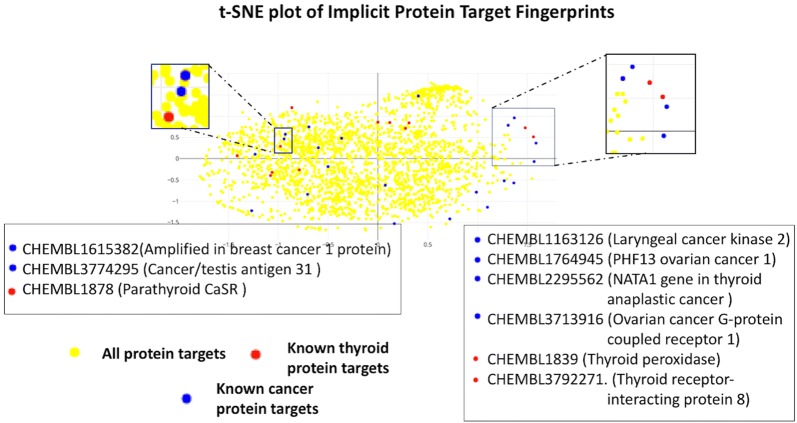
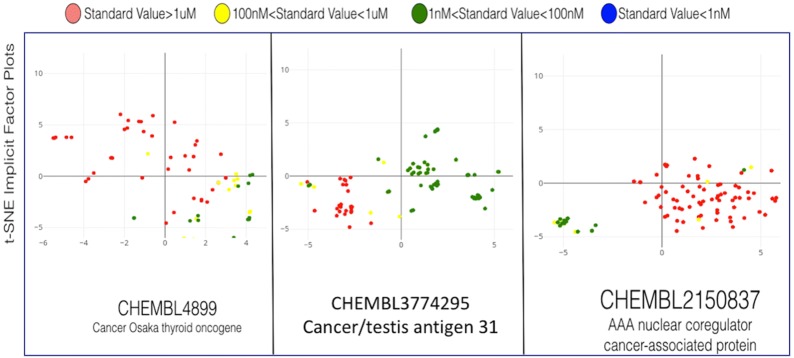
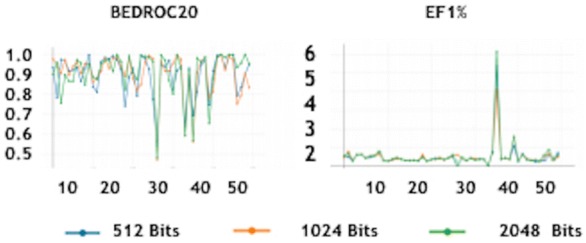
Current ligand-based machine learning methods in virtual screening rely heavily on molecular fingerprinting for preprocessing, i.e., explicit description of ligands' structural and physicochemical properties in a vectorized form. Of particular importance to current methods are the extent to which molecular fingerprints describe a particular ligand and what metric sufficiently captures similarity among ligands. In this work, we propose and evaluate methods that do not require explicit feature vectorization through fingerprinting, but, instead, provide implicit descriptors based only on other known assays. Our methods are based upon well known collaborative filtering algorithms used in recommendation systems. Our implicit descriptor method does not require any fingerprint similarity search, which makes the method free of the bias arising from the empirical nature of the fingerprint models. We show that implicit methods significantly outperform traditional machine learning methods, and the main strengths of implicit methods are their resilience to target-ligand sparsity and high potential for spotting promiscuous ligands.
当前虚拟筛选中基于配体的机器学习方法在很大程度上依赖于分子指纹进行预处理,即以矢量化形式明确描述配体的结构和物理化学性质。对于当前方法而言,特别重要的是分子指纹描述特定配体的程度以及何种度量能够充分捕捉配体之间的相似性。在这项工作中,我们提出并评估了一些方法,这些方法不需要通过指纹进行明确的特征矢量化,而是仅基于其他已知测定提供隐式描述符。我们的方法基于推荐系统中使用的著名协同过滤算法。我们的隐式描述符方法不需要任何指纹相似性搜索,这使得该方法不受指纹模型经验性质所产生的偏差影响。我们表明,隐式方法显著优于传统机器学习方法,并且隐式方法的主要优势在于它们对靶标 - 配体稀疏性的耐受性以及发现混杂配体的高潜力。