Instituto Nacional de Saúde Doutor Ricardo Jorge, Avenida Padre Cruz, Lisboa, Portugal.
BioISI: Biosystems & Integrative Sciences Institute, Faculdade de Ciências, Universidade de Lisboa, Lisboa, Portugal.
PLoS One. 2018 Dec 10;13(12):e0208626. doi: 10.1371/journal.pone.0208626. eCollection 2018.
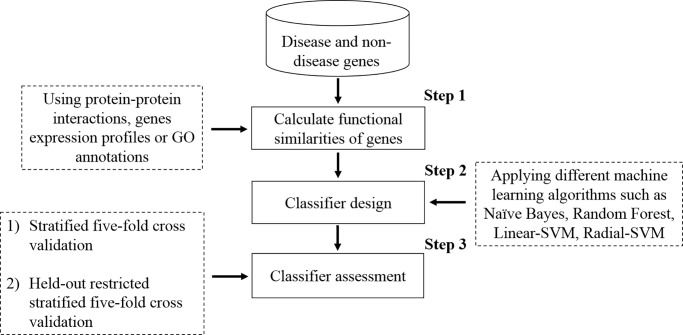
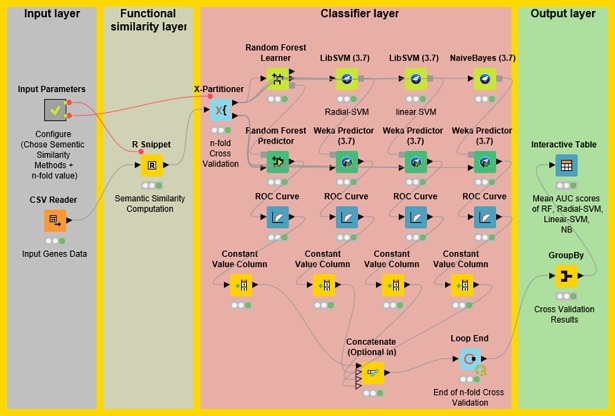
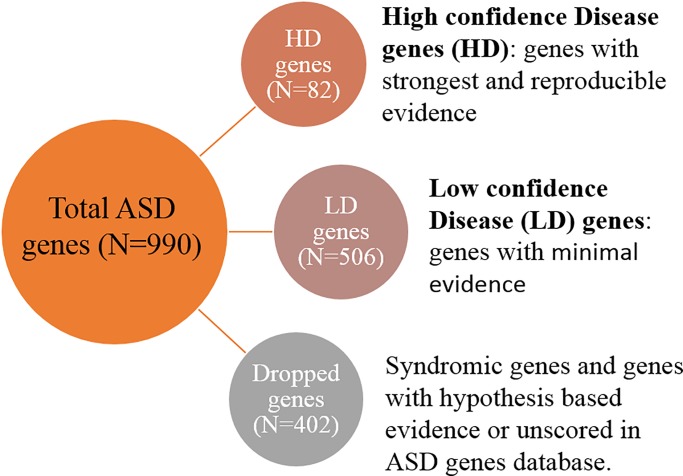
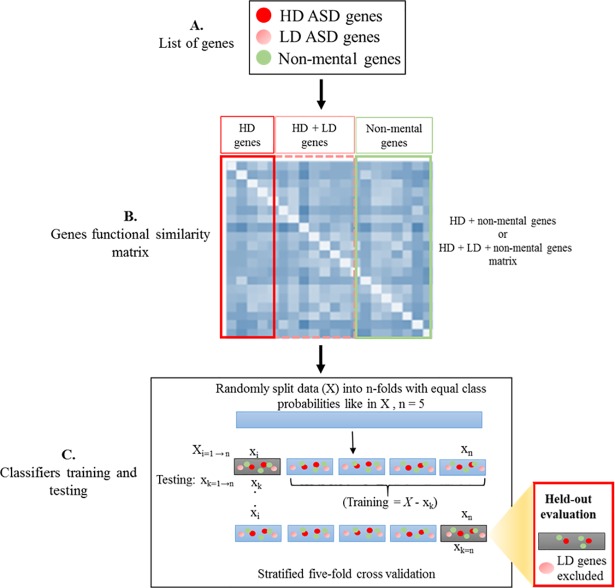
Identifying disease genes from a vast amount of genetic data is one of the most challenging tasks in the post-genomic era. Also, complex diseases present highly heterogeneous genotype, which difficult biological marker identification. Machine learning methods are widely used to identify these markers, but their performance is highly dependent upon the size and quality of available data. In this study, we demonstrated that machine learning classifiers trained on gene functional similarities, using Gene Ontology (GO), can improve the identification of genes involved in complex diseases. For this purpose, we developed a supervised machine learning methodology to predict complex disease genes. The proposed pipeline was assessed using Autism Spectrum Disorder (ASD) candidate genes. A quantitative measure of gene functional similarities was obtained by employing different semantic similarity measures. To infer the hidden functional similarities between ASD genes, various types of machine learning classifiers were built on quantitative semantic similarity matrices of ASD and non-ASD genes. The classifiers trained and tested on ASD and non-ASD gene functional similarities outperformed previously reported ASD classifiers. For example, a Random Forest (RF) classifier achieved an AUC of 0. 80 for predicting new ASD genes, which was higher than the reported classifier (0.73). Additionally, this classifier was able to predict 73 novel ASD candidate genes that were enriched for core ASD phenotypes, such as autism and obsessive-compulsive behavior. In addition, predicted genes were also enriched for ASD co-occurring conditions, including Attention Deficit Hyperactivity Disorder (ADHD). We also developed a KNIME workflow with the proposed methodology which allows users to configure and execute it without requiring machine learning and programming skills. Machine learning is an effective and reliable technique to decipher ASD mechanism by identifying novel disease genes, but this study further demonstrated that their performance can be improved by incorporating a quantitative measure of gene functional similarities. Source code and the workflow of the proposed methodology are available at https://github.com/Muh-Asif/ASD-genes-prediction.
从大量的遗传数据中识别疾病基因是后基因组时代最具挑战性的任务之一。此外,复杂疾病的基因型高度异质,这使得生物标志物的识别变得困难。机器学习方法被广泛用于识别这些标记物,但它们的性能高度依赖于可用数据的大小和质量。在这项研究中,我们证明了使用基因本体论(GO)基于基因功能相似性训练的机器学习分类器可以提高对涉及复杂疾病的基因的识别能力。为此,我们开发了一种监督机器学习方法来预测复杂疾病基因。使用自闭症谱系障碍(ASD)候选基因评估了所提出的方法。通过使用不同的语义相似性度量,获得了基因功能相似性的定量度量。为了推断 ASD 基因之间的隐藏功能相似性,我们在 ASD 和非 ASD 基因的定量语义相似性矩阵上构建了各种类型的机器学习分类器。在 ASD 和非 ASD 基因功能相似性上训练和测试的分类器优于以前报道的 ASD 分类器。例如,随机森林(RF)分类器在预测新的 ASD 基因方面的 AUC 为 0.80,高于报道的分类器(0.73)。此外,该分类器能够预测 73 个新的 ASD 候选基因,这些基因富集了核心 ASD 表型,如自闭症和强迫症行为。此外,预测的基因也富集了 ASD 共发疾病,包括注意力缺陷多动障碍(ADHD)。我们还使用所提出的方法开发了一个 KNIME 工作流程,允许用户无需机器学习和编程技能即可配置和执行它。机器学习是通过识别新的疾病基因来破译 ASD 机制的有效可靠技术,但这项研究进一步表明,通过纳入基因功能相似性的定量度量可以提高它们的性能。所提出的方法的源代码和工作流程可在 https://github.com/Muh-Asif/ASD-genes-prediction 上获得。