Harms Robbert L, Roebroeck Alard
Department of Cognitive Neuroscience, Faculty of Psychology & Neuroscience, Maastricht University, Maastricht, Netherlands.
Front Neuroinform. 2018 Dec 18;12:97. doi: 10.3389/fninf.2018.00097. eCollection 2018.
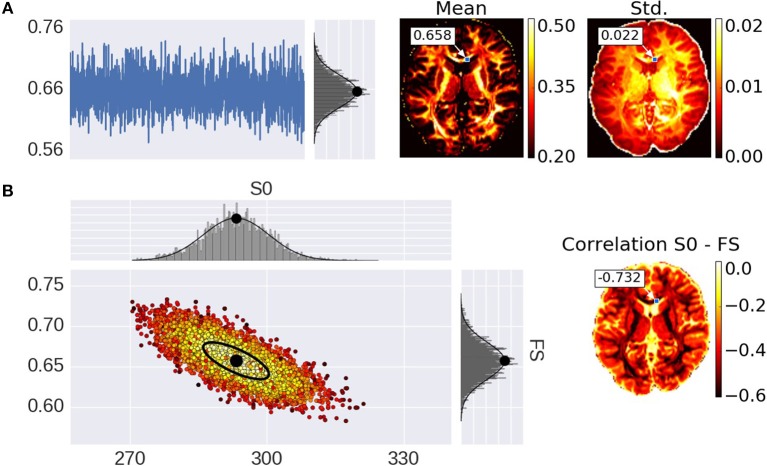
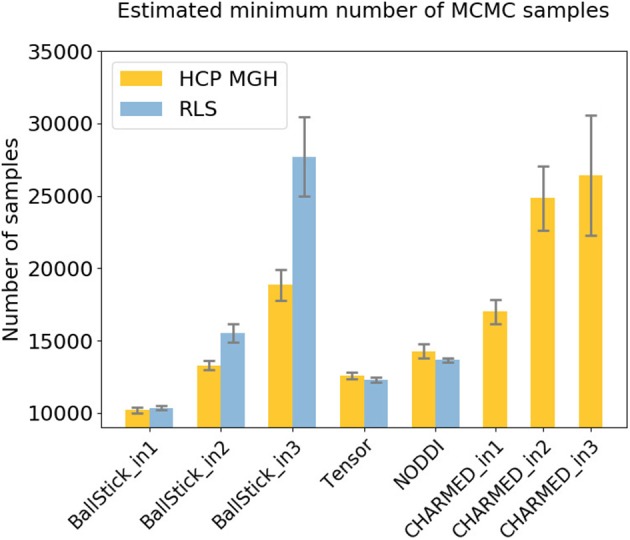
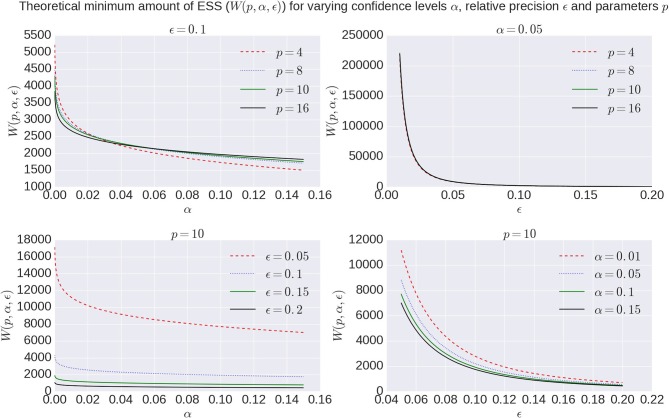
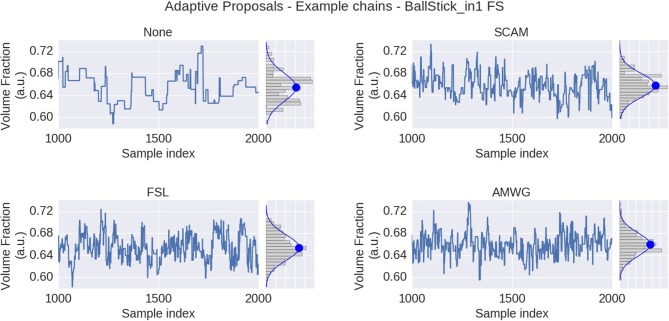
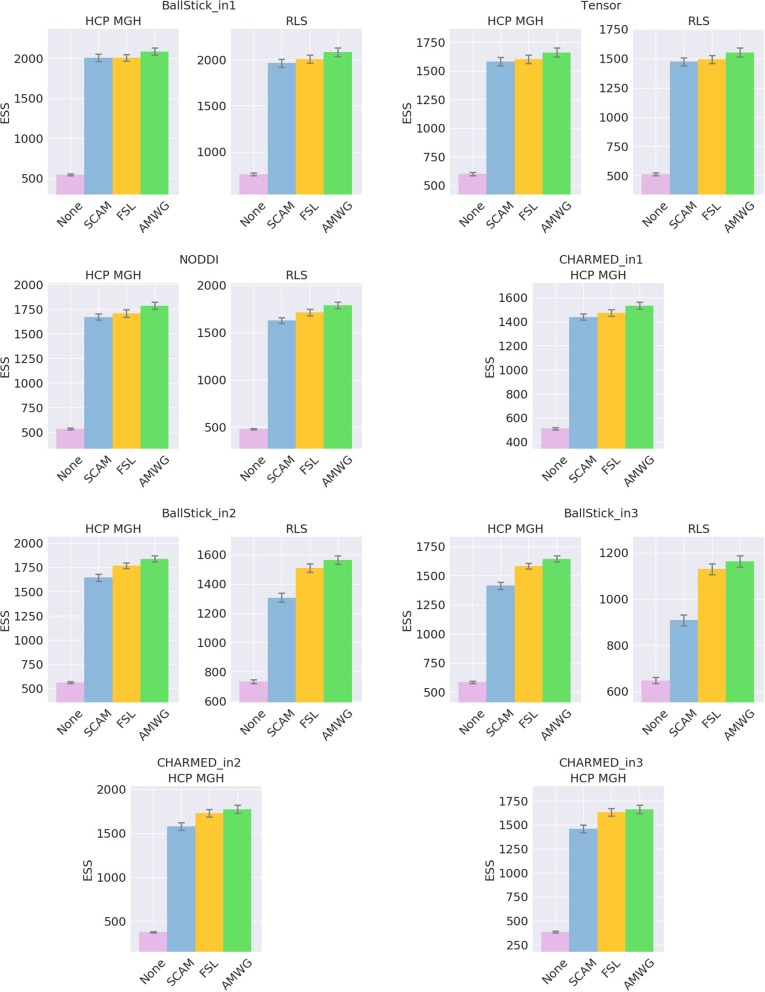
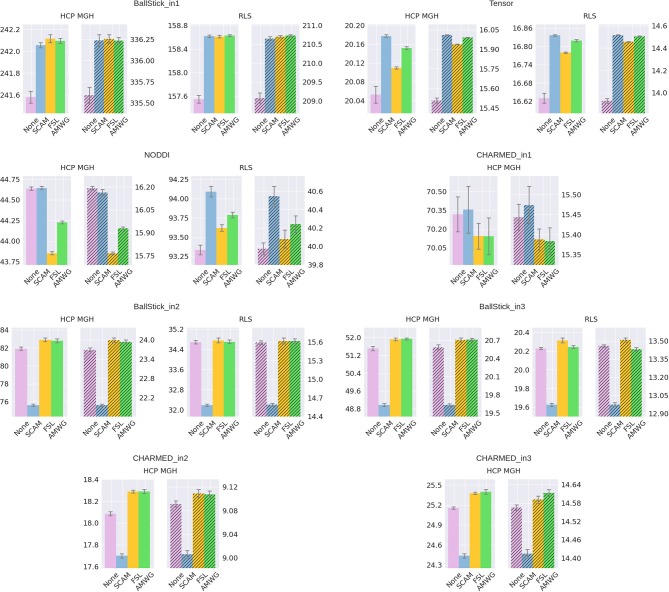
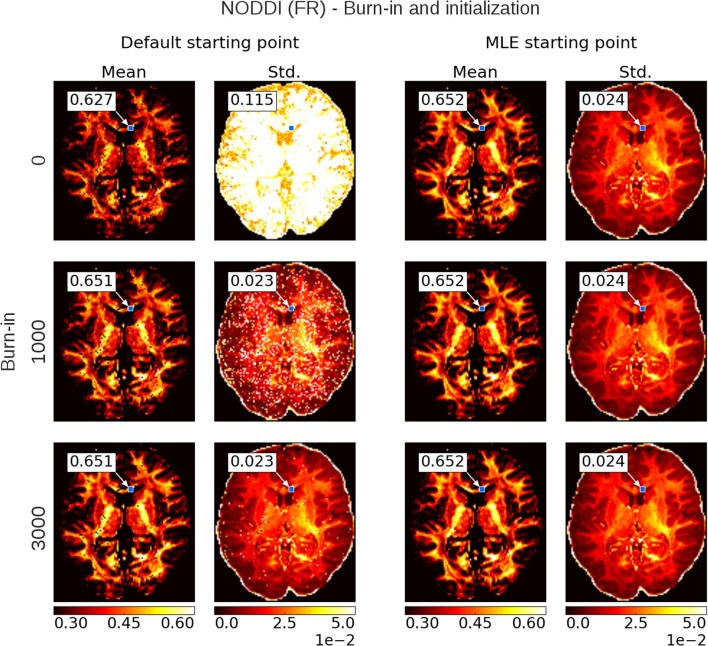
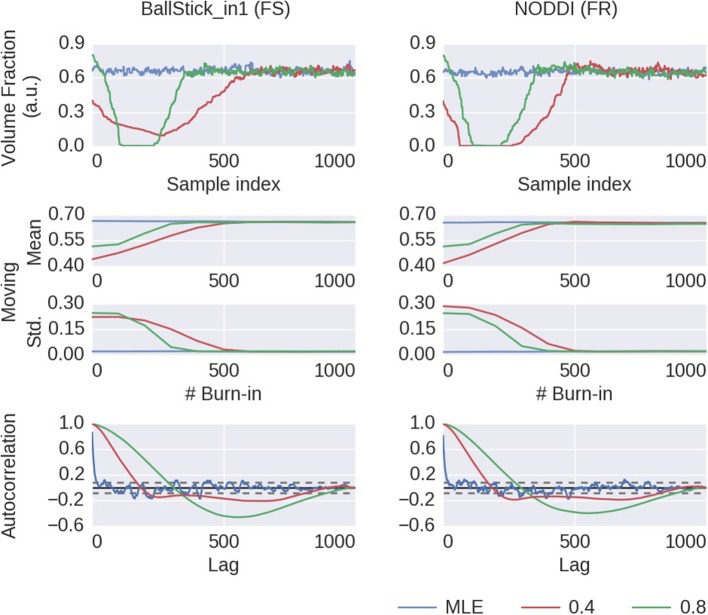
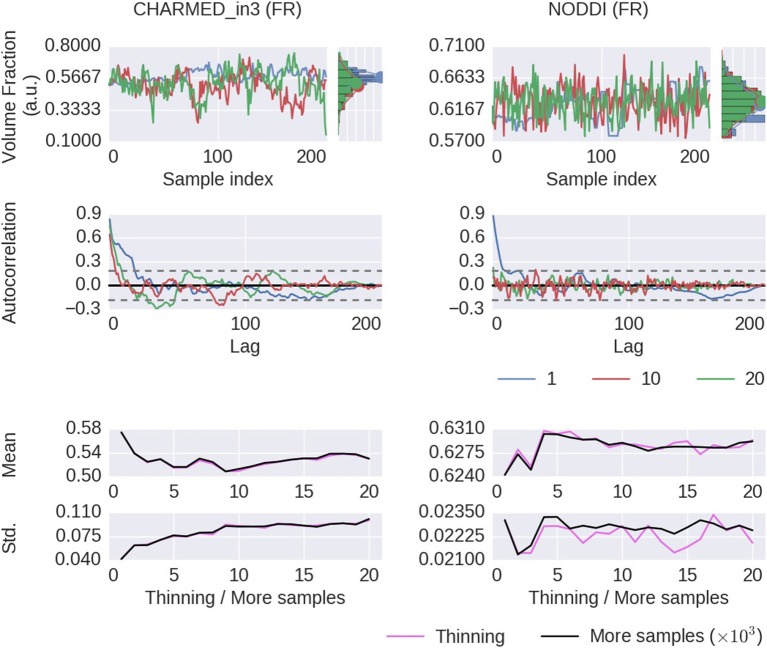
In diffusion MRI analysis, advances in biophysical multi-compartment modeling have gained popularity over the conventional Diffusion Tensor Imaging (DTI), because they can obtain a greater specificity in relating the dMRI signal to underlying cellular microstructure. Biophysical multi-compartment models require a parameter estimation, typically performed using either the Maximum Likelihood Estimation (MLE) or the Markov Chain Monte Carlo (MCMC) sampling. Whereas, the MLE provides only a point estimate of the fitted model parameters, the MCMC recovers the entire posterior distribution of the model parameters given in the data, providing additional information such as parameter uncertainty and correlations. MCMC sampling is currently not routinely applied in dMRI microstructure modeling, as it requires adjustment and tuning, specific to each model, particularly in the choice of proposal distributions, burn-in length, thinning, and the number of samples to store. In addition, sampling often takes at least an order of magnitude, more time than non-linear optimization. Here we investigate the performance of the MCMC algorithm variations over multiple popular diffusion microstructure models, to examine whether a single, well performing variation could be applied efficiently and robustly to many models. Using an efficient GPU-based implementation, we showed that run times can be removed as a prohibitive constraint for the sampling of diffusion multi-compartment models. Using this implementation, we investigated the effectiveness of different adaptive MCMC algorithms, burn-in, initialization, and thinning. Finally we applied the theory of the Effective Sample Size, to the diffusion multi-compartment models, as a way of determining a relatively general target for the number of samples needed to characterize parameter distributions for different models and data sets. We conclude that adaptive Metropolis methods increase MCMC performance and select the Adaptive Metropolis-Within-Gibbs (AMWG) algorithm as the primary method. We furthermore advise to initialize the sampling with an MLE point estimate, in which case 100 to 200 samples are sufficient as a burn-in. Finally, we advise against thinning in most use-cases and as a relatively general target for the number of samples, we recommend a multivariate Effective Sample Size of 2,200.
在扩散磁共振成像(dMRI)分析中,生物物理多室模型的进展相较于传统的扩散张量成像(DTI)更受欢迎,因为它们在将dMRI信号与潜在的细胞微观结构联系起来时能够获得更高的特异性。生物物理多室模型需要进行参数估计,通常使用最大似然估计(MLE)或马尔可夫链蒙特卡罗(MCMC)采样来执行。然而,MLE仅提供拟合模型参数的点估计,而MCMC则恢复数据中给出的模型参数的整个后验分布,提供诸如参数不确定性和相关性等额外信息。MCMC采样目前在dMRI微观结构建模中并非常规应用,因为它需要针对每个模型进行调整和调优,特别是在提议分布的选择、预烧长度、稀疏化以及要存储的样本数量方面。此外,采样通常比非线性优化至少多花费一个数量级的时间。在这里,我们研究了多种流行的扩散微观结构模型上MCMC算法变体的性能,以检验是否可以将一种表现良好的单一变体有效地且稳健地应用于许多模型。通过基于高效图形处理器(GPU)的实现,我们表明运行时间不再是扩散多室模型采样的阻碍性约束。使用这种实现方式,我们研究了不同的自适应MCMC算法、预烧、初始化和稀疏化的有效性。最后,我们将有效样本量理论应用于扩散多室模型,以此来确定表征不同模型和数据集的参数分布所需样本数量的相对通用目标。我们得出结论,自适应 metropolis 方法提高了MCMC性能,并选择自适应Gibbs内 metropolis(AMWG)算法作为主要方法。我们还建议用MLE点估计来初始化采样,在这种情况下,100到200个样本作为预烧就足够了。最后,我们建议在大多数使用案例中不要进行稀疏化,作为样本数量的相对通用目标,我们推荐多变量有效样本量为2200。