Operations Research Center, Massachusetts Institute of Technology, Cambridge.
Department of Industrial Engineering and Operations Research, University of California, Berkeley.
JAMA Netw Open. 2018 Dec 7;1(8):e186040. doi: 10.1001/jamanetworkopen.2018.6040.
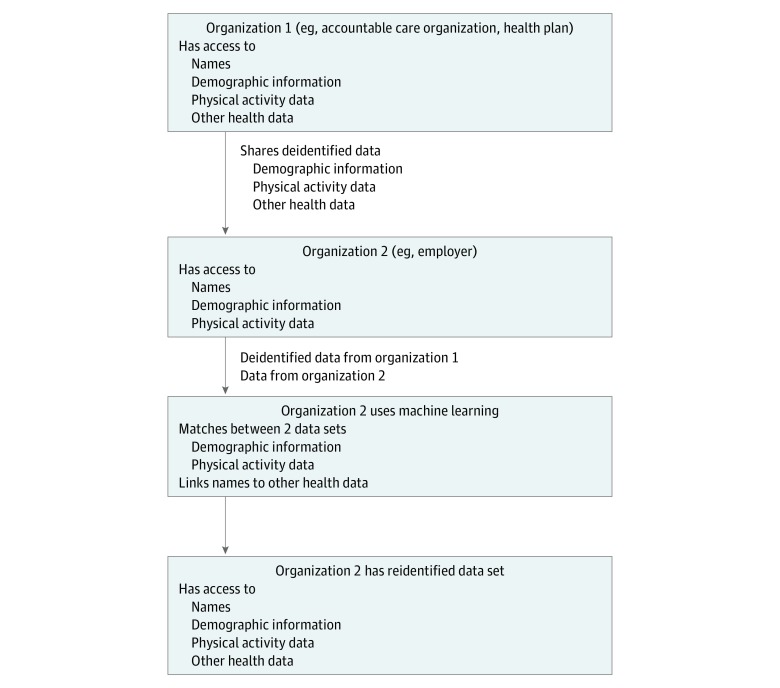
Despite data aggregation and removal of protected health information, there is concern that deidentified physical activity (PA) data collected from wearable devices can be reidentified. Organizations collecting or distributing such data suggest that the aforementioned measures are sufficient to ensure privacy. However, no studies, to our knowledge, have been published that demonstrate the possibility or impossibility of reidentifying such activity data.
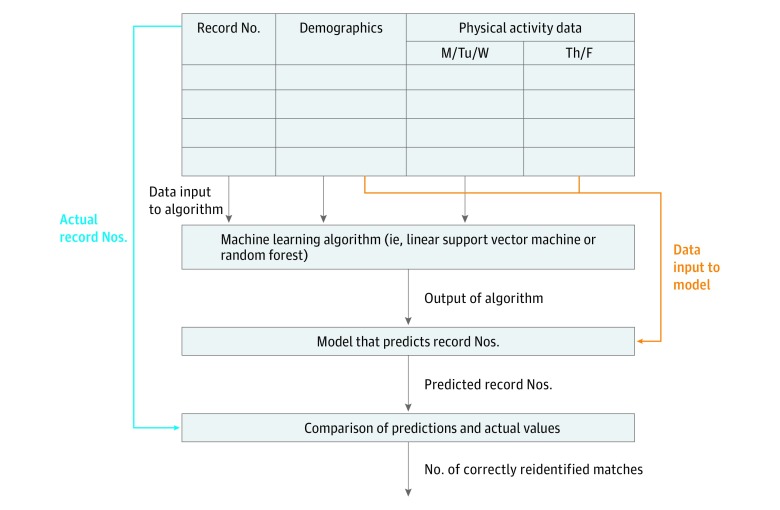
To evaluate the feasibility of reidentifying accelerometer-measured PA data, which have had geographic and protected health information removed, using support vector machines (SVMs) and random forest methods from machine learning.
DESIGN, SETTING, AND PARTICIPANTS: In this cross-sectional study, the National Health and Nutrition Examination Survey (NHANES) 2003-2004 and 2005-2006 data sets were analyzed in 2018. The accelerometer-measured PA data were collected in a free-living setting for 7 continuous days. NHANES uses a multistage probability sampling design to select a sample that is representative of the civilian noninstitutionalized household (both adult and children) population of the United States.
The NHANES data sets contain objectively measured movement intensity as recorded by accelerometers worn during all walking for 1 week.
The primary outcome was the ability of the random forest and linear SVM algorithms to match demographic and 20-minute aggregated PA data to individual-specific record numbers, and the percentage of correct matches by each machine learning algorithm was the measure.
A total of 4720 adults (mean [SD] age, 40.0 [20.6] years) and 2427 children (mean [SD] age, 12.3 [3.4] years) in NHANES 2003-2004 and 4765 adults (mean [SD] age, 45.2 [19.9] years) and 2539 children (mean [SD] age, 12.1 [3.4] years) in NHANES 2005-2006 were included in the study. The random forest algorithm successfully reidentified the demographic and 20-minute aggregated PA data of 4478 adults (94.9%) and 2120 children (87.4%) in NHANES 2003-2004 and 4470 adults (93.8%) and 2172 children (85.5%) in NHANES 2005-2006 (P < .001 for all). The linear SVM algorithm successfully reidentified the demographic and 20-minute aggregated PA data of 4043 adults (85.6%) and 1695 children (69.8%) in NHANES 2003-2004 and 4041 adults (84.8%) and 1705 children (67.2%) in NHANES 2005-2006 (P < .001 for all).
This study suggests that current practices for deidentification of accelerometer-measured PA data might be insufficient to ensure privacy. This finding has important policy implications because it appears to show the need for deidentification that aggregates the PA data of multiple individuals to ensure privacy for single individuals.
尽管数据聚合和保护健康信息的删除,仍有人担心从可穿戴设备收集的去识别的身体活动 (PA) 数据可能被重新识别。收集或分发此类数据的组织建议,上述措施足以确保隐私。然而,据我们所知,没有研究表明这种活动数据重新识别的可能性或不可能。
使用机器学习中的支持向量机 (SVM) 和随机森林方法,评估从地理和保护健康信息中删除的加速度计测量的 PA 数据重新识别的可行性。
设计、设置和参与者:在这项横断面研究中,分析了 2018 年的国家健康和营养检查调查 (NHANES) 2003-2004 年和 2005-2006 年数据集。加速度计测量的 PA 数据是在自由生活环境中连续 7 天收集的。NHANES 使用多阶段概率抽样设计来选择代表美国非机构化家庭(包括成人和儿童)人口的样本。
NHANES 数据集包含通过佩戴在所有行走期间记录的加速度计客观测量的运动强度。
主要结果是随机森林和线性 SVM 算法将人口统计学和 20 分钟聚合的 PA 数据与个体特定记录编号相匹配的能力,每个机器学习算法的正确匹配百分比是衡量标准。
在 NHANES 2003-2004 年中,共有 4720 名成年人(平均[SD]年龄,40.0[20.6]岁)和 2427 名儿童(平均[SD]年龄,12.3[3.4]岁),以及 NHANES 2005-2006 年中的 4765 名成年人(平均[SD]年龄,45.2[19.9]岁)和 2539 名儿童(平均[SD]年龄,12.1[3.4]岁)被纳入研究。随机森林算法成功地重新识别了 NHANES 2003-2004 年中 4478 名成年人(94.9%)和 2120 名儿童(87.4%)的人口统计学和 20 分钟聚合的 PA 数据,以及 NHANES 2005-2006 年中 4470 名成年人(93.8%)和 2172 名儿童(85.5%)(所有 P<.001)。线性 SVM 算法成功地重新识别了 NHANES 2003-2004 年中 4043 名成年人(85.6%)和 1695 名儿童(69.8%)的人口统计学和 20 分钟聚合的 PA 数据,以及 NHANES 2005-2006 年中 4041 名成年人(84.8%)和 1705 名儿童(67.2%)(所有 P<.001)。
本研究表明,当前用于去识别加速度计测量的 PA 数据的做法可能不足以确保隐私。这一发现具有重要的政策意义,因为它似乎表明需要去识别将多个个体的 PA 数据聚合在一起,以确保单个个体的隐私。