Department of Crop and Soil Sciences, North Carolina State University, Raleigh, NC, 27695, USA.
USDA-ARS Plant Science Research, North Carolina State University, Raleigh, NC, 27695, USA.
Theor Appl Genet. 2019 Apr;132(4):1247-1261. doi: 10.1007/s00122-019-03276-6. Epub 2019 Jan 24.
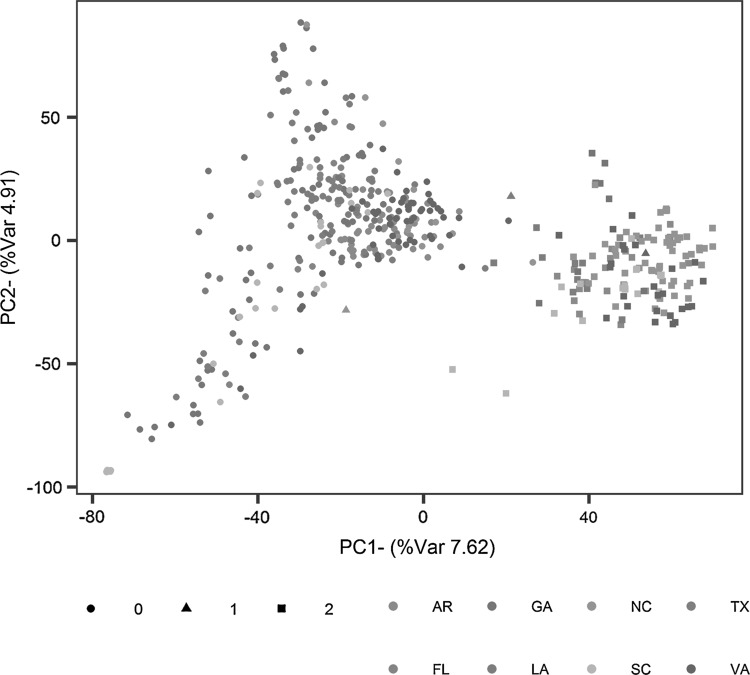
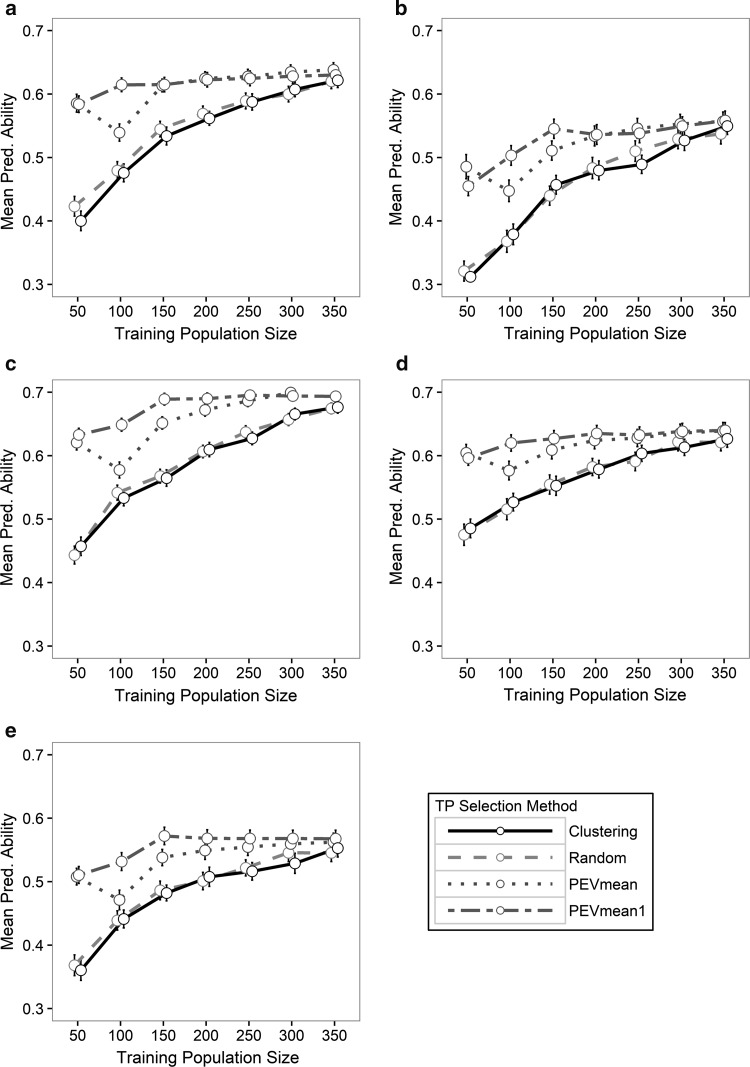
The optimization of training populations and the use of diagnostic markers as fixed effects increase the predictive ability of genomic prediction models in a cooperative wheat breeding panel. Plant breeding programs often have access to a large amount of historical data that is highly unbalanced, particularly across years. This study examined approaches to utilize these data sets as training populations to integrate genomic selection into existing pipelines. We used cross-validation to evaluate predictive ability in an unbalanced data set of 467 winter wheat (Triticum aestivum L.) genotypes evaluated in the Gulf Atlantic Wheat Nursery from 2008 to 2016. We evaluated the impact of different training population sizes and training population selection methods (Random, Clustering, PEVmean and PEVmean1) on predictive ability. We also evaluated inclusion of markers associated with major genes as fixed effects in prediction models for heading date, plant height, and resistance to powdery mildew (caused by Blumeria graminis f. sp. tritici). Increases in predictive ability as the size of the training population increased were more evident for Random and Clustering training population selection methods than for PEVmean and PEVmean1. The selection methods based on minimization of the prediction error variance (PEV) outperformed the Random and Clustering methods across all the population sizes. Major genes added as fixed effects always improved model predictive ability, with the greatest gains coming from combinations of multiple genes. Maximum predictabilities among all prediction methods were 0.64 for grain yield, 0.56 for test weight, 0.71 for heading date, 0.73 for plant height, and 0.60 for powdery mildew resistance. Our results demonstrate the utility of combining unbalanced phenotypic records with genome-wide SNP marker data for predicting the performance of untested genotypes.
优化训练群体并将诊断标记用作固定效应,可以提高合作小麦育种群体中基因组预测模型的预测能力。植物育种计划通常可以访问大量高度不平衡的历史数据,尤其是在不同年份之间。本研究探讨了利用这些数据集作为训练群体的方法,以将基因组选择纳入现有的流水线。我们使用交叉验证来评估在 2008 年至 2016 年在海湾大西洋小麦苗圃中评估的 467 个冬小麦(Triticum aestivum L.)基因型的不平衡数据集的预测能力。我们评估了不同训练群体大小和训练群体选择方法(随机、聚类、PEVmean 和 PEVmean1)对预测能力的影响。我们还评估了将与主要基因相关的标记作为固定效应纳入预测模型中,用于预测抽穗期、株高和对白粉病(由 Blumeria graminis f. sp. tritici 引起)的抗性。随着训练群体大小的增加,预测能力的提高在随机和聚类训练群体选择方法中比在 PEVmean 和 PEVmean1 中更为明显。基于预测误差方差(PEV)最小化的选择方法在所有群体大小下均优于随机和聚类方法。作为固定效应添加的主要基因总是可以提高模型的预测能力,最大的收益来自多个基因的组合。所有预测方法中的最大预测能力为:籽粒产量为 0.64,测试重量为 0.56,抽穗期为 0.71,株高为 0.73,白粉病抗性为 0.60。我们的结果表明,结合不平衡表型记录和全基因组 SNP 标记数据来预测未测试基因型的表现是有用的。