INRAE-UCA, UMR GDEC, Clermont-Ferrand, France.
Agri-Obtentions, Ferme de Gauvilliers, Orsonville, France.
PLoS One. 2020 Apr 2;15(4):e0222733. doi: 10.1371/journal.pone.0222733. eCollection 2020.
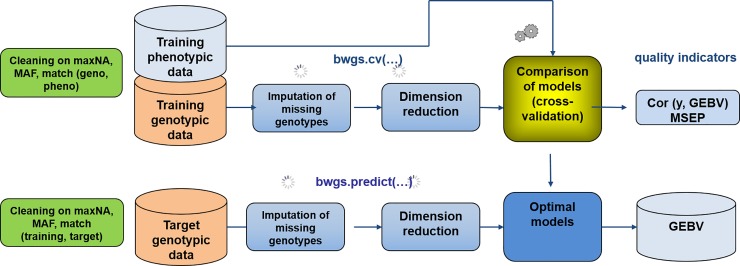
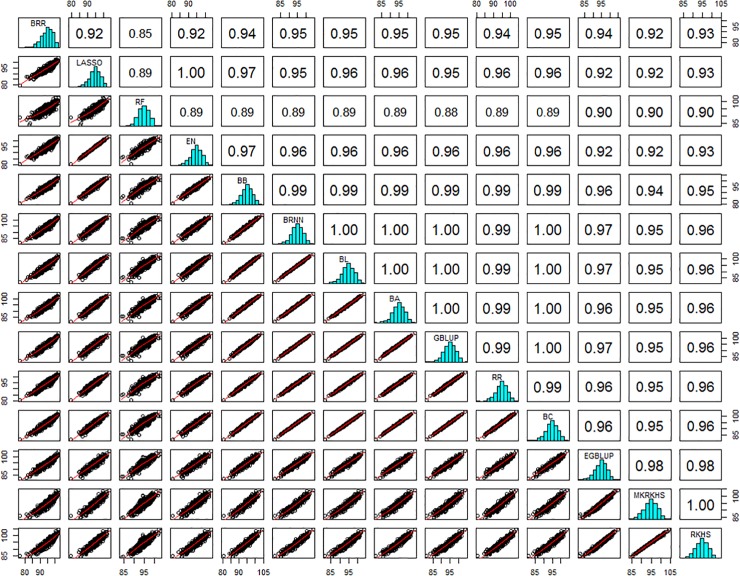
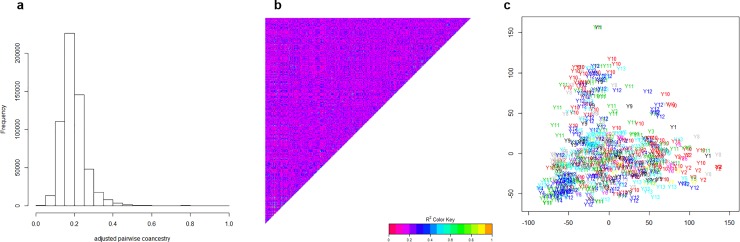
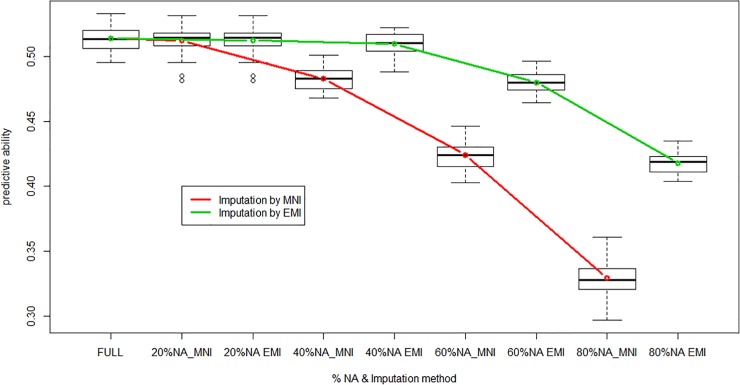
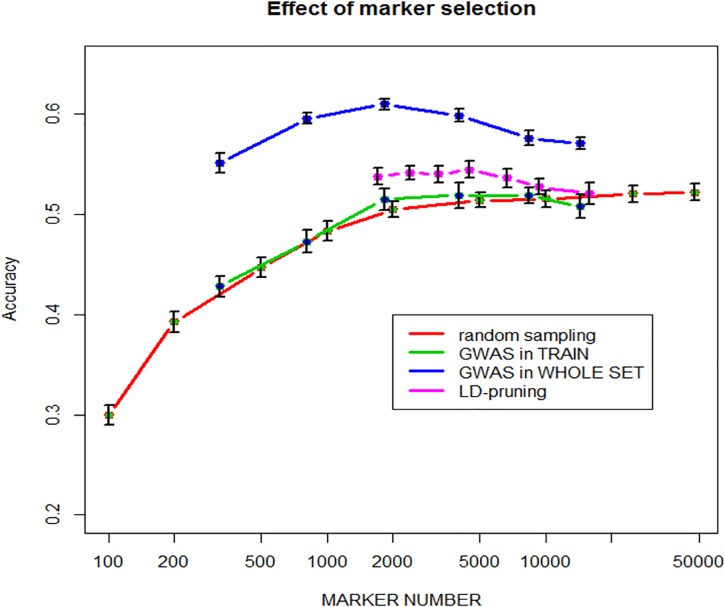
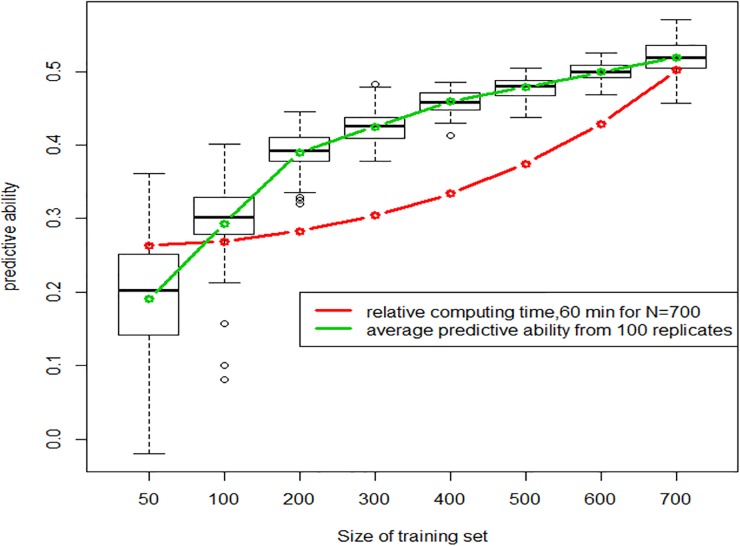
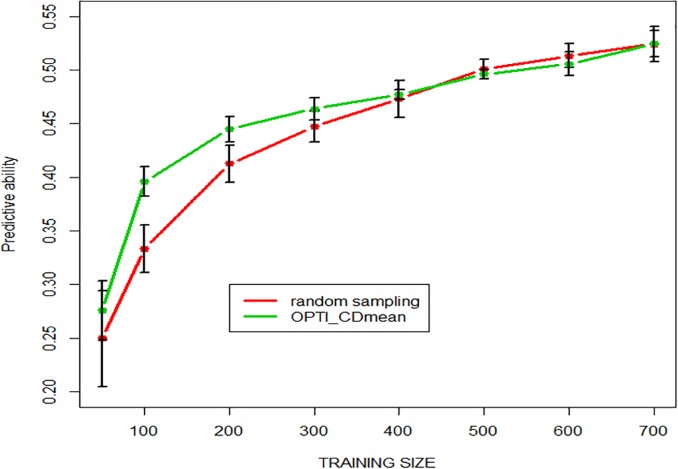
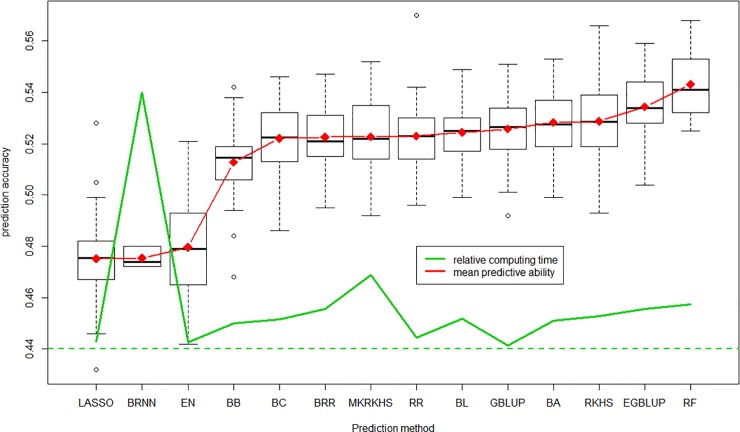
We developed an integrated R library called BWGS to enable easy computation of Genomic Estimates of Breeding values (GEBV) for genomic selection. BWGS, for BreedWheat Genomic selection, was developed in the framework of a cooperative private-public partnership project called Breedwheat (https://breedwheat.fr) and relies on existing R-libraries, all freely available from CRAN servers. The two main functions enable to run 1) replicated random cross validations within a training set of genotyped and phenotyped lines and 2) GEBV prediction, for a set of genotyped-only lines. Options are available for 1) missing data imputation, 2) markers and training set selection and 3) genomic prediction with 15 different methods, either parametric or semi-parametric. The usefulness and efficiency of BWGS are illustrated using a population of wheat lines from a real breeding programme. Adjusted yield data from historical trials (highly unbalanced design) were used for testing the options of BWGS. On the whole, 760 candidate lines with adjusted phenotypes and genotypes for 47 839 robust SNP were used. With a simple desktop computer, we obtained results which compared with previously published results on wheat genomic selection. As predicted by the theory, factors that are most influencing predictive ability, for a given trait of moderate heritability, are the size of the training population and a minimum number of markers for capturing every QTL information. Missing data up to 40%, if randomly distributed, do not degrade predictive ability once imputed, and up to 80% randomly distributed missing data are still acceptable once imputed with Expectation-Maximization method of package rrBLUP. It is worth noticing that selecting markers that are most associated to the trait do improve predictive ability, compared with the whole set of markers, but only when marker selection is made on the whole population. When marker selection is made only on the sampled training set, this advantage nearly disappeared, since it was clearly due to overfitting. Few differences are observed between the 15 prediction models with this dataset. Although non-parametric methods that are supposed to capture non-additive effects have slightly better predictive accuracy, differences remain small. Finally, the GEBV from the 15 prediction models are all highly correlated to each other. These results are encouraging for an efficient use of genomic selection in applied breeding programmes and BWGS is a simple and powerful toolbox to apply in breeding programmes or training activities.
我们开发了一个名为 BWGS 的集成 R 库,用于方便计算基因组选择的育种值(GEBV)的基因组估计。BWGS 是为 BreedWheat 基因组选择开发的,它是一个名为 Breedwheat(https://breedwheat.fr)的合作公私伙伴关系项目的框架内开发的,并且依赖于现有的 R 库,这些库都可以从 CRAN 服务器免费获得。两个主要功能允许 1)在一组已分型和表型的系内进行复制随机交叉验证,2)对一组仅分型的系进行 GEBV 预测。选项可用于 1)缺失数据插补,2)标记和训练集选择以及 3)使用 15 种不同的方法进行基因组预测,包括参数和半参数方法。使用来自实际育种计划的小麦系群体来说明 BWGS 的有用性和效率。使用历史试验的调整产量数据(高度不平衡设计)来测试 BWGS 的选项。总的来说,使用了 760 条具有调整后表型和基因型的候选系,用于 47839 个稳健 SNP。使用简单的台式计算机,我们获得了与以前发表的小麦基因组选择结果相比较的结果。根据理论预测,对于中等遗传力的给定性状,影响预测能力的最重要因素是训练群体的大小和捕获每个 QTL 信息的最小标记数量。如果缺失数据随机分布且不超过 40%,则在插补后不会降低预测能力,并且在使用 rrBLUP 包的期望最大化方法插补多达 80%的随机分布缺失数据后仍可接受。值得注意的是,与整个标记集相比,选择与性状最相关的标记确实可以提高预测能力,但仅当在整个群体上进行标记选择时。当仅在抽样训练集上进行标记选择时,这种优势几乎消失,因为这显然是由于过度拟合所致。使用此数据集,在 15 种预测模型之间观察到很少的差异。尽管假定捕获非加性效应的非参数方法具有稍高的预测准确性,但差异仍然很小。最后,15 种预测模型的 GEBV 彼此高度相关。这些结果对于在应用育种计划中有效使用基因组选择是令人鼓舞的,并且 BWGS 是在育种计划或培训活动中应用的简单而强大的工具包。