Department of Electrical Engineering and Computer Engineering, Northeastern University, Boston, MA, 02115, USA.
Division of Biostatistics, Medical College of Wisconsin, Milwaukee, WI, 53226, USA.
Sci Rep. 2019 Feb 6;9(1):1495. doi: 10.1038/s41598-018-37142-0.
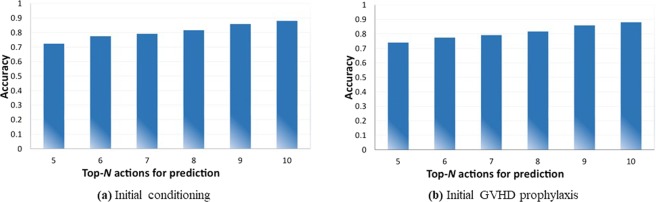
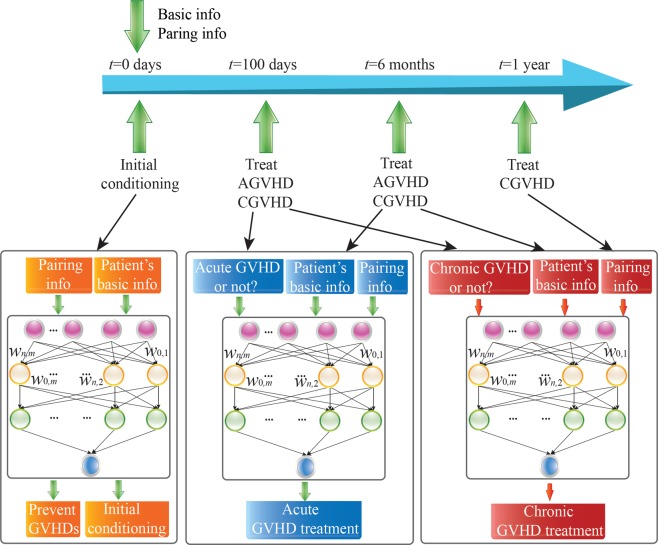
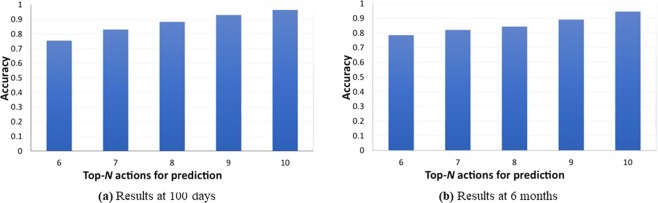
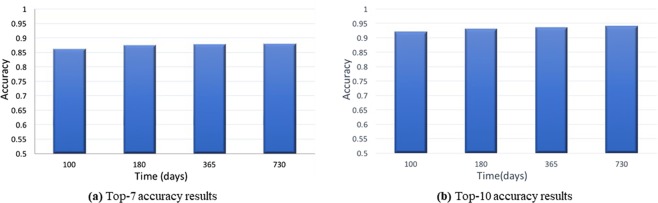
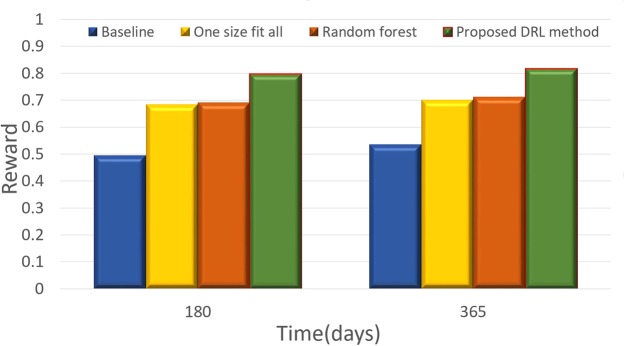
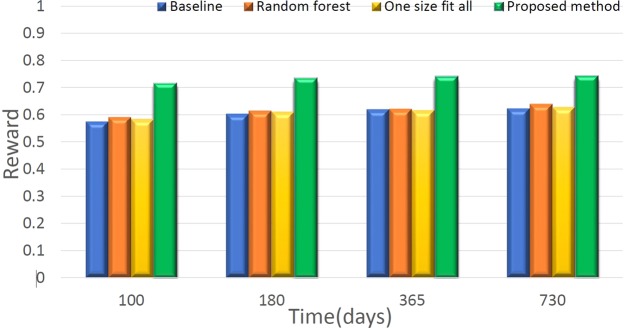
This paper presents the deep reinforcement learning (DRL) framework to estimate the optimal Dynamic Treatment Regimes from observational medical data. This framework is more flexible and adaptive for high dimensional action and state spaces than existing reinforcement learning methods to model real-life complexity in heterogeneous disease progression and treatment choices, with the goal of providing doctors and patients the data-driven personalized decision recommendations. The proposed DRL framework comprises (i) a supervised learning step to predict expert actions, and (ii) a deep reinforcement learning step to estimate the long-term value function of Dynamic Treatment Regimes. Both steps depend on deep neural networks. As a key motivational example, we have implemented the proposed framework on a data set from the Center for International Bone Marrow Transplant Research (CIBMTR) registry database, focusing on the sequence of prevention and treatments for acute and chronic graft versus host disease after transplantation. In the experimental results, we have demonstrated promising accuracy in predicting human experts' decisions, as well as the high expected reward function in the DRL-based dynamic treatment regimes.
本文提出了一种基于深度强化学习(DRL)的框架,用于从观察性医学数据中估计最优的动态治疗方案。与现有的强化学习方法相比,该框架在处理高维动作和状态空间方面更加灵活和自适应,能够模拟异质疾病进展和治疗选择中的实际复杂性,旨在为医生和患者提供数据驱动的个性化决策建议。所提出的 DRL 框架包括(i)一个用于预测专家动作的监督学习步骤,以及(ii)一个用于估计动态治疗方案的长期价值函数的深度强化学习步骤。这两个步骤都依赖于深度神经网络。作为一个关键的动机示例,我们已经在来自国际骨髓移植研究中心(CIBMTR)注册数据库的数据集中实现了所提出的框架,重点关注移植后急性和慢性移植物抗宿主病的预防和治疗序列。在实验结果中,我们证明了在预测人类专家决策方面具有很高的准确性,以及基于 DRL 的动态治疗方案中的高预期奖励函数。