Ricart Emma, Leclère Valérie, Flissi Areski, Mueller Markus, Pupin Maude, Lisacek Frédérique
Proteome Informatics Group, SIB Swiss Institute of Bioinformatics, CMU, Rue Michel-Servet 1, 1211, Geneva, Switzerland.
Computer Science Department, University of Geneva, Geneva, Switzerland.
J Cheminform. 2019 Feb 8;11(1):13. doi: 10.1186/s13321-019-0335-x.
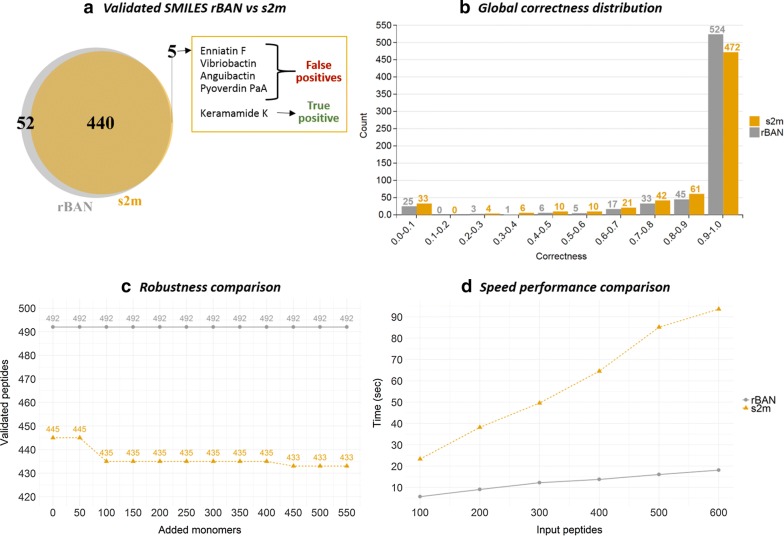
Proteinogenic and non-proteinogenic amino acids, fatty acids or glycans are some of the main building blocks of nonribsosomal peptides (NRPs) and as such may give insight into the origin, biosynthesis and bioactivities of their constitutive peptides. Hence, the structural representation of NRPs using monomers provides a biologically interesting skeleton of these secondary metabolites. Databases dedicated to NRPs such as Norine, already integrate monomer-based annotations in order to facilitate the development of structural analysis tools. In this paper, we present rBAN (retro-biosynthetic analysis of nonribosomal peptides), a new computational tool designed to predict the monomeric graph of NRPs from their atomic structure in SMILES format. This prediction is achieved through the "in silico" fragmentation of a chemical structure and matching the resulting fragments against the monomers of Norine for identification. Structures containing monomers not yet recorded in Norine, are processed in a "discovery mode" that uses the RESTful service from PubChem to search the unidentified substructures and suggest new monomers. rBAN was integrated in a pipeline for the curation of Norine data in which it was used to check the correspondence between the monomeric graphs annotated in Norine and SMILES-predicted graphs. The process concluded with the validation of the 97.26% of the records in Norine, a two-fold extension of its SMILES data and the introduction of 11 new monomers suggested in the discovery mode. The accuracy, robustness and high-performance of rBAN were demonstrated in benchmarking it against other tools with the same functionality: Smiles2Monomers and GRAPE.
蛋白质氨基酸和非蛋白质氨基酸、脂肪酸或聚糖是非核糖体肽(NRP)的一些主要组成部分,因此可以深入了解其组成肽的起源、生物合成和生物活性。因此,使用单体对NRP进行结构表征为这些次生代谢产物提供了一个具有生物学意义的骨架。专门用于NRP的数据库,如Norine,已经整合了基于单体的注释,以促进结构分析工具的开发。在本文中,我们介绍了rBAN(非核糖体肽的逆向生物合成分析),这是一种新的计算工具,旨在从SMILES格式的原子结构预测NRP的单体图。这种预测是通过对化学结构进行“计算机模拟”碎片化,并将所得片段与Norine的单体进行匹配以进行识别来实现的。包含尚未在Norine中记录的单体的结构,以“发现模式”进行处理,该模式使用来自PubChem的RESTful服务搜索未识别的子结构并提出新的单体。rBAN被整合到一个用于整理Norine数据的流程中,在该流程中,它被用于检查Norine中注释的单体图与SMILES预测图之间的对应关系。该过程最终验证了Norine中97.26%的记录,其SMILES数据扩展了两倍,并引入了发现模式中建议的11种新单体。通过与具有相同功能的其他工具Smiles2Monomers和GRAPE进行基准测试,证明了rBAN的准确性、稳健性和高性能。