McPadden Jacob, Durant Thomas Js, Bunch Dustin R, Coppi Andreas, Price Nathaniel, Rodgerson Kris, Torre Charles J, Byron William, Hsiao Allen L, Krumholz Harlan M, Schulz Wade L
Department of Pediatrics, Yale University School of Medicine, New Haven, CT, United States.
Department of Laboratory Medicine, Yale University School of Medicine, New Haven, CT, United States.
J Med Internet Res. 2019 Apr 9;21(4):e13043. doi: 10.2196/13043.
Health care data are increasing in volume and complexity. Storing and analyzing these data to implement precision medicine initiatives and data-driven research has exceeded the capabilities of traditional computer systems. Modern big data platforms must be adapted to the specific demands of health care and designed for scalability and growth.
The objectives of our study were to (1) demonstrate the implementation of a data science platform built on open source technology within a large, academic health care system and (2) describe 2 computational health care applications built on such a platform.
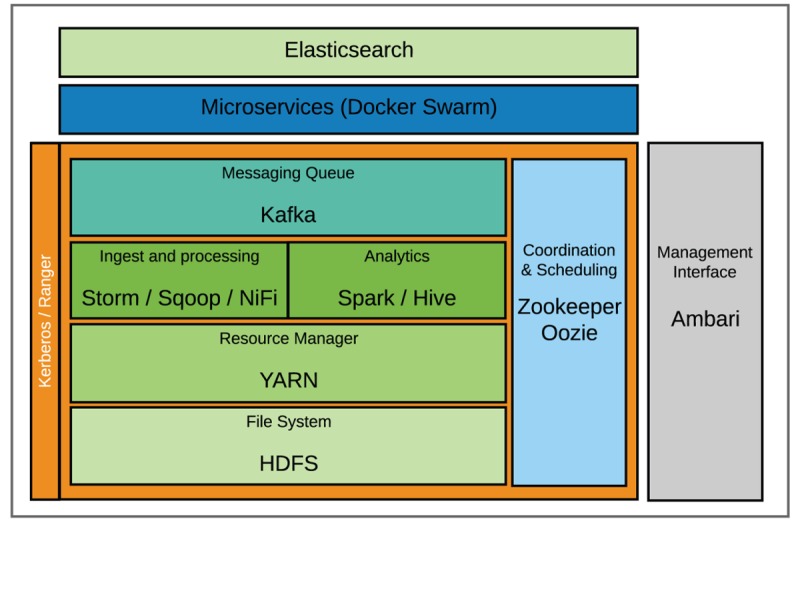
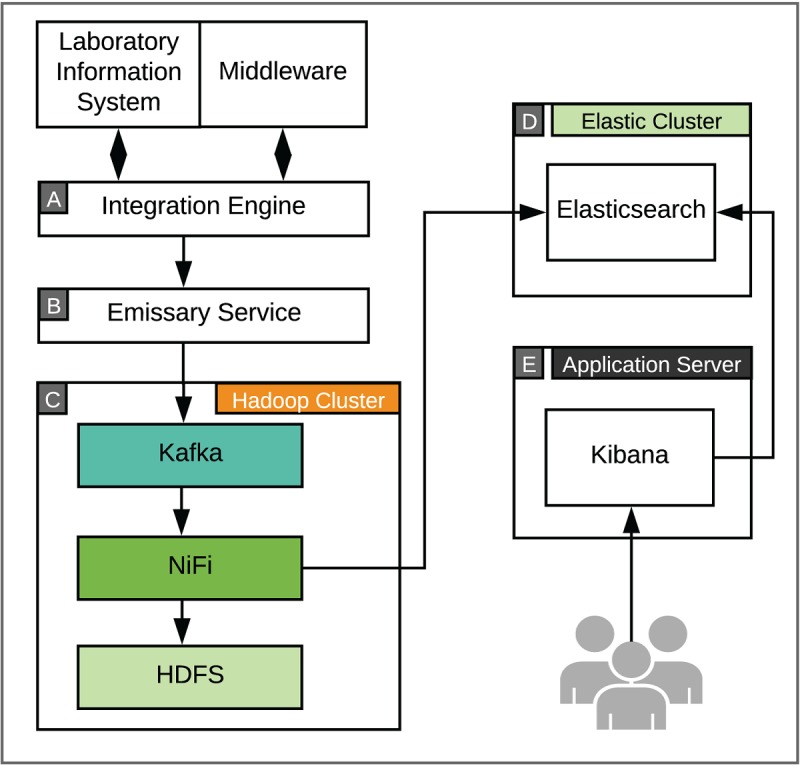
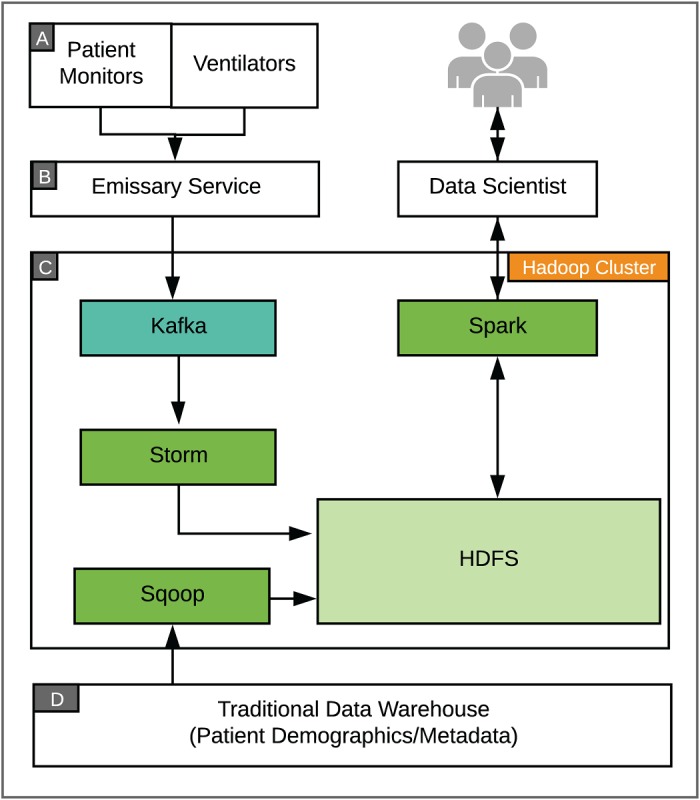
We deployed a data science platform based on several open source technologies to support real-time, big data workloads. We developed data-acquisition workflows for Apache Storm and NiFi in Java and Python to capture patient monitoring and laboratory data for downstream analytics.
Emerging data management approaches, along with open source technologies such as Hadoop, can be used to create integrated data lakes to store large, real-time datasets. This infrastructure also provides a robust analytics platform where health care and biomedical research data can be analyzed in near real time for precision medicine and computational health care use cases.
The implementation and use of integrated data science platforms offer organizations the opportunity to combine traditional datasets, including data from the electronic health record, with emerging big data sources, such as continuous patient monitoring and real-time laboratory results. These platforms can enable cost-effective and scalable analytics for the information that will be key to the delivery of precision medicine initiatives. Organizations that can take advantage of the technical advances found in data science platforms will have the opportunity to provide comprehensive access to health care data for computational health care and precision medicine research.
医疗保健数据的数量和复杂性正在不断增加。存储和分析这些数据以实施精准医疗计划和数据驱动型研究已超出传统计算机系统的能力范围。现代大数据平台必须适应医疗保健的特定需求,并设计为具有可扩展性和增长性。
我们研究的目的是:(1)展示在大型学术医疗保健系统中基于开源技术构建的数据科学平台的实施情况;(2)描述基于此类平台构建的两个计算医疗保健应用程序。
我们部署了一个基于多种开源技术的数据科学平台,以支持实时大数据工作负载。我们用Java和Python为Apache Storm和NiFi开发了数据采集工作流程,以捕获患者监测数据和实验室数据,用于下游分析。
新兴的数据管理方法以及诸如Hadoop之类的开源技术可用于创建集成数据湖,以存储大型实时数据集。该基础设施还提供了一个强大的分析平台,可在该平台上对医疗保健和生物医学研究数据进行近实时分析,以用于精准医疗和计算医疗保健用例。
集成数据科学平台的实施和使用为各组织提供了机会,可将包括电子健康记录数据在内的传统数据集与新兴大数据源(如持续的患者监测数据和实时实验室结果)相结合。这些平台可为对精准医疗计划的实施至关重要的信息提供具有成本效益且可扩展的分析。能够利用数据科学平台中技术进步的组织将有机会为计算医疗保健和精准医学研究提供全面的医疗保健数据访问。