Shapcott Mary, Hewitt Katherine J, Rajpoot Nasir
Department of Computer Science, University of Warwick, Coventry, United Kingdom.
Cellular Pathology Department, University Hospital of Coventry and Warwickshire, Coventry, United Kingdom.
Front Bioeng Biotechnol. 2019 Mar 27;7:52. doi: 10.3389/fbioe.2019.00052. eCollection 2019.
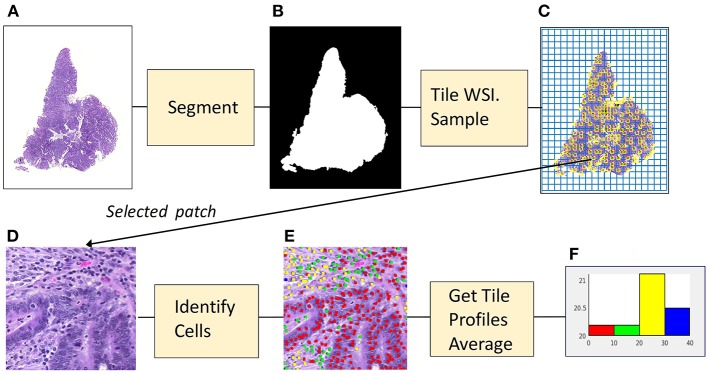
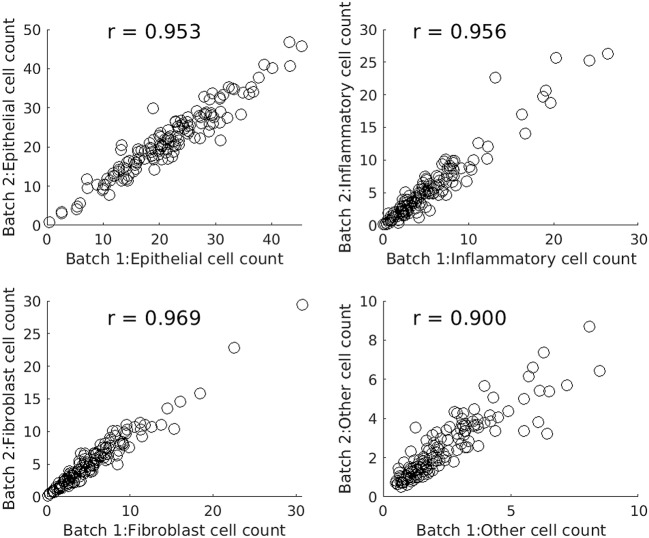
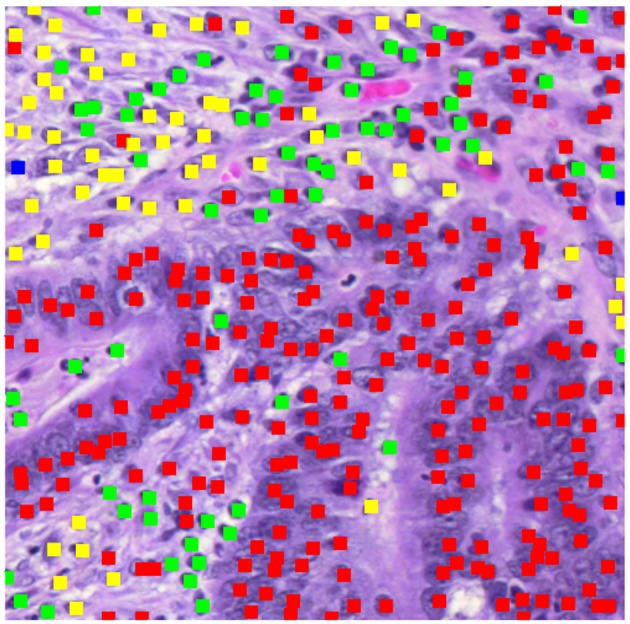
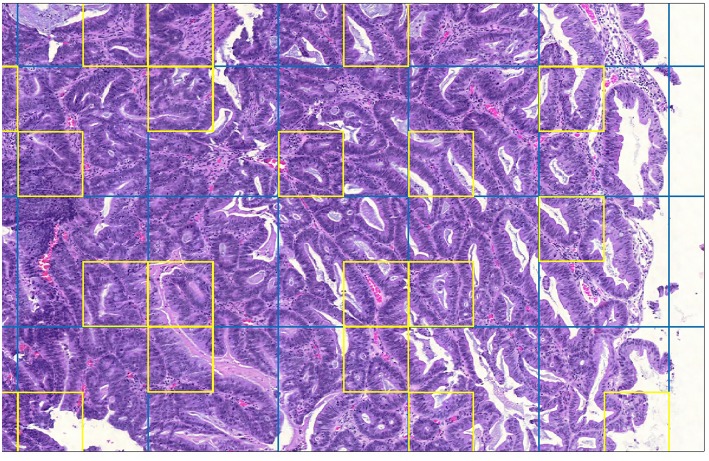
This study applied a deep-learning cell identification algorithm to diagnostic images from the colon cancer repository at The Cancer Genome Atlas (TCGA). Within-image sampling improved performance without loss of accuracy. The features thus derived were associated with various clinical variables including metastasis, residual tumor, venous invasion, and lymphatic invasion. The deep-learning algorithm was trained using images from a locally available data set, then applied to the TCGA images by tiling them, and identifying cells in each patch defined by the tiling. In this application the average number of patches containing tissue in an image was 900. Processing a random sample of patches greatly reduced computation costs. The cell identification algorithm was applied directly to each sampled patch, resulting in a list of cells. Each cell was labeled with its location and classification ("epithelial," "inflammatory," "fibroblast," or "other"). The number of cells of a given type in the patch was calculated, resulting in a patch profile containing four features. A morphological profile that applied to the entire image was obtained by averaging profiles over all patches. Two sampling policies were examined. The first policy was random sampling which samples patches with uniform weighting. The second policy was systematic random sampling which takes spatial dependencies into account. Compared with the processing of complete whole slide images there was a seven-fold improvement in performance when systematic random spatial sampling was used to select 100 tiles from the whole-slide image for processing, with very little loss of accuracy (4% on average). We found links between the predicted features and clinical variables in the TCGA colon cancer data set. Several significant associations were found: increased fibroblast numbers were associated with the presence of metastasis, venous invasion, lymphatic invasion and residual tumor while decreased numbers of inflammatory cells were associated with mucinous carcinomas. Regarding the four different types of cell, deep learning has generated morphological features that are indicators of cell density. The features are related to cellularity, the numbers, degree, or quality of cells present in a tumor. Cellularity has been reported to be related to patient survival and other diagnostic and prognostic indicators, indicating that the features calculated here may be of general usefulness.
本研究将一种深度学习细胞识别算法应用于来自癌症基因组图谱(TCGA)结肠癌数据库的诊断图像。图像内采样提高了性能且不损失准确性。由此得出的特征与包括转移、残留肿瘤、静脉侵犯和淋巴侵犯在内的各种临床变量相关。深度学习算法使用本地可用数据集的图像进行训练,然后通过平铺TCGA图像并识别由平铺定义的每个小块中的细胞,将其应用于TCGA图像。在此应用中,图像中包含组织的小块的平均数量约为900个。处理小块的随机样本大大降低了计算成本。细胞识别算法直接应用于每个采样小块,生成一个细胞列表。每个细胞都用其位置和分类(“上皮细胞”、“炎症细胞”、“成纤维细胞”或“其他”)进行标记。计算小块中给定类型细胞的数量,得出包含四个特征的小块概况。通过对所有小块的概况求平均值,获得适用于整个图像的形态学概况。研究了两种采样策略。第一种策略是随机采样,即对小块进行均匀加权采样。第二种策略是系统随机采样,它考虑了空间依赖性。与处理完整的全玻片图像相比,当使用系统随机空间采样从全玻片图像中选择100个小块进行处理时,性能提高了7倍,准确性损失极小(平均约4%)。我们在TCGA结肠癌数据集中发现了预测特征与临床变量之间的联系。发现了几个显著关联:成纤维细胞数量增加与转移、静脉侵犯、淋巴侵犯和残留肿瘤的存在相关,而炎症细胞数量减少与黏液腺癌相关。关于四种不同类型的细胞,深度学习生成了作为细胞密度指标的形态学特征。这些特征与细胞构成有关,即肿瘤中存在的细胞数量、程度或质量。据报道,细胞构成与患者生存率以及其他诊断和预后指标相关,这表明此处计算的特征可能具有普遍用途。