Lee Michael Y, Hu Ting
Faculty of Medicine, Memorial University, St. John's, NL A1B 3V6, Canada.
Department of Computer Science, Memorial University, St. John's, NL A1B 3X5, Canada.
Metabolites. 2019 Apr 4;9(4):66. doi: 10.3390/metabo9040066.
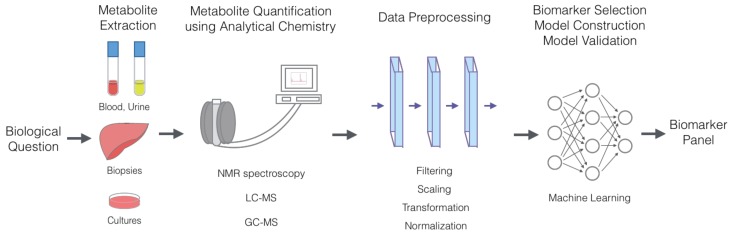
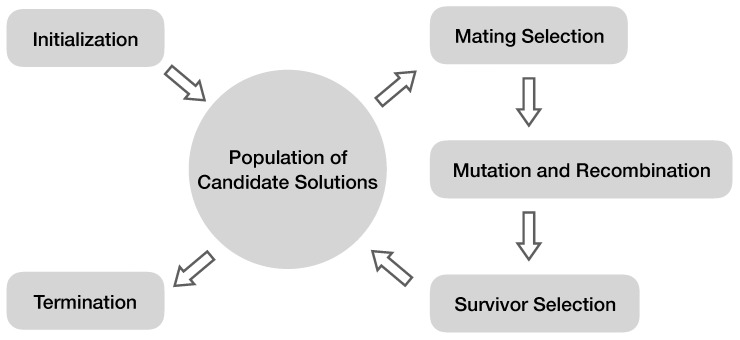
Metabolomics uses quantitative analyses of metabolites from tissues or bodily fluids to acquire a functional readout of the physiological state. Complex diseases arise from the influence of multiple factors, such as genetics, environment and lifestyle. Since genes, RNAs and proteins converge onto the terminal downstream metabolome, metabolomics datasets offer a rich source of information in a complex and convoluted presentation. Thus, powerful computational methods capable of deciphering the effects of many upstream influences have become increasingly necessary. In this review, the workflow of metabolic marker discovery is outlined from metabolite extraction to model interpretation and validation. Additionally, current metabolomics research in various complex disease areas is examined to identify gaps and trends in the use of several statistical and computational algorithms. Then, we highlight and discuss three advanced machine-learning algorithms, specifically ensemble learning, artificial neural networks, and genetic programming, that are currently less visible, but are budding with high potential for utility in metabolomics research. With an upward trend in the use of highly-accurate, multivariate models in the metabolomics literature, diagnostic biomarker panels of complex diseases are more recently achieving accuracies approaching or exceeding traditional diagnostic procedures. This review aims to provide an overview of computational methods in metabolomics and promote the use of up-to-date machine-learning and computational methods by metabolomics researchers.
代谢组学利用对组织或体液中代谢物的定量分析来获取生理状态的功能读数。复杂疾病是由多种因素的影响引起的,如遗传、环境和生活方式。由于基因、RNA和蛋白质都汇聚到终端下游代谢组,代谢组学数据集以复杂而费解的形式提供了丰富的信息来源。因此,能够解读许多上游影响因素作用的强大计算方法变得越来越必要。在这篇综述中,我们概述了从代谢物提取到模型解释与验证的代谢标志物发现工作流程。此外,我们还研究了当前在各种复杂疾病领域的代谢组学研究,以确定几种统计和计算算法在使用中的差距和趋势。然后,我们重点介绍并讨论三种先进的机器学习算法,即集成学习、人工神经网络和遗传编程,它们目前不太受关注,但在代谢组学研究中具有很高的应用潜力。随着代谢组学文献中使用高精度多变量模型的趋势上升,复杂疾病的诊断生物标志物面板最近的准确率已接近或超过传统诊断程序。这篇综述旨在概述代谢组学中的计算方法,并促进代谢组学研究人员使用最新的机器学习和计算方法。