Department of Medicine, Stanford University, Stanford, CA, USA.
Department of Medicine, Stanford University, Stanford, CA, USA; Department of Biomedical Data Science, Stanford University, Stanford, USA.
J Biomed Inform. 2019 Jun;94:103184. doi: 10.1016/j.jbi.2019.103184. Epub 2019 Apr 20.
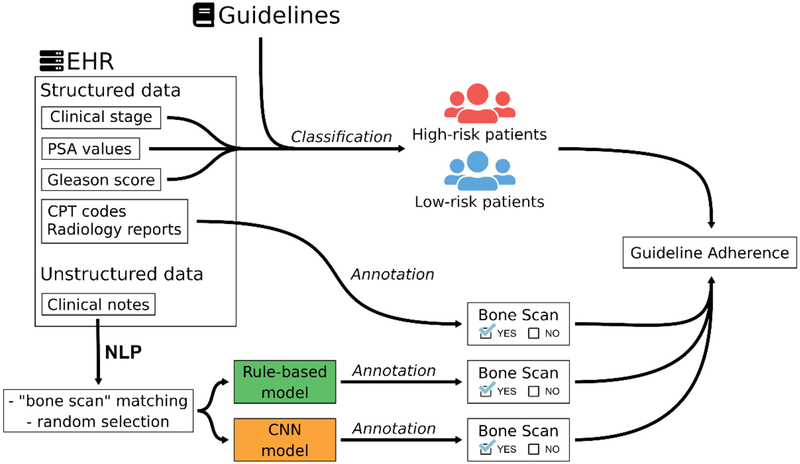
Clinical care guidelines recommend that newly diagnosed prostate cancer patients at high risk for metastatic spread receive a bone scan prior to treatment and that low risk patients not receive it. The objective was to develop an automated pipeline to interrogate heterogeneous data to evaluate the use of bone scans using a two different Natural Language Processing (NLP) approaches.
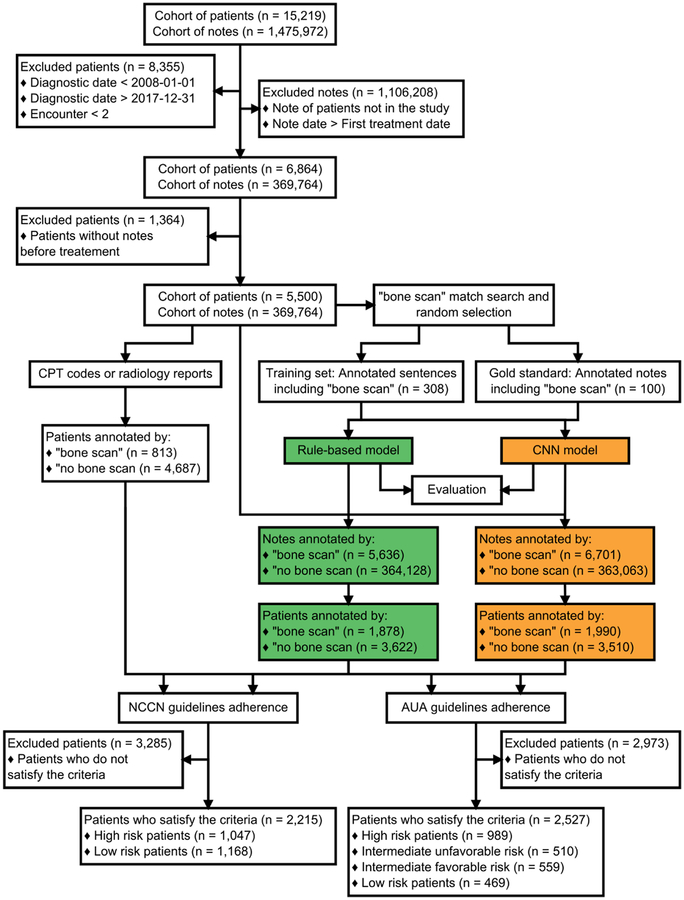
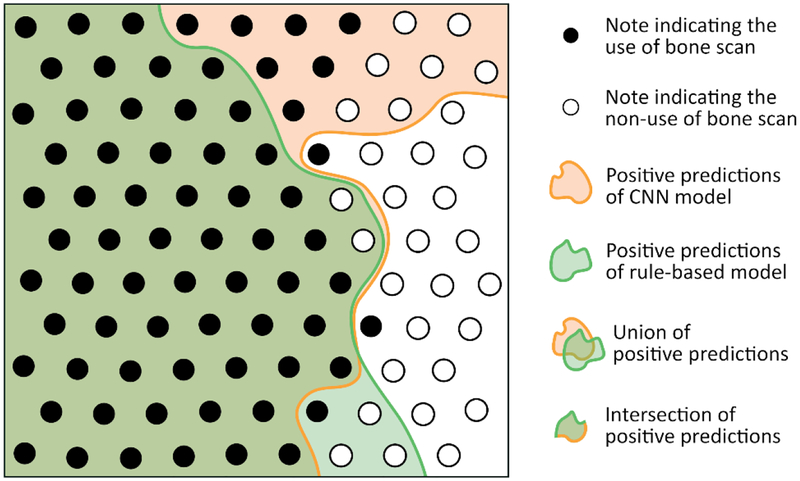
Our cohort was divided into risk groups based on Electronic Health Records (EHR). Information on bone scan utilization was identified in both structured data and free text from clinical notes. Our pipeline annotated sentences with a combination of a rule-based method using the ConText algorithm (a generalization of NegEx) and a Convolutional Neural Network (CNN) method using word2vec to produce word embeddings.
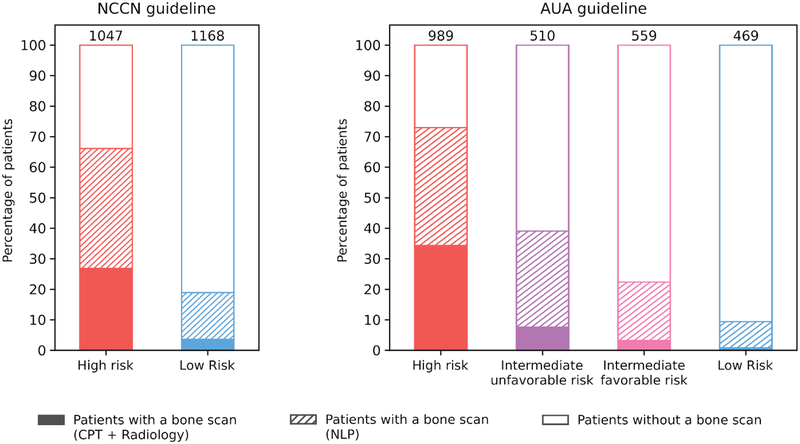
A total of 5500 patients and 369,764 notes were included in the study. A total of 39% of patients were high-risk and 73% of these received a bone scan; of the 18% low risk patients, 10% received one. The accuracy of CNN model outperformed the rule-based model one (F-measure = 0.918 and 0.897 respectively). We demonstrate a combination of both models could maximize precision or recall, based on the study question.
Using structured data, we accurately classified patients' cancer risk group, identified bone scan documentation with two NLP methods, and evaluated guideline adherence. Our pipeline can be used to provide concrete feedback to clinicians and guide treatment decisions.
临床护理指南建议,对有转移扩散高风险的新诊断前列腺癌患者,在治疗前进行骨扫描,而低风险患者则无需进行骨扫描。本研究旨在开发一个自动分析异构数据的管道,使用两种不同的自然语言处理(NLP)方法来评估骨扫描的使用情况。
我们的队列根据电子健康记录(EHR)分为风险组。骨扫描使用情况的信息是从临床记录的结构化数据和自由文本中识别出来的。我们的管道使用基于 ConText 算法(NegEx 的泛化)的规则方法和使用 word2vec 生成词向量的卷积神经网络(CNN)方法相结合,对句子进行注释。
共纳入 5500 名患者和 369764 份病历。共有 39%的患者为高危,其中 73%的患者接受了骨扫描;18%的低危患者中,有 10%接受了骨扫描。CNN 模型的准确性优于基于规则的模型(F 度量分别为 0.918 和 0.897)。我们展示了可以根据研究问题,结合使用这两种模型来最大化精度或召回率。
使用结构化数据,我们准确地对患者的癌症风险组进行分类,使用两种 NLP 方法识别骨扫描文档,并评估指南的依从性。我们的管道可以为临床医生提供具体的反馈,并指导治疗决策。