Key Laboratory of Maricultural Organism Disease Control, Ministry of Agriculture; Laboratory for Marine Fisheries Science and Food Production Processes, Qingdao National Laboratory for Marine Science and Technology; Qingdao Key Laboratory of Mariculture Epidemiology and Biosecurity; Yellow Sea Fisheries Research Institute, Chinese Academy of Fishery Sciences, 106 Nanjing Road, Qingdao 266071, China.
Department of Biology, University of Padua, Via Ugo Bassi 58/B, Padua 35121, Italy.
Gigascience. 2019 Jul 1;8(7). doi: 10.1093/gigascience/giz067.
The blood clam, Scapharca (Anadara) broughtonii, is an economically and ecologically important marine bivalve of the family Arcidae. Efforts to study their population genetics, breeding, cultivation, and stock enrichment have been somewhat hindered by the lack of a reference genome. Herein, we report the complete genome sequence of S. broughtonii, a first reference genome of the family Arcidae.
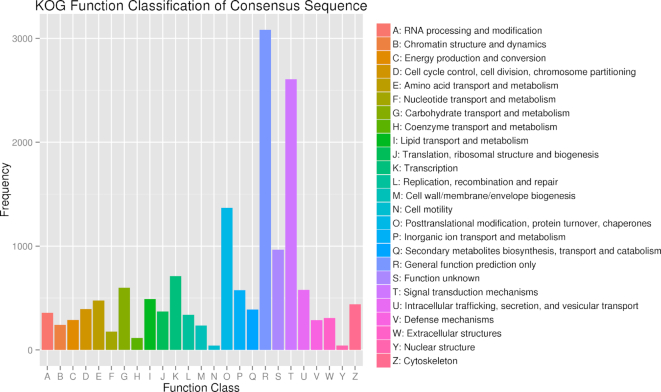
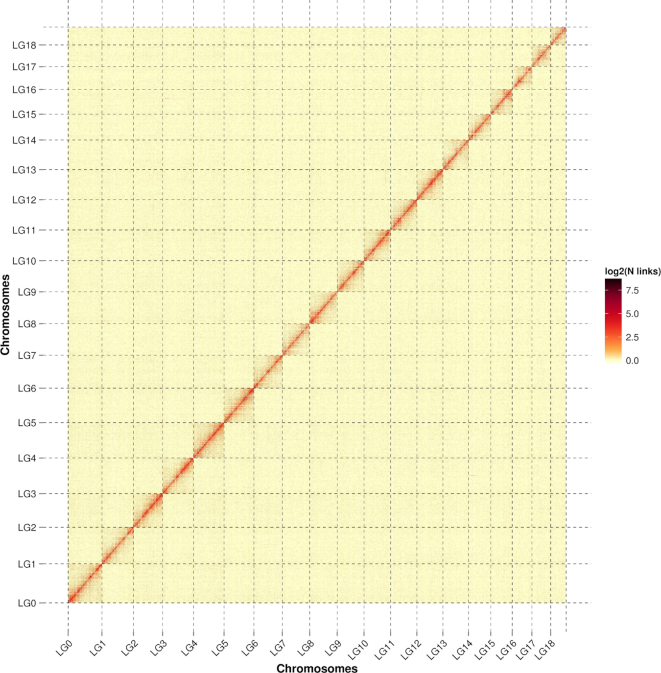
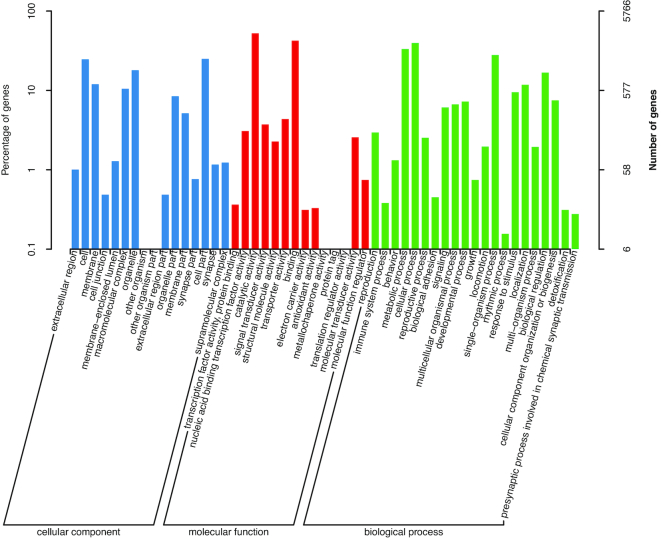
A total of 75.79 Gb clean data were generated with the Pacific Biosciences and Oxford Nanopore platforms, which represented approximately 86× coverage of the S. broughtonii genome. De novo assembly of these long reads resulted in an 884.5-Mb genome, with a contig N50 of 1.80 Mb and scaffold N50 of 45.00 Mb. Genome Hi-C scaffolding resulted in 19 chromosomes containing 99.35% of bases in the assembled genome. Genome annotation revealed that nearly half of the genome (46.1%) is composed of repeated sequences, while 24,045 protein-coding genes were predicted and 84.7% of them were annotated.
We report here a chromosomal-level assembly of the S. broughtonii genome based on long-read sequencing and Hi-C scaffolding. The genomic data can serve as a reference for the family Arcidae and will provide a valuable resource for the scientific community and aquaculture sector.
血蛤,Scapharca (Anadara) broughtonii,是帘蛤目帘蛤科的一种具有重要经济和生态价值的海洋双壳贝类。由于缺乏参考基因组,对其种群遗传学、繁殖、养殖和种群富集的研究工作受到了一定的阻碍。本文报道了 Scapharca (Anadara) broughtonii 的完整基因组序列,这是帘蛤科的第一个参考基因组。
使用 Pacific Biosciences 和 Oxford Nanopore 平台共生成了 75.79 Gb 的清洁数据,大约覆盖了 Scapharca (Anadara) broughtonii 基因组的 86 倍。这些长读长的从头组装产生了一个 884.5-Mb 的基因组,其 contig N50 为 1.80 Mb,scaffold N50 为 45.00 Mb。基因组 Hi-C 支架得到了 19 条染色体,包含组装基因组中 99.35%的碱基。基因组注释表明,近一半的基因组(46.1%)由重复序列组成,预测了 24045 个蛋白质编码基因,其中 84.7%得到了注释。
本文基于长读测序和 Hi-C 支架构建了 Scapharca (Anadara) broughtonii 的染色体水平基因组组装。该基因组数据可以作为帘蛤科的参考基因组,为科学界和水产养殖部门提供有价值的资源。