Centre of Health eResearch, School of Health Sciences, Faculty of Biology, Medicine and Health, The University of Manchester, Oxford Road, Manchester, M13 9PL, UK.
Department of Biostatistics and Health Informatics, Institute of Psychiatry, Psychology and Neuroscience, King's College London, De Crispigny Park, London, SE5 8AF, UK.
BMC Med. 2019 Jul 17;17(1):134. doi: 10.1186/s12916-019-1368-8.
Risk prediction models are commonly used in practice to inform decisions on patients' treatment. Uncertainty around risk scores beyond the confidence interval is rarely explored. We conducted an uncertainty analysis of the QRISK prediction tool to evaluate the robustness of individual risk predictions with varying modelling decisions.
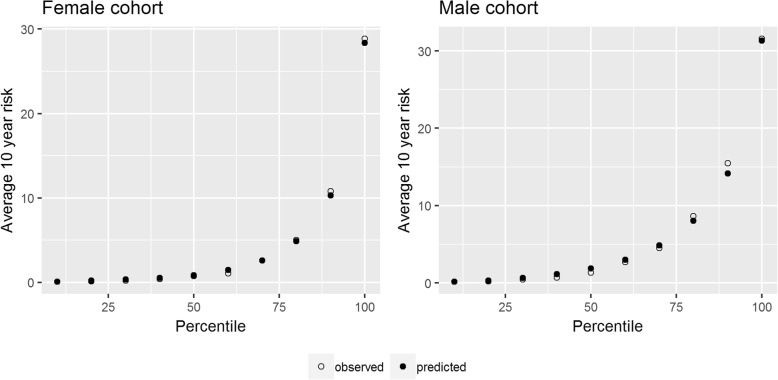
We derived a cohort of patients eligible for cardiovascular risk prediction from the Clinical Practice Research Datalink (CPRD) with linked hospitalisation and mortality records (N = 3,792,474). Risk prediction models were developed using the methods reported for QRISK2 and 3, before adjusting for additional risk factors, a secular trend, geographical variation in risk and the method for imputing missing data when generating a risk score (model A-model F). Ten-year risk scores were compared across the different models alongside model performance metrics.
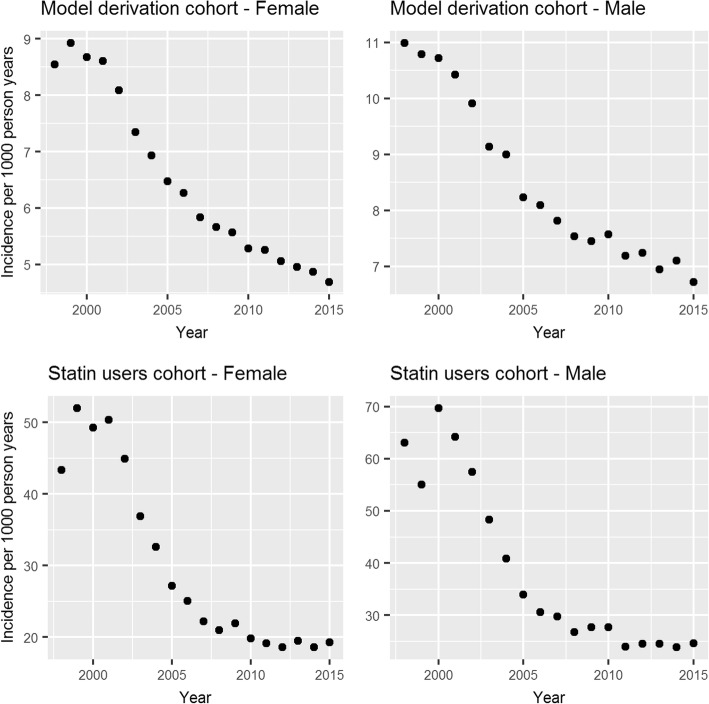
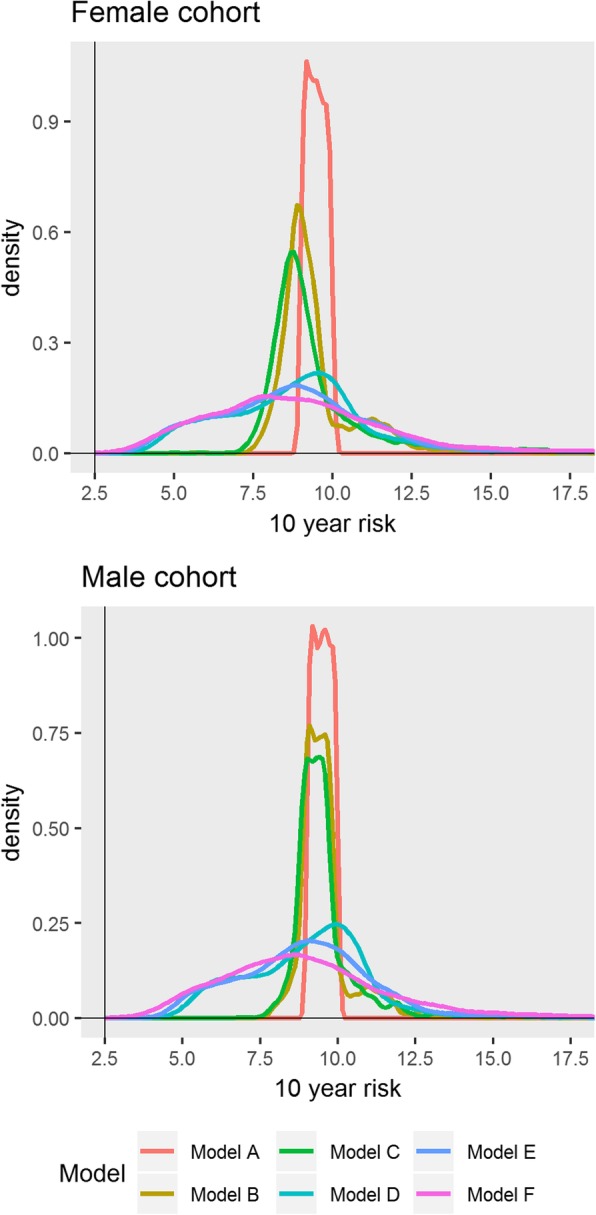
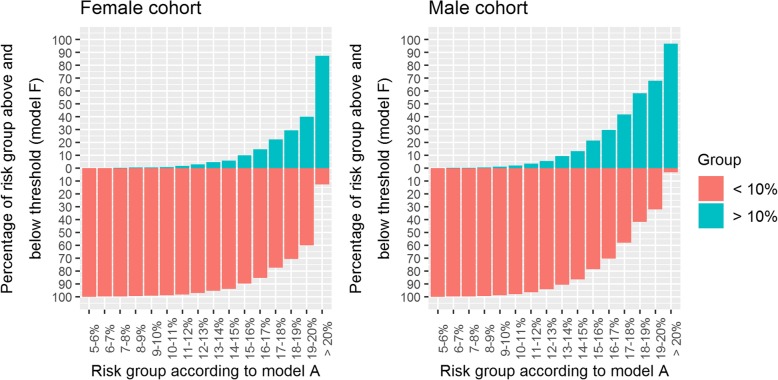
We found substantial variation in risk on the individual level across the models. The 95 percentile range of risks in model F for patients with risks between 9 and 10% according to model A was 4.4-16.3% and 4.6-15.8% for females and males respectively. Despite this, the models were difficult to distinguish using common performance metrics (Harrell's C ranged from 0.86 to 0.87). The largest contributing factor to variation in risk was adjusting for a secular trend (HR per calendar year, 0.96 [0.95-0.96] and 0.96 [0.96-0.96]). When extrapolating to the UK population, we found that 3.8 million patients may be reclassified as eligible for statin prescription depending on the model used. A key limitation of this study was that we could not assess the variation in risk that may be caused by risk factors missing from the database (such as diet or physical activity).
Risk prediction models that use routinely collected data provide estimates strongly dependent on modelling decisions. Despite this large variability in patient risk, the models appear to perform similarly according to standard performance metrics. Decision-making should be supplemented with clinical judgement and evidence of additional risk factors. The largest source of variability, a secular trend in CVD incidence, can be accounted for and should be explored in more detail.
风险预测模型常用于为患者治疗决策提供信息。但风险评分的置信区间外的不确定性很少被探索。我们对 QRISK 预测工具进行了不确定性分析,以评估不同建模决策下个体风险预测的稳健性。
我们从临床实践研究数据链(CPRD)中提取了一个适合心血管风险预测的队列,该队列与住院和死亡率记录相关联(N=3,792,474)。使用 QRISK2 和 3 报告的方法开发风险预测模型,然后针对其他风险因素、趋势变化、风险的地域差异以及生成风险评分时缺失数据的处理方法(模型 A 至模型 F)进行调整。在不同模型之间比较了 10 年风险评分以及模型性能指标。
我们发现模型之间个体水平的风险存在很大差异。在模型 F 中,根据模型 A,风险在 9%至 10%之间的患者的风险 95%范围为 4.4%-16.3%,女性和男性分别为 4.6%-15.8%。尽管如此,这些模型仍难以通过常见的性能指标进行区分(哈雷尔 C 范围为 0.86 至 0.87)。导致风险差异的最大因素是调整趋势变化(每年每增加一年,HR 为 0.96[0.95-0.96]和 0.96[0.96-0.96])。当外推到英国人群时,我们发现,取决于使用的模型,可能有 380 万患者被重新归类为符合他汀类药物处方条件。本研究的一个主要局限性是我们无法评估数据库中缺失的风险因素(如饮食或体育活动)可能导致的风险变化。
使用常规收集数据的风险预测模型提供的估计值强烈依赖于建模决策。尽管患者风险存在很大差异,但根据标准性能指标,这些模型似乎表现相似。决策应辅以临床判断和额外风险因素的证据。最大的变异性来源,即 CVD 发病率的趋势变化,可以被解释,并应更详细地探讨。