Lv Hao, Dao Fu-Ying, Guan Zheng-Xing, Zhang Dan, Tan Jiu-Xin, Zhang Yong, Chen Wei, Lin Hao
Key Laboratory for Neuro-Information of Ministry of Education, School of Life Science and Technology, Center for Informational Biology, University of Electronic Science and Technology of China, Chengdu, China.
Innovative Institute of Chinese Medicine and Pharmacy, Chengdu University of Traditional Chinese Medicine, Chengdu, China.
Front Genet. 2019 Sep 10;10:793. doi: 10.3389/fgene.2019.00793. eCollection 2019.
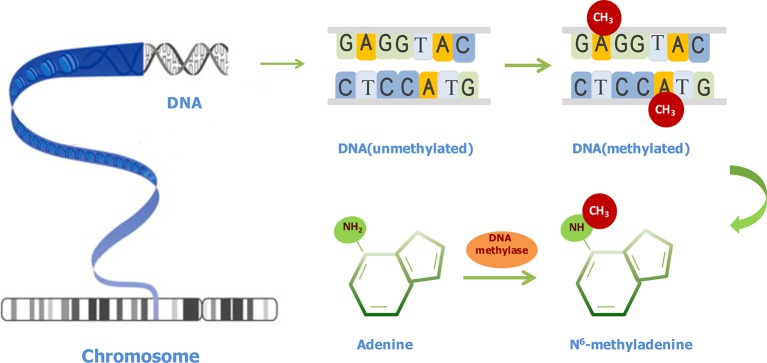
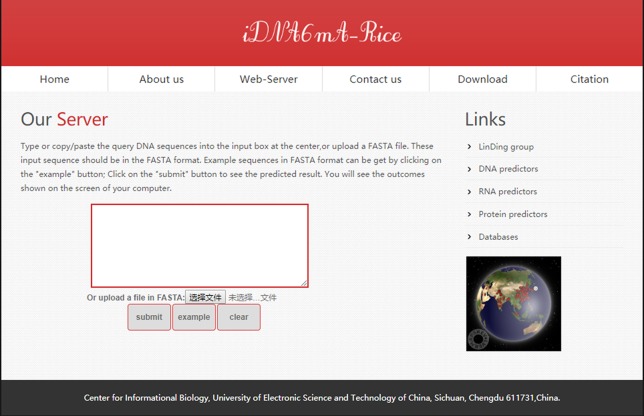
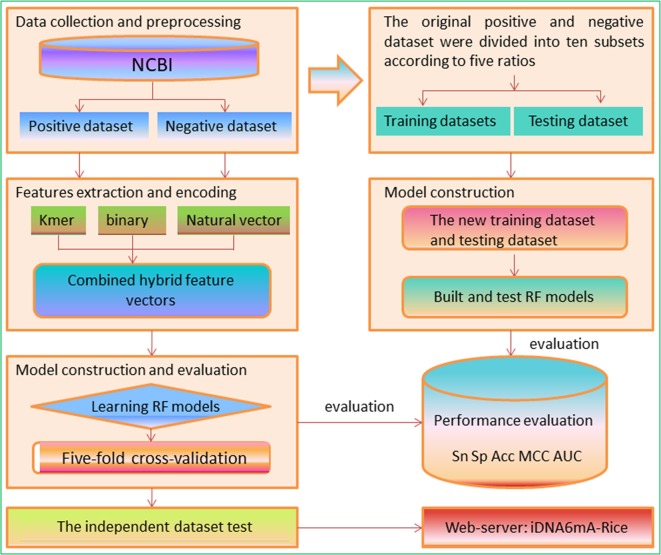
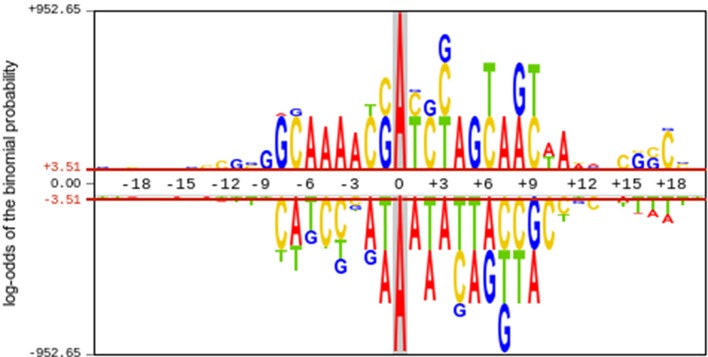
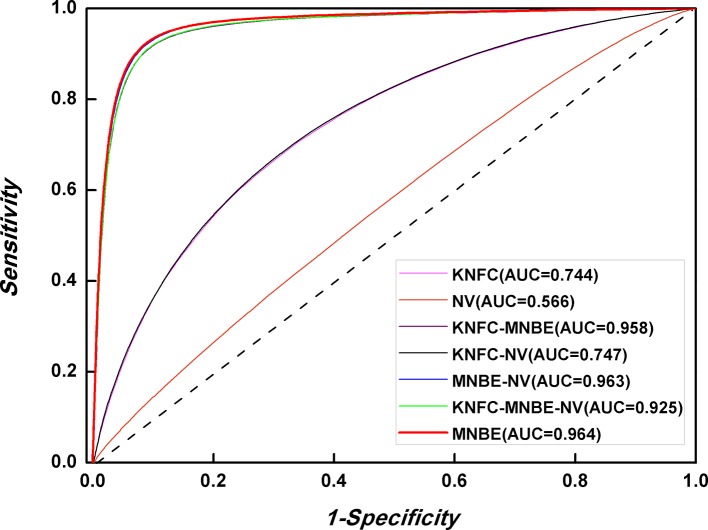
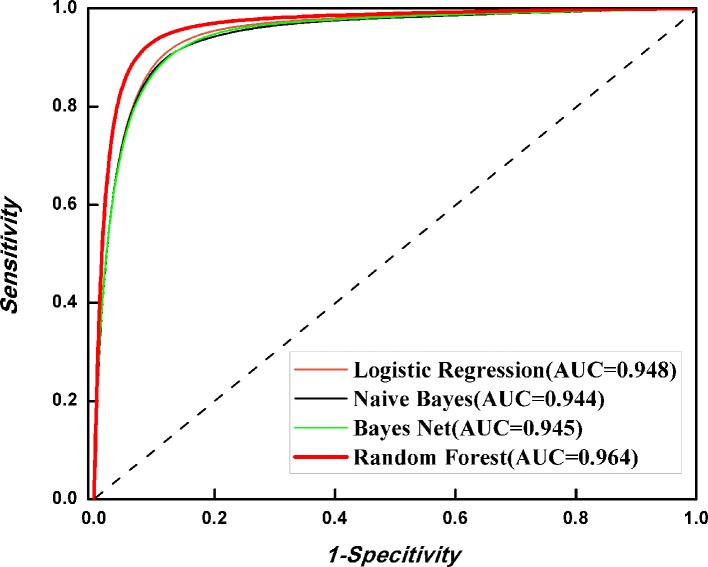
DNA N6-methyladenine (6mA) is a dominant DNA modification form and involved in many biological functions. The accurate genome-wide identification of 6mA sites may increase understanding of its biological functions. Experimental methods for 6mA detection in eukaryotes genome are laborious and expensive. Therefore, it is necessary to develop computational methods to identify 6mA sites on a genomic scale, especially for plant genomes. Based on this consideration, the study aims to develop a machine learning-based method of predicting 6mA sites in the rice genome. We initially used mono-nucleotide binary encoding to formulate positive and negative samples. Subsequently, the machine learning algorithm named Random Forest was utilized to perform the classification for identifying 6mA sites. Our proposed method could produce an area under the receiver operating characteristic curve of 0.964 with an overall accuracy of 0.917, as indicated by the fivefold cross-validation test. Furthermore, an independent dataset was established to assess the generalization ability of our method. Finally, an area under the receiver operating characteristic curve of 0.981 was obtained, suggesting that the proposed method had good performance of predicting 6mA sites in the rice genome. For the convenience of retrieving 6mA sites, on the basis of the computational method, we built a freely accessible web server named iDNA6mA-Rice at http://lin-group.cn/server/iDNA6mA-Rice.
DNA N6-甲基腺嘌呤(6mA)是一种主要的DNA修饰形式,参与多种生物学功能。对全基因组范围内6mA位点进行准确鉴定,可能会增进我们对其生物学功能的理解。真核生物基因组中6mA检测的实验方法既费力又昂贵。因此,有必要开发计算方法来在基因组规模上鉴定6mA位点,尤其是针对植物基因组。基于这一考虑,本研究旨在开发一种基于机器学习的方法来预测水稻基因组中的6mA位点。我们最初使用单核苷酸二进制编码来构建正样本和负样本。随后,利用名为随机森林的机器学习算法进行分类,以鉴定6mA位点。如五折交叉验证测试所示,我们提出的方法在受试者工作特征曲线下的面积为0.964,总体准确率为0.917。此外,还建立了一个独立数据集来评估我们方法的泛化能力。最后,获得了受试者工作特征曲线下面积为0.981的结果,表明所提出的方法在预测水稻基因组中6mA位点方面具有良好性能。为了方便检索6mA位点,基于该计算方法,我们在http://lin-group.cn/server/iDNA6mA-Rice构建了一个可免费访问的网络服务器,名为iDNA6mA-Rice。