Maisto D, Friston K, Pezzulo G
Institute for High Performance Computing and Networking, National Research Council, Via P. Castellino, 111, Naples 80131, Italy.
The Wellcome Trust Centre for Neuroimaging, Institute of Neurology, University College London, London, UK.
Neurocomputing (Amst). 2019 Sep 24;359:298-314. doi: 10.1016/j.neucom.2019.05.083.
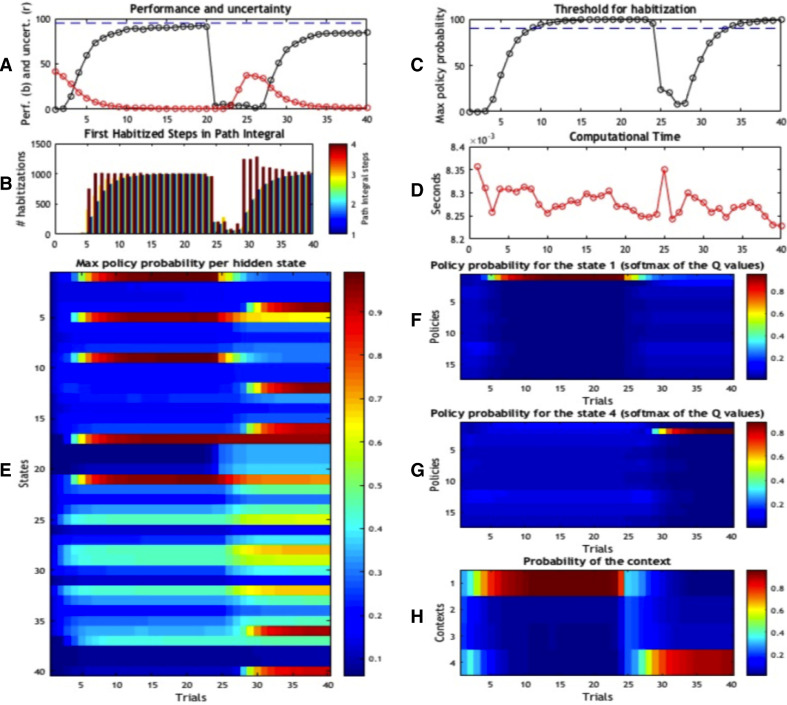
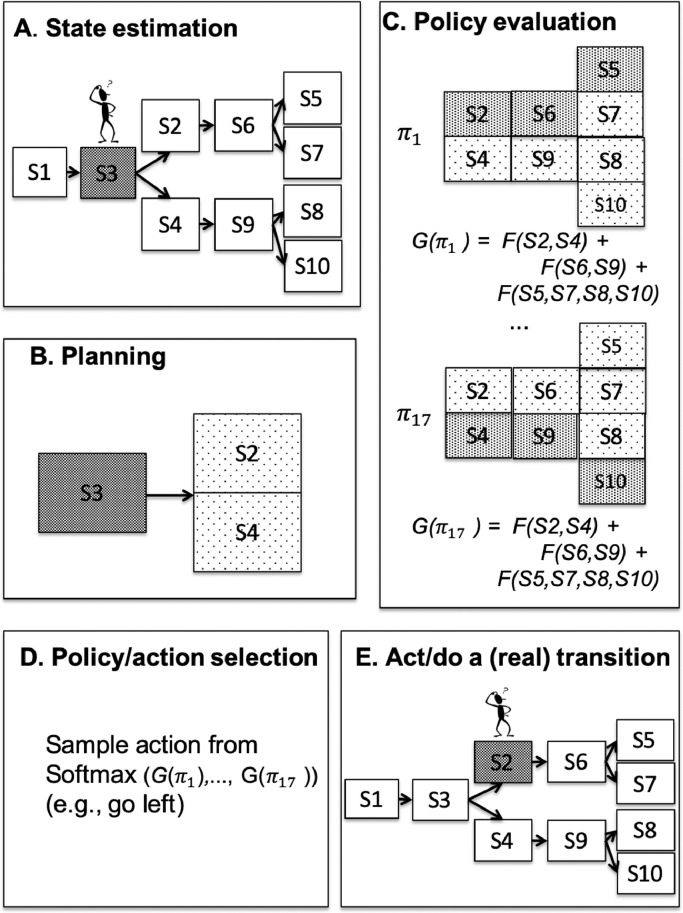
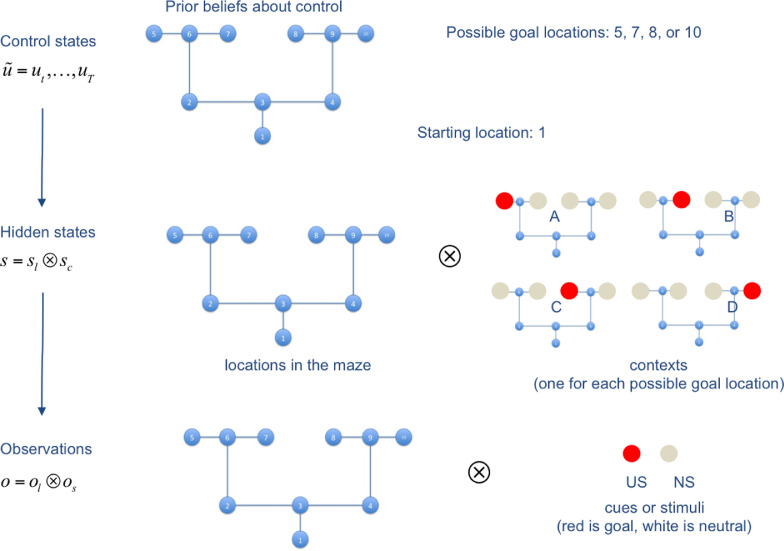
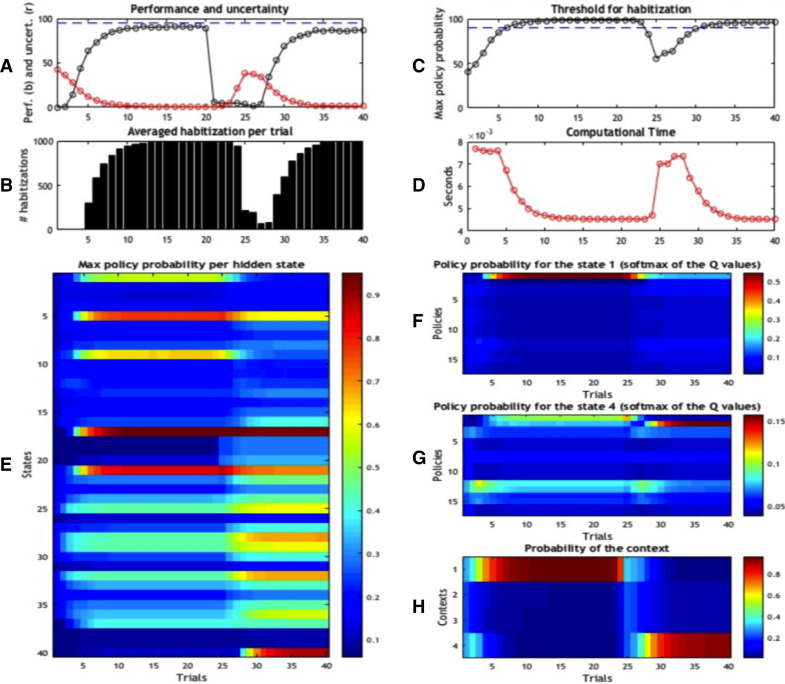
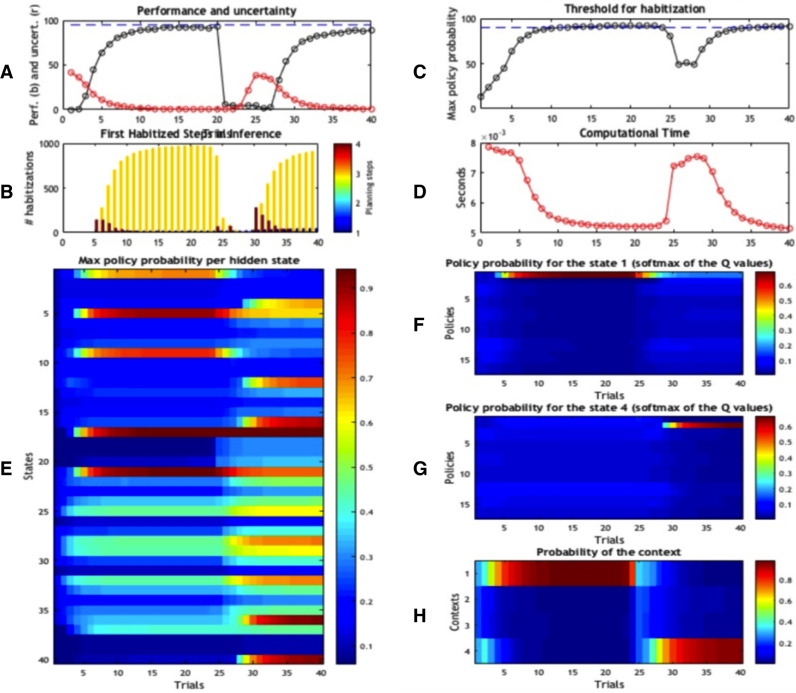
A popular distinction in the human and animal learning literature is between deliberate (or willed) and habitual (or automatic) modes of control. Extensive evidence indicates that, after sufficient learning, living organisms develop behavioural habits that permit them saving computational resources. Furthermore, humans and other animals are able to transfer control from deliberate to habitual modes (and vice versa), trading off efficiently flexibility and parsimony - an ability that is currently unparalleled by artificial control systems. Here, we discuss a computational implementation of habit formation, and the transfer of control from deliberate to habitual modes (and vice versa) within Active Inference: a computational framework that merges aspects of cybernetic theory and of Bayesian inference. To model habit formation, we endow an Active Inference agent with a mechanism to "cache" (or memorize) policy probabilities from previous trials, and reuse them to skip - in part or in full - the inferential steps of deliberative processing. We exploit the fact that the relative quality of policies, conditioned upon hidden states, is constant over trials; provided that contingencies and prior preferences do not change. This means the only quantity that can change policy selection is the prior distribution over the initial state - where this prior is based upon the posterior beliefs from previous trials. Thus, an agent that caches the quality (or the probability) of policies can safely reuse cached values to save on cognitive and computational resources - unless contingencies change. Our simulations illustrate the computational benefits, but also the limits, of three caching schemes under Active Inference. They suggest that key aspects of habitual behaviour - such as perseveration - can be explained in terms of caching policy probabilities. Furthermore, they suggest that there may be many kinds (or stages) of habitual behaviour, each associated with a different caching scheme; for example, caching associated or not associated with contextual estimation. These schemes are more or less impervious to contextual and contingency changes.
在人类和动物学习文献中,一个常见的区别在于刻意(或有意志的)和习惯性(或自动的)控制模式。大量证据表明,经过充分学习后,生物体形成行为习惯,从而节省计算资源。此外,人类和其他动物能够将控制权从刻意模式转移到习惯模式(反之亦然),有效地权衡灵活性和简约性——这是目前人工控制系统无法比拟的能力。在此,我们讨论习惯形成的计算实现,以及在主动推理中从刻意模式到习惯模式(反之亦然)的控制权转移:这是一个融合控制论和贝叶斯推理各方面的计算框架。为了模拟习惯形成,我们赋予主动推理智能体一种机制,用于“缓存”(或记忆)先前试验中的策略概率,并重新使用它们部分或全部跳过刻意处理的推理步骤。我们利用这样一个事实,即在隐藏状态条件下,策略的相对质量在各次试验中是恒定的;前提是意外情况和先验偏好不变。这意味着唯一能改变策略选择的量是初始状态上的先验分布——这里的先验基于先前试验的后验信念。因此,一个缓存策略质量(或概率)的智能体可以安全地重新使用缓存值以节省认知和计算资源——除非意外情况发生变化。我们的模拟展示了主动推理下三种缓存方案的计算优势,但也展示了其局限性。它们表明习惯性行为的关键方面——比如固执——可以用缓存策略概率来解释。此外,它们表明可能存在多种(或阶段)习惯性行为,每种行为都与不同的缓存方案相关联;例如,与上下文估计相关或不相关的缓存。这些方案或多或少不受上下文和意外情况变化的影响。