Chen Anthony G, Benrimoh David, Parr Thomas, Friston Karl J
Department of Physiology, McGill University, Montreal, QC, Canada.
Department of Psychiatry, McGill University, Montreal, QC, Canada.
Front Artif Intell. 2020 Sep 3;3:69. doi: 10.3389/frai.2020.00069. eCollection 2020.
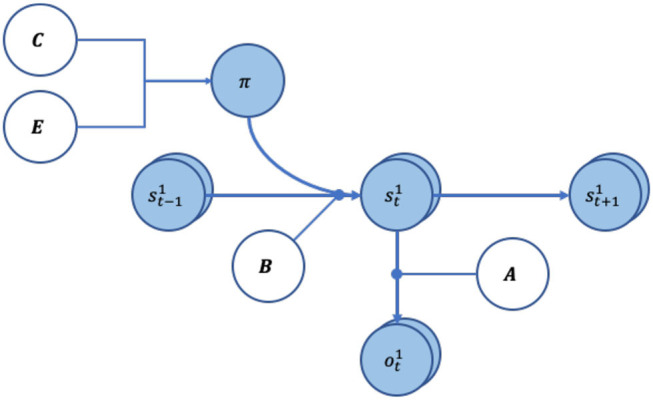
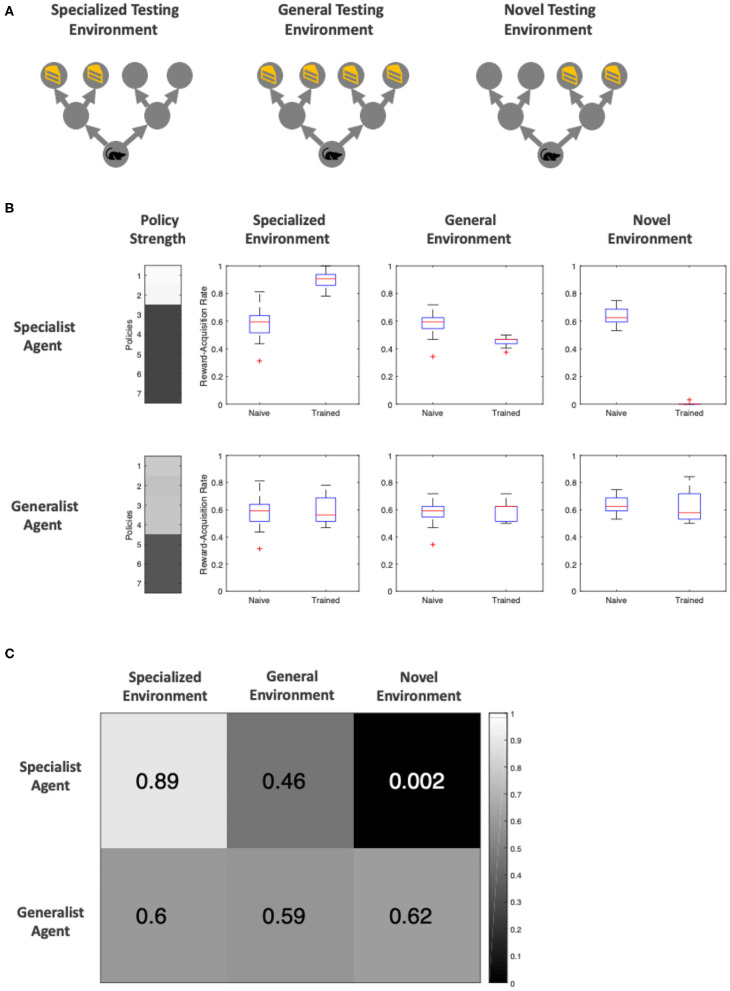
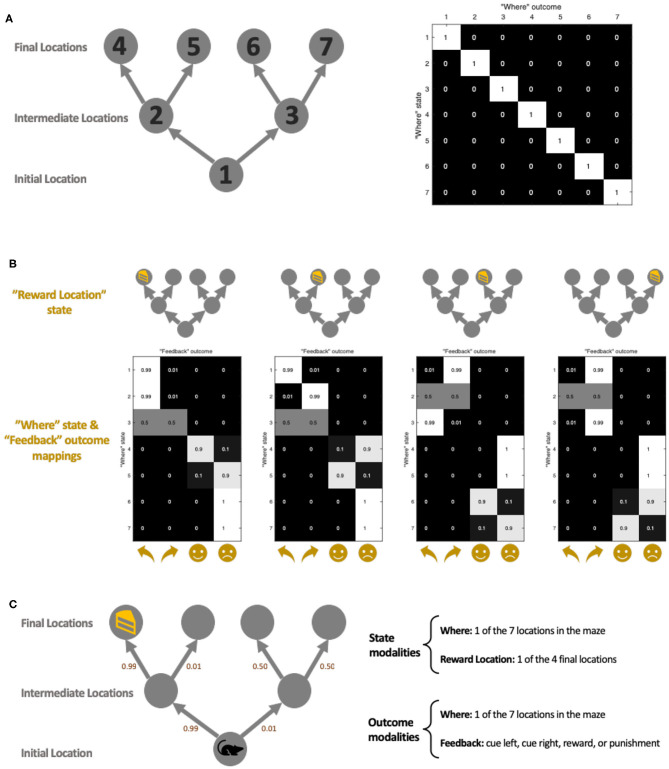
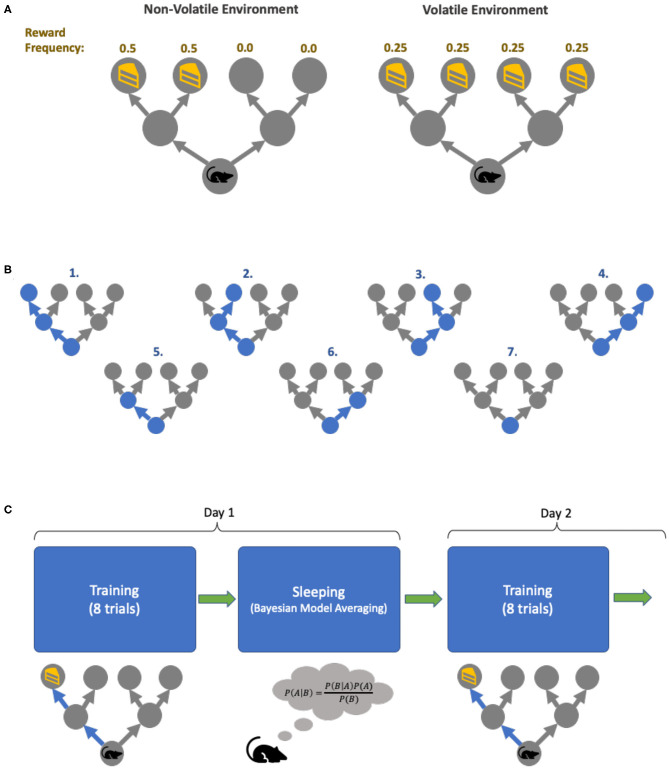
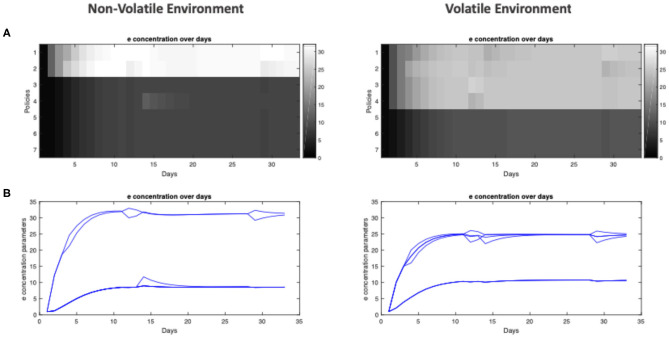
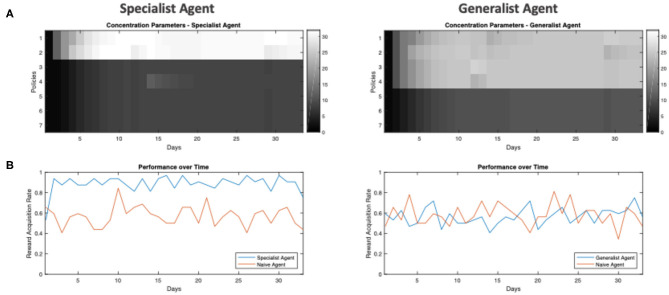
This paper offers a formal account of policy learning, or habitual behavioral optimization, under the framework of Active Inference. In this setting, habit formation becomes an autodidactic, experience-dependent process, based upon what the agent sees itself doing. We focus on the effect of environmental volatility on habit formation by simulating artificial agents operating in a partially observable Markov decision process. Specifically, we used a "two-step" maze paradigm, in which the agent has to decide whether to go left or right to secure a reward. We observe that in volatile environments with numerous reward locations, the agents learn to adopt a generalist strategy, never forming a strong habitual behavior for any preferred maze direction. Conversely, in conservative or static environments, agents adopt a specialist strategy; forming strong preferences for policies that result in approach to a small number of previously-observed reward locations. The pros and cons of the two strategies are tested and discussed. In general, specialization offers greater benefits, but only when contingencies are conserved over time. We consider the implications of this formal (Active Inference) account of policy learning for understanding the relationship between specialization and habit formation.
本文在主动推理框架下,对政策学习或习惯性行为优化进行了形式化阐述。在这种情况下,习惯形成成为一个基于主体自身行为观察的自我学习、依赖经验的过程。我们通过模拟在部分可观测马尔可夫决策过程中运行的人工主体,来关注环境波动性对习惯形成的影响。具体而言,我们使用了“两步”迷宫范式,其中主体必须决定向左还是向右以获得奖励。我们观察到,在具有众多奖励位置的波动环境中,主体学会采用通才策略,不会为任何偏好的迷宫方向形成强烈的习惯行为。相反,在保守或静态环境中,主体采用专才策略;对导致接近少数先前观察到的奖励位置的策略形成强烈偏好。我们对这两种策略的优缺点进行了测试和讨论。一般来说,专业化带来更大的好处,但前提是偶然性随时间保持不变。我们考虑了这种政策学习的形式化(主动推理)阐述对于理解专业化与习惯形成之间关系的意义。