From the Department of Radiology, Stanford University School of Medicine, 300 Pasteur Dr, S-072, Stanford, CA 94305-5105 (M.J.W., D.F., D.L.R., M.P.L.); Segmed, Menlo Park, Calif (M.J.W., W.A.K., C.H., J.W.); School of Engineering, Stanford University, Stanford, Calif (J.W.); Institute of Cognitive Neuroscience, University College London, London, England (H.H.); Radiology and Imaging Sciences, National Institutes of Health Clinical Center, Bethesda, Md (L.R.F.); Imaging Biomarkers and Computer-Aided Diagnosis Laboratory, National Institutes of Health, Clinical Center, Bethesda, Md (R.M.S.); Department of Biomedical Data Science, Stanford University School of Medicine, Stanford, Calif (D.L.R.); and Stanford Center for Artificial Intelligence in Medicine and Imaging (AIMI), Stanford, Calif (M.P.L.).
Radiology. 2020 Apr;295(1):4-15. doi: 10.1148/radiol.2020192224. Epub 2020 Feb 18.
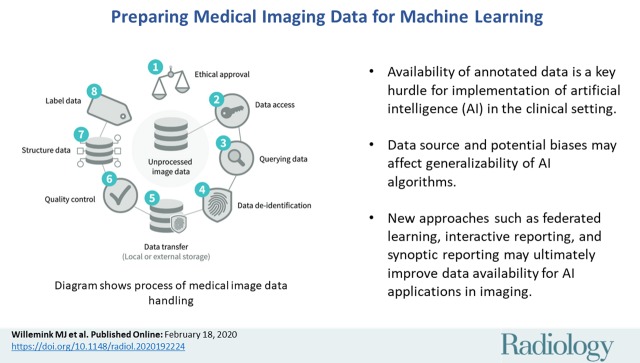
Artificial intelligence (AI) continues to garner substantial interest in medical imaging. The potential applications are vast and include the entirety of the medical imaging life cycle from image creation to diagnosis to outcome prediction. The chief obstacles to development and clinical implementation of AI algorithms include availability of sufficiently large, curated, and representative training data that includes expert labeling (eg, annotations). Current supervised AI methods require a curation process for data to optimally train, validate, and test algorithms. Currently, most research groups and industry have limited data access based on small sample sizes from small geographic areas. In addition, the preparation of data is a costly and time-intensive process, the results of which are algorithms with limited utility and poor generalization. In this article, the authors describe fundamental steps for preparing medical imaging data in AI algorithm development, explain current limitations to data curation, and explore new approaches to address the problem of data availability.
人工智能(AI)在医学影像领域继续引起广泛关注。其潜在应用非常广泛,涵盖了从图像创建到诊断再到结果预测的整个医学影像生命周期。开发和临床实施 AI 算法的主要障碍包括是否有足够大、经过精心整理且具有代表性的训练数据,其中包括专家标记(例如,注释)。当前的监督 AI 方法需要对数据进行整理,以便对算法进行最佳的训练、验证和测试。目前,大多数研究小组和行业基于小地理区域的小样本量,数据访问受到限制。此外,数据准备是一个昂贵且耗时的过程,其结果是算法的实用性有限,泛化能力较差。在本文中,作者描述了在 AI 算法开发中准备医学影像数据的基本步骤,解释了数据整理的当前限制,并探讨了解决数据可用性问题的新方法。