Shin Hyun Kil, Kang Myung-Gyun, Park Daeui, Park Tamina, Yoon Seokjoo
Toxicoinformatics Group, Department of Predictive Toxicology, Korea Institute of Toxicology, Daejeon, South Korea.
Department of Human and Environmental Toxicology, University of Science and Technology, Daejeon, South Korea.
Front Pharmacol. 2020 Feb 14;11:67. doi: 10.3389/fphar.2020.00067. eCollection 2020.
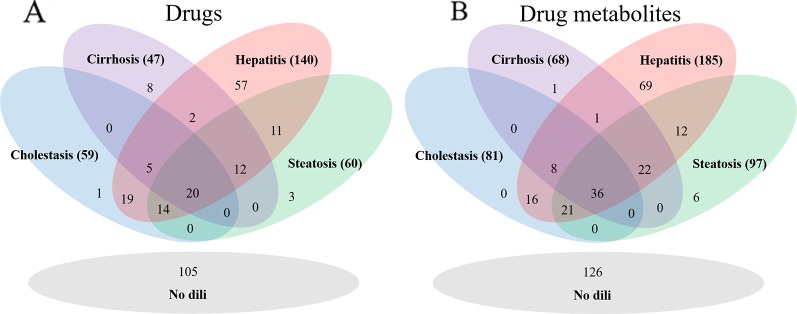
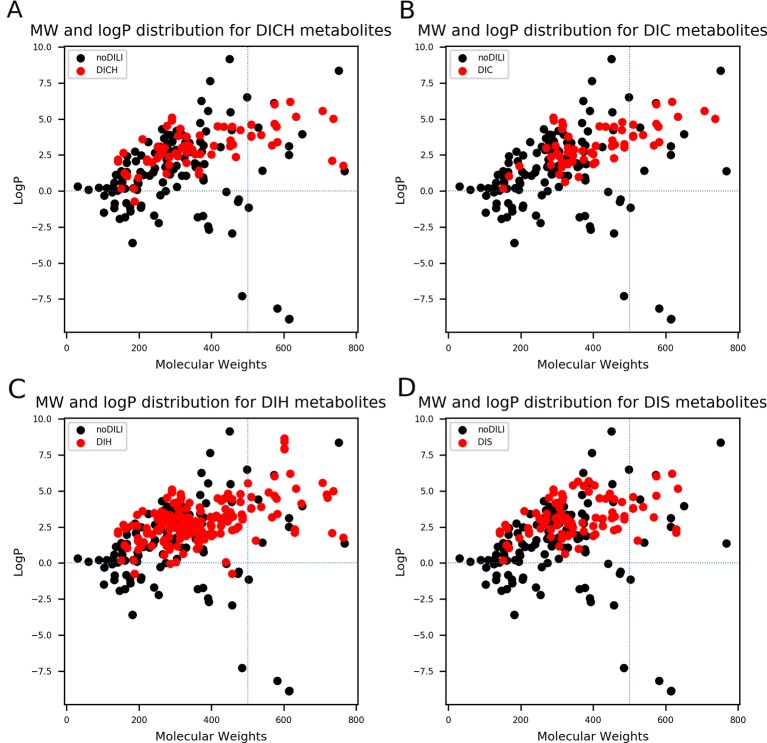
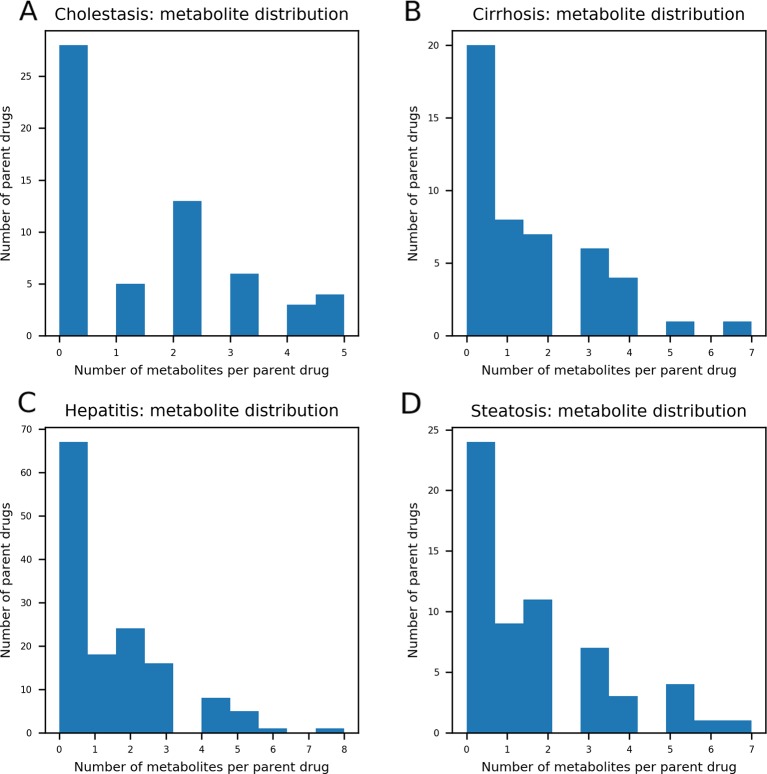
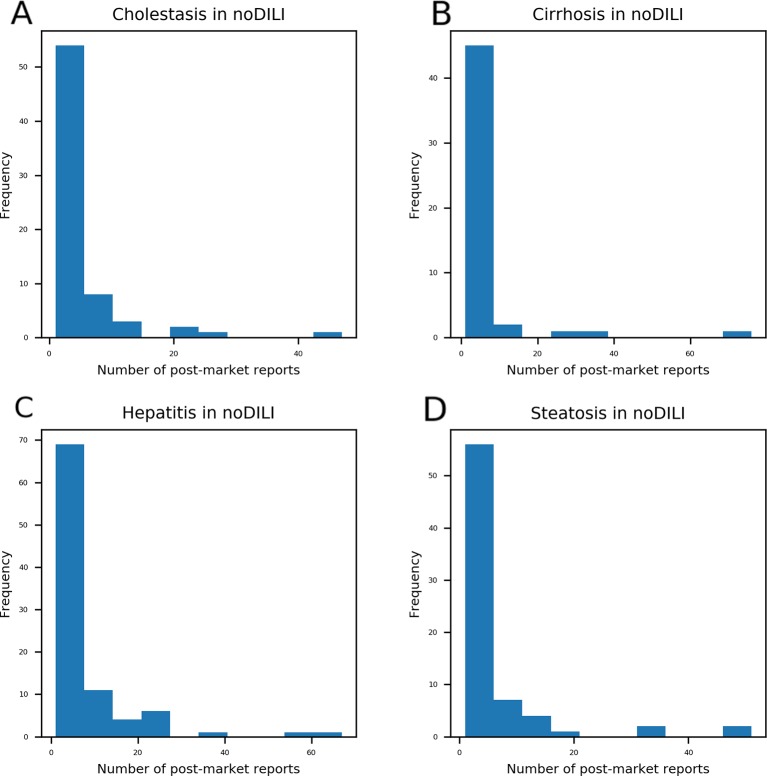
Drug-induced liver injury (DILI) is one of the major reasons for termination of drug development. Due to the importance of predicting DILI in early phases of drug development, diverse models have been developed to filter out DILI-causing candidates before clinical study. However, no computational models have achieved sufficient prediction power for screening DILI in early phases because 1) drugs often cause liver injury through reactive metabolites, 2) different clinical outcomes of DILI have different mechanisms, and 3) the DILI label on drugs is not clearly defined. In this study, we developed binary classification models to predict drug-induced cholestasis, cirrhosis, hepatitis, and steatosis based on the structure of drugs and their metabolites. DILI-positive data was obtained from post-market reports of drugs and DILI-negative data from DILIrank, a database curated by the Food and Drug Administration (FDA). Support vector machine (SVM) and random forest (RF) were used in developing models with nine fingerprints and one 2D molecular descriptor calculated from drug (152 DILI-positives and 102 DILI-negatives) and drug metabolite (192 DILI-positives and 126 DILI-negatives) structures. Models were developed according to Organisation for Economic Co-operation and Development (OECD) guidelines for quantitative structure-activity relationship (QSAR) validation. Internal and external validation was performed with a randomization test in order to thoroughly examine model predictability and avoid random correlation between structural features and adverse outcomes. The applicability domain was defined with a leverage method for reliable prediction of new chemicals. The best models for each liver disease were selected based on external validation results from drugs (cholestasis: 70%, cirrhosis: 90%, hepatitis: 83%, and steatosis: 85%) and drug metabolites (cholestasis: 86%, cirrhosis: 88%, hepatitis: 86%, and steatosis: 83%) with applicability domain analysis. Compiled data sets were further exploited to derive privileged substructures that were more frequent in DILI-positive sets compared to DILI-negative sets and in drug metabolite structures compared to drug structures with a Morgan fingerprint level 2.
药物性肝损伤(DILI)是导致药物研发终止的主要原因之一。鉴于在药物研发早期预测DILI的重要性,人们已开发出多种模型,以便在临床研究前筛选出可能导致DILI的候选药物。然而,尚无计算模型在早期阶段对DILI筛查具备足够的预测能力,原因如下:1)药物常通过反应性代谢物导致肝损伤;2)DILI的不同临床结果有不同机制;3)药物上的DILI标签定义不明确。在本研究中,我们基于药物及其代谢物的结构开发了二元分类模型,以预测药物性胆汁淤积、肝硬化、肝炎和脂肪变性。DILI阳性数据来自药物上市后报告,DILI阴性数据来自美国食品药品监督管理局(FDA)管理的DILIrank数据库。支持向量机(SVM)和随机森林(RF)用于开发模型,模型使用从药物(152个DILI阳性和102个DILI阴性)和药物代谢物(192个DILI阳性和126个DILI阴性)结构计算得出的九种指纹和一种二维分子描述符。模型按照经济合作与发展组织(OECD)定量构效关系(QSAR)验证指南开发。通过随机化测试进行内部和外部验证,以全面检验模型的预测能力,并避免结构特征与不良结果之间的随机相关性。使用杠杆法定义适用域,以可靠预测新化学物质。根据药物(胆汁淤积:70%,肝硬化:90%,肝炎:83%,脂肪变性:85%)和药物代谢物(胆汁淤积:86%,肝硬化:88%,肝炎:86%,脂肪变性:83%)的外部验证结果及适用域分析,为每种肝病选择最佳模型。对汇编的数据集进一步进行分析,以得出特权子结构,这些子结构在DILI阳性组中比在DILI阴性组中更常见,在药物代谢物结构中比在具有摩根指纹2级的药物结构中更常见。