Kumar Vinod, Kumar Rajesh, Agrawal Piyush, Patiyal Sumeet, Raghava Gajendra P S
Department of Computational Biology, Indraprastha Institute of Information Technology, Okhla, India.
Bioinformatics Centre, CSIR-Institute of Microbial Technology, Chandigarh, India.
Front Pharmacol. 2020 Feb 20;11:54. doi: 10.3389/fphar.2020.00054. eCollection 2020.
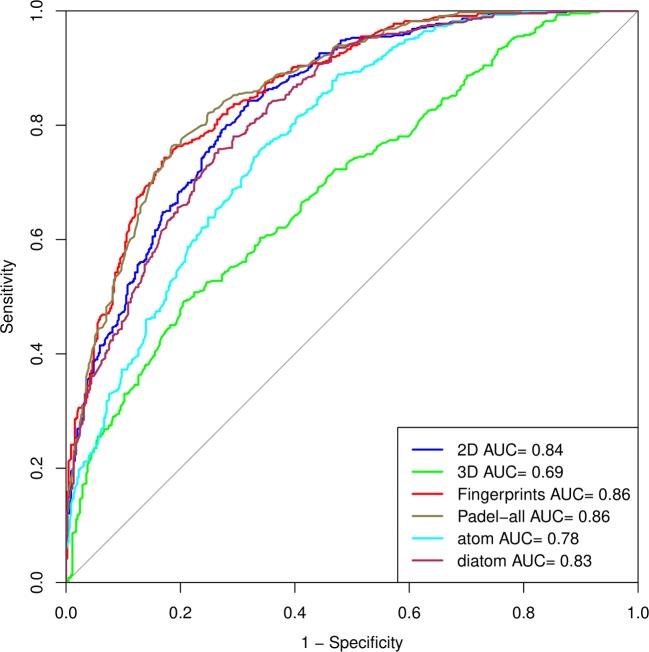
In the present study, a systematic effort has been made to predict the hemolytic potency of chemically modified peptides. All models have been trained, tested, and evaluated on a dataset that contains 583 modified hemolytic peptides and a balanced number of non-hemolytic peptides. Machine learning techniques have been used to build the classification models using an immense range of peptide features that include 2D, 3D descriptors, fingerprints, atom, and diatom compositions. Random Forest based model developed using fingerprints as an input feature achieved maximum accuracy of 78.33% with AUC of 0.86 on the main dataset and accuracy of 78.29% with AUC of 0.85 on the validation dataset. Models developed in this study have been incorporated in a web server "HemoPImod" to facilitate the scientific community (http://webs.iiitd.edu.in/raghava/hemopimod/).
在本研究中,已做出系统努力来预测化学修饰肽的溶血效力。所有模型均在一个包含583种修饰溶血肽和数量均衡的非溶血肽的数据集上进行了训练、测试和评估。机器学习技术已被用于利用大量肽特征构建分类模型,这些特征包括二维、三维描述符、指纹、原子和双原子组成。使用指纹作为输入特征开发的基于随机森林的模型在主数据集上的最大准确率为78.33%,曲线下面积(AUC)为0.86,在验证数据集上的准确率为78.29%,AUC为0.85。本研究中开发的模型已被整合到一个网络服务器“HemoPImod”中,以方便科学界使用(http://webs.iiitd.edu.in/raghava/hemopimod/)。