Gao Junfeng, French Andrew P, Pound Michael P, He Yong, Pridmore Tony P, Pieters Jan G
1Lincoln Institute for Agri-food Technology, University of Lincoln, Lincoln, Riseholme Park, LN2 2LG UK.
2Department of Biosystems Engineering, Ghent University, Coupure Links 653, 9000 Ghent, Belgium.
Plant Methods. 2020 Mar 5;16:29. doi: 10.1186/s13007-020-00570-z. eCollection 2020.
(hedge bindweed) detection in sugar beet fields remains a challenging problem due to variation in appearance of plants, illumination changes, foliage occlusions, and different growth stages under field conditions. Current approaches for weed and crop recognition, segmentation and detection rely predominantly on conventional machine-learning techniques that require a large set of hand-crafted features for modelling. These might fail to generalize over different fields and environments.
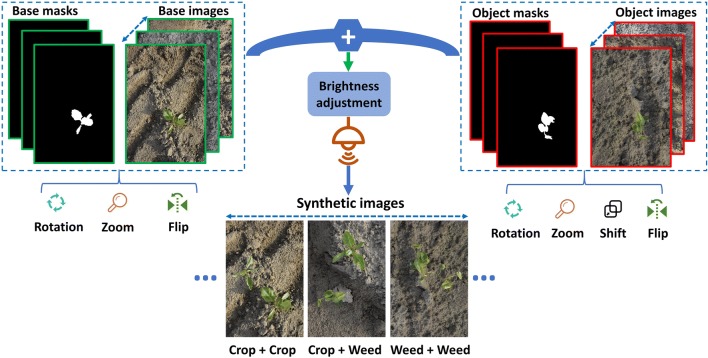
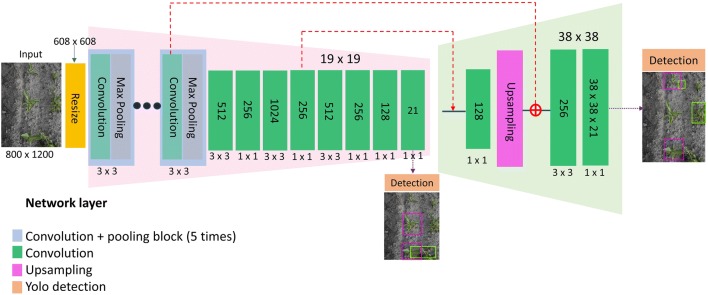
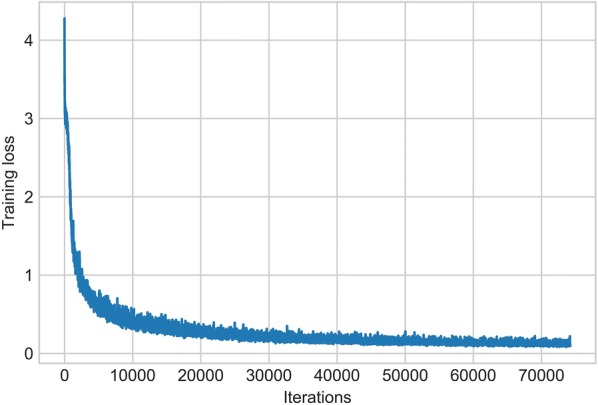
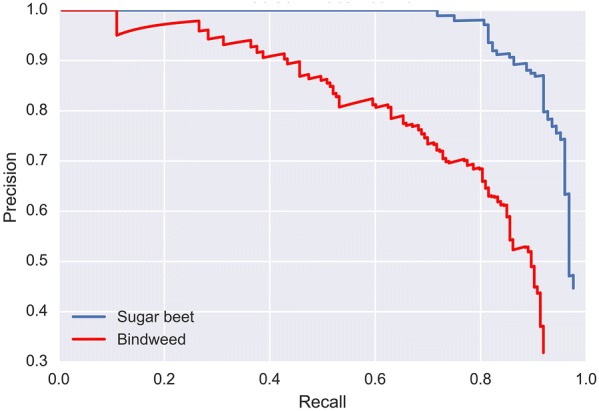
Here, we present an approach that develops a deep convolutional neural network (CNN) based on the tiny YOLOv3 architecture for and sugar beet detection. We generated 2271 synthetic images, before combining these images with 452 field images to train the developed model. YOLO anchor box sizes were calculated from the training dataset using a k-means clustering approach. The resulting model was tested on 100 field images, showing that the combination of synthetic and original field images to train the developed model could improve the mean average precision (mAP) metric from 0.751 to 0.829 compared to using collected field images alone. We also compared the performance of the developed model with the YOLOv3 and Tiny YOLO models. The developed model achieved a better trade-off between accuracy and speed. Specifically, the average precisions (APs@IoU0.5) of and sugar beet were 0.761 and 0.897 respectively with 6.48 ms inference time per image (800 × 1200) on a NVIDIA Titan X GPU environment.
The developed model has the potential to be deployed on an embedded mobile platform like the Jetson TX for online weed detection and management due to its high-speed inference. It is recommendable to use synthetic images and empirical field images together in training stage to improve the performance of models.
由于田间条件下植物外观的变化、光照变化、叶片遮挡以及不同的生长阶段,在甜菜田中检测(篱打碗花)仍然是一个具有挑战性的问题。当前用于杂草和作物识别、分割及检测的方法主要依赖传统机器学习技术,这些技术需要大量手工制作的特征进行建模。这些方法可能无法在不同的田地和环境中通用。
在此,我们提出一种方法,基于微小YOLOv3架构开发一个用于 和甜菜检测的深度卷积神经网络(CNN)。我们生成了2271张合成图像,然后将这些图像与452张田间图像相结合来训练所开发的模型。使用k均值聚类方法从训练数据集中计算YOLO锚框大小。在100张田间图像上对所得模型进行测试,结果表明,与仅使用收集的田间图像相比,将合成图像和原始田间图像相结合来训练所开发的模型可以将平均精度均值(mAP)指标从0.751提高到0.829。我们还将所开发模型的性能与YOLOv3和微小YOLO模型进行了比较。所开发的模型在准确性和速度之间实现了更好的平衡。具体而言,在NVIDIA Titan X GPU环境下,每张图像(800×1200)推理时间为6.48毫秒时, 和甜菜的平均精度(APs@IoU0.5)分别为0.761和0.897。
所开发的模型由于其高速推理,有潜力部署在如Jetson TX这样的嵌入式移动平台上用于在线杂草检测和管理。建议在训练阶段同时使用合成图像和实际田间图像以提高模型性能。