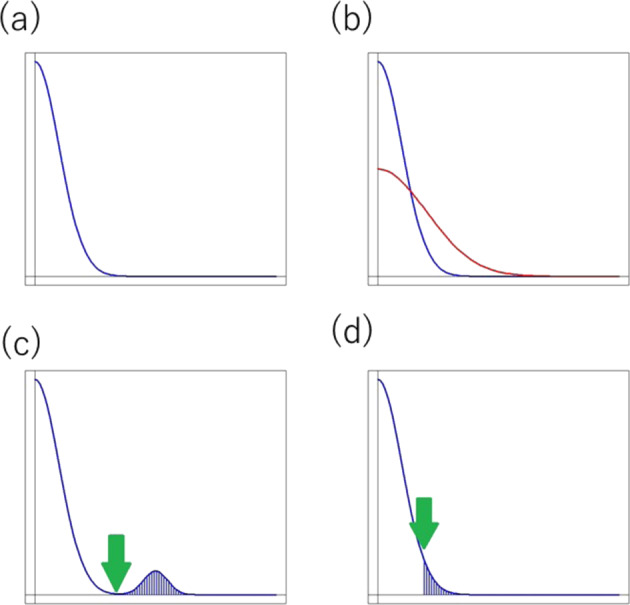
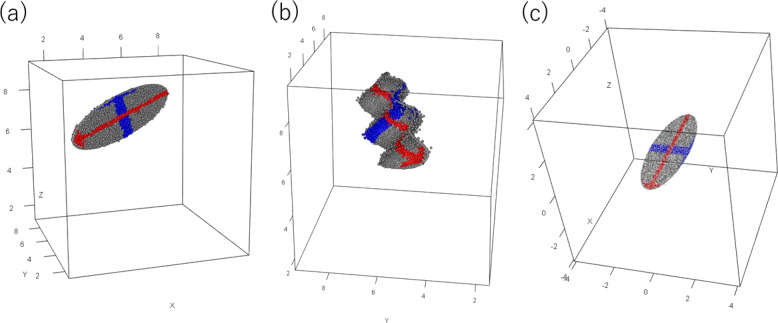
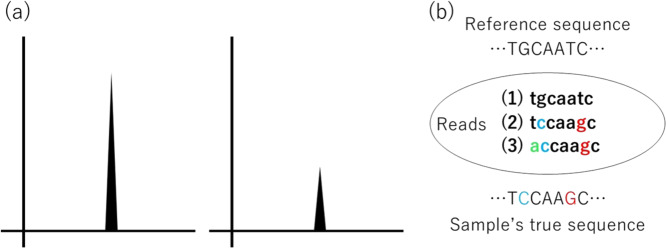
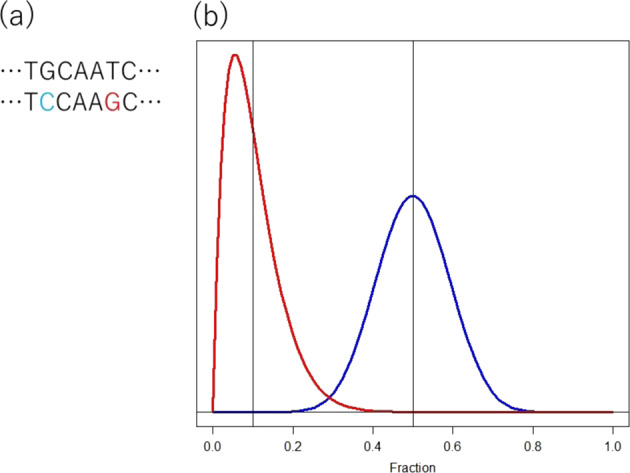
Unit of Statistical Genetics, Center for Genomic Medicine, Graduate School of Medicine, Kyoto University, Nanbusogo-Kenkyu-To-1, 5F, 53 Syogoin-Kawaramachi, Sakyo-ku, Kyoto, 606-8507, Japan.
J Hum Genet. 2021 Jan;66(1):93-102. doi: 10.1038/s10038-020-0763-5. Epub 2020 May 8.
Omics studies attempt to extract meaningful messages from large-scale and high-dimensional data sets by treating the data sets as a whole. The concept of treating data sets as a whole is important in every step of the data-handling procedures: the pre-processing step of data records, the step of statistical analyses and machine learning, translation of the outputs into human natural perceptions, and acceptance of the messages with uncertainty. In the pre-processing, the method by which to control the data quality and batch effects are discussed. For the main analyses, the approaches are divided into two types and their basic concepts are discussed. The first type is the evaluation of many items individually, followed by interpretation of individual items in the context of multiple testing and combination. The second type is the extraction of fewer important aspects from the whole data records. The outputs of the main analyses are translated into natural languages with techniques, such as annotation and ontology. The other technique for making the outputs perceptible is visualization. At the end of this review, one of the most important issues in the interpretation of omics data analyses is discussed. Omics studies have a large amount of information in their data sets, and every approach reveals only a very restricted aspect of the whole data sets. The understandable messages from these studies have unavoidable uncertainty.
组学研究试图通过将数据集作为一个整体来从大规模和高维数据集提取有意义的信息。将数据集作为一个整体来处理的概念在数据处理过程的每一个步骤中都很重要:数据记录的预处理步骤、统计分析和机器学习的步骤、将输出转化为人类自然感知的步骤,以及接受不确定信息的步骤。在预处理中,讨论了控制数据质量和批次效应的方法。对于主要分析,方法分为两类,并讨论了它们的基本概念。第一种方法是单独评估许多项目,然后在多次测试和组合的背景下解释单个项目。第二种方法是从整个数据记录中提取较少的重要方面。主要分析的输出通过注释和本体等技术转化为自然语言。使输出可感知的另一种技术是可视化。在本综述的最后,讨论了组学数据分析解释中的一个最重要问题。组学研究在其数据集中有大量信息,每种方法只揭示了整个数据集的一个非常有限的方面。这些研究中可理解的信息不可避免地存在不确定性。