Patel Sandip Kumar, George Bhawana, Rai Vineeta
Department of Biosciences and Bioengineering, Indian Institute of Technology Bombay, Mumbai, India.
Buck Institute for Research on Aging, Novato, CA, United States.
Front Pharmacol. 2020 Aug 12;11:1177. doi: 10.3389/fphar.2020.01177. eCollection 2020.
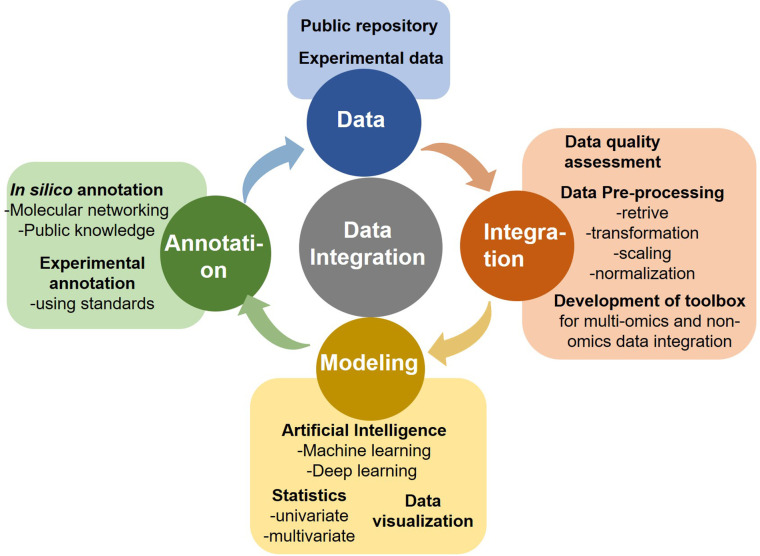
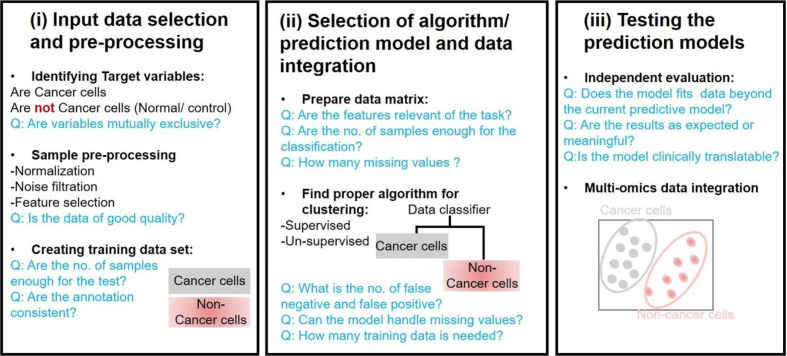
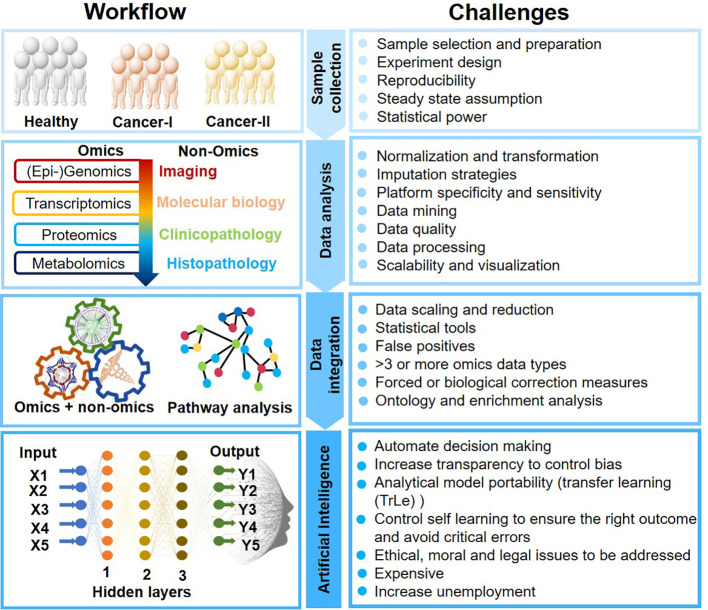
The multitude of multi-omics data generated cost-effectively using advanced high-throughput technologies has imposed challenging domain for research in Artificial Intelligence (AI). Data curation poses a significant challenge as different parameters, instruments, and sample preparations approaches are employed for generating these big data sets. AI could reduce the fuzziness and randomness in data handling and build a platform for the data ecosystem, and thus serve as the primary choice for data mining and big data analysis to make informed decisions. However, AI implication remains intricate for researchers/clinicians lacking specific training in computational tools and informatics. Cancer is a major cause of death worldwide, accounting for an estimated 9.6 million deaths in 2018. Certain cancers, such as pancreatic and gastric cancers, are detected only after they have reached their advanced stages with frequent relapses. Cancer is one of the most complex diseases affecting a range of organs with diverse disease progression mechanisms and the effectors ranging from gene-epigenetics to a wide array of metabolites. Hence a comprehensive study, including genomics, epi-genomics, transcriptomics, proteomics, and metabolomics, along with the medical/mass-spectrometry imaging, patient clinical history, treatments provided, genetics, and disease endemicity, is essential. Cancer Moonshot℠ Research Initiatives by NIH National Cancer Institute aims to collect as much information as possible from different regions of the world and make a cancer data repository. AI could play an immense role in (a) analysis of complex and heterogeneous data sets (multi-omics and/or inter-omics), (b) data integration to provide a holistic disease molecular mechanism, (c) identification of diagnostic and prognostic markers, and (d) monitor patient's response to drugs/treatments and recovery. AI enables precision disease management well beyond the prevalent disease stratification patterns, such as differential expression and supervised classification. This review highlights critical advances and challenges in omics data analysis, dealing with data variability from lab-to-lab, and data integration. We also describe methods used in data mining and AI methods to obtain robust results for precision medicine from "big" data. In the future, AI could be expanded to achieve ground-breaking progress in disease management.
利用先进的高通量技术经济高效地生成的大量多组学数据,给人工智能(AI)研究带来了具有挑战性的领域。数据管理构成了重大挑战,因为生成这些大数据集采用了不同的参数、仪器和样本制备方法。人工智能可以减少数据处理中的模糊性和随机性,并为数据生态系统构建一个平台,从而成为数据挖掘和大数据分析以做出明智决策的首要选择。然而,对于缺乏计算工具和信息学方面特定培训的研究人员/临床医生来说,人工智能的应用仍然错综复杂。癌症是全球主要的死亡原因之一,2018年估计有960万人死亡。某些癌症,如胰腺癌和胃癌,只有在发展到晚期且频繁复发后才被发现。癌症是影响一系列器官的最复杂疾病之一,具有多种疾病进展机制,其影响因素从基因表观遗传学到各种各样的代谢物。因此,包括基因组学、表观基因组学、转录组学、蛋白质组学和代谢组学,以及医学/质谱成像、患者临床病史、提供的治疗、遗传学和疾病流行情况在内的全面研究至关重要。美国国立卫生研究院国家癌症研究所的癌症“登月计划”研究倡议旨在从世界不同地区收集尽可能多的信息,并建立一个癌症数据库。人工智能可以在以下方面发挥巨大作用:(a)分析复杂和异质数据集(多组学和/或组学间),(b)数据整合以提供整体疾病分子机制,(c)识别诊断和预后标志物,以及(d)监测患者对药物/治疗的反应和恢复情况。人工智能能够实现远超普遍疾病分层模式(如差异表达和监督分类)的精准疾病管理。本综述强调了组学数据分析、应对实验室间数据变异性以及数据整合方面的关键进展和挑战。我们还描述了用于数据挖掘的方法和人工智能方法,以便从“大”数据中获得用于精准医学的可靠结果。未来,人工智能可以得到扩展,从而在疾病管理方面取得突破性进展。